Python从文件中读取数据的方法步骤
一、读取整个文件内容
在读取文件之前,我们先创建一个文本文件resource.txt作为源文件。
resource.txt
my name is joker, I am 18 years old, How about you?
如何读取文件全部内容,我们编写到reader.py文件中。
reader.py
with open('resource.txt') as file_obj:
content = file_obj.read()
print(content)
需要注意的是需要将resource.txt文件与read.py 放在同一目录下。
运行后的结果如下:

解释:open函数接收一个参数,此参数为将被读取内容的文件名,在调用之后返回表示这个文件的对象,Python将之存储在后面的变量(file_obj)中,关键字 with 在我们不再需要使用文件的时候将其关闭。
上面的代码中open() 函数中传入的是一个相对路径,相对路径会从当前文件(reader.py)所在文件夹下查找指定文件(resource.txt),如果文件不在当前文件夹下,可以使用绝对路径。Linux系统绝对路径如:
/home/joker/dic这样的,Windows系统的绝对路径如:C:/pyhton_workspace/dic 这样的。
二、逐行读取文件内容
file_name = 'resource.txt'
with open(file_name) as file_obj:
for content in file_obj:
print(content)
控制台打印如下:
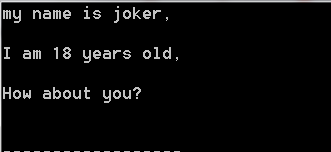
解释:在上面的程序中,因为Python在读取文件之后将其存入对象file_obj 中,我们通过对该对象进行循环来遍历文件中的每一行,但是却发现,多了空白行,因为在这个文件中,有看不见的换行符,且print语句语句也会加上一个换行符,因此每行的末尾会有两个换行符。要消除多于的空白行可在print语句中调用rstrip() 方法,如下:
file_name = 'resource.txt'
with open(file_name) as file_obj:
for content in file_obj:
print(content.rstrip())
控制台打印如下:
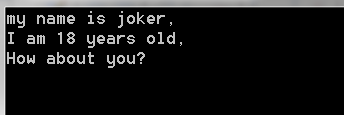
现在,和与读取整个文件的输出相同了。
到此这篇关于Python从文件中读取数据的方法步骤的文章就介绍到这了,更多相关Python 文件读取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python3:excel操作之读取数据并返回字典 + 写入的案例
excel写入数据,使用openpyxl库 class WriteExcel: def __init__(self,path): self.path = path def write_excel(self, sheet_name, content): """ 在excel指定sheet中的写入指定内容,以追加方式 :return: """ wb = openpyxl.load_workbook(self.path) ws = wb[sheet_n
-
Python随机函数random随机获取数字、字符串、列表等使用详解
在python中用于生成随机数的模块是random,在使用前需要import, 下面看下它的用法. Python随机生成一个浮点数 random.random random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 注意: 以下代码在Python3.5下测试通过, python2版本可稍加修改 描述 random() 方法返回随机生成的一个实数,它在(0,1)范围内. 语法 以下是 random() 方法的语法: import random random.ra
-
python从Oracle读取数据生成图表
初次学习python,连接Oracle数据库,导出数据到Excel,再从Excel里面读取数据进行绘图,生成png保存出来. 1.涉及到的python模块(模块安装就不进行解释了): import os import cx_Oracle import openpyxl import time import csv import xlrd from matplotlib import pyplot as plt from matplotlib import font_manager 2.连接数据库
-
python从PDF中提取数据的示例
01 前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸如"csv"之类的格式,以便用于分析或构建模型. 在本文中,我们将重点讨论如何从pdf文件中提取数据表.类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像.我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分
-
Python定时从Mysql提取数据存入Redis的实现
设计思路: 1.程序一旦run起来,python会把mysql中最近一段时间的数据全部提取出来 2.然后实例化redis类,将数据简单解析后逐条传入redis队列 3.定时器设计每天凌晨12点开始跑 ps:redis是个内存数据库,做后台消息队列的缓存时有很大的用处,有兴趣的小伙伴可以去查看相关的文档. # -*- coding:utf-8 -*- import MySQLdb import schedule import time import datetime import random i
-
python3实现从kafka获取数据,并解析为json格式,写入到mysql中
项目需求:将kafka解析来的日志获取到数据库的变更记录,按照订单的级别和订单明细级别写入数据库,一条订单的所有信息包括各种维度信息均保存在一条json中,写入mysql5.7中. 配置信息: [Global] kafka_server=xxxxxxxxxxx:9092 kafka_topic=mes consumer_group=test100 passwd = tracking port = 3306 host = xxxxxxxxxx user = track schema = track
-

Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
Python实现一个自助取数查询工具
基于底层数据来开发不难,无非是将用户输入变量作为筛选条件,将参数映射到 sql 语句,并生成一个 sql 语句然后再去数据库执行 最后再利用 QT 开发一个 GUI 界面,用户界面的点击和筛选条件,信号触发对应按钮与绑定的传参槽函数执行 具体思路: 一.数据库连接类 此处利用 pandas 读写操作 oracle 数据库 二.主函数模块 1)输入参数模块,外部输入条件参数,建立数据库关键字段映射 --注:读取外部 txt 文件,将筛选字段可能需要进行键值对转换 2)sql 语句集合模块,将待执行
-
Python 循环读取数据内存不足的解决方案
看代码吧~ import gc for x in list(locals().keys())[:]: del locals()[x] # del all_s_x, AE, AE_split, x_ticks, split gc.collect() 补充:Python读取大文件的"坑"与内存占用检测 python读写文件的api都很简单,一不留神就容易踩"坑".笔者记录一次踩坑历程,并且给了一些总结,希望到大家在使用python的过程之中,能够避免一些可能产生隐患的代
-
使用Python脚本从文件读取数据代码实例
这篇文章主要介绍了使用Python脚本从文件读取数据代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 最近自学Python的进度比较慢,工作之余断断续续的看着效率比较低,看来还是要狠下心来每天进步一点点. 还记得前段时间陈大猫提了一口"先实现用python读取本地文件",碰巧今天看到文件与异常,结合练习整理下用Python读取本地文件的代码: import os #从标准库导入os模块 os.chdir('F:\HeadFirs
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum