为什么代码规范要求SQL语句不要过多的join
送分题
面试官:有操作过Linux吗?
我:有的呀
面试官:我想查看内存的使用情况该用什么命令
我:free 或者 top
面试官:那你说一下用free命令都可以看到啥信息
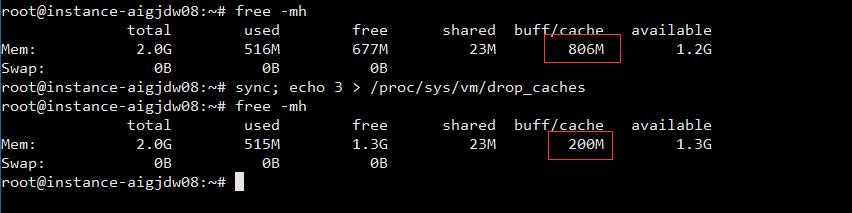
我:那,如下图所示 可以看到内存以及缓存的使用情况
- total 总内存
- used 已用内存
- free 空闲内存
- buff/cache 已使用的缓存
- avaiable 可用内存

面试官:那你知道怎么清理已使用的缓存吗(buff/cache)
我:em… 不知道
面试官:sync; echo 3 > /proc/sys/vm/drop_caches就可以清理buff/cache了,你说说我在线上执行这条命令做好不好?
我:(送分题,内心大喜)好处大大的有,清理出缓存我们就有更多可用的内存空间, 就跟pc上面xx卫士的小火箭一样,点一下,就释放出好多的内存
面试官:em…, 回去等通知吧
再谈SQL Join
面试官:换个话题,谈谈你对join的理解
我: 好的(再答错就彻底完了,把握住机会)
回顾
SQL中的join可以根据某些条件把指定的表给结合起来并将数据返回给客户端
join的方式有
inner join 内连接

left join 左连接

right join 右连接

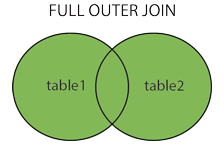
full join 全连接
面试官:在项目开发中如果需要使用join语句,如何优化提升性能?
我: 分为两种情况,数据规模小的,数据规模大的。
面试官: 然后?
我:对于
- 数据规模较小 全部干进内存就完事了嗷
- 数据规模较大
可以通过增加索引来优化
join语句的执行速度 可以通过冗余信息来减少join的次数 尽量减少表连接的次数,一个SQL语句表连接的次数不要超过5次
面试官:可以总结为join语句是相对比较耗费性能,对吗?
我:是的
面试官: 为什么?
缓冲区
我: 在执行join语句的时候必然要有一个比较的过程
面试官: 是的
我:逐条比较两个表的语句是比较慢的,因此我们可以把两个表中数据依次读进一个内存块中, 以MySQL的InnoDB引擎为例,使用以下语句我们必然可以查到相关的内存区域show variables like '%buffer%'

如下图所示join_buffer_size的大小将会影响我们join语句的执行性能
面试官: 除此之外呢?
一个大前提
我:任何项目终究要上线,不可避免的要产生数据,数据的规模又不可能太小
面试官: 是这样的
我:大部分数据库中的数据最终要保存到硬盘上,并且以文件的形式进行存储。
以MySQL的InnoDB引擎为例
- InnoDB以
页(page)为基本的IO单位,每个页的大小为16KB - InnoDB会为每个表创建用于存储数据的
.ibd文件
验证

我:这意味着我们有多少表要连接就需要读多少个文件,虽然可以利用索引,但还是免不了频繁的移动硬盘的磁头
面试官:也就是说频繁的移动磁头会影响性能对吧
我:是的,现在的开源框架不都喜欢说自己通过顺序读写大大的提升了性能吗,比如hbase、kafka
面试官:说的没错,那你认为Linux有对此做出优化吗?提示,你可以再执行一次free命令看一下
我:奇怪缓存怎么占用了1.2G多


面试官: 你有没有想过
buff/cache里面存的是什么,?- 为什么
buff/cache占了那么多内存,可用内存即availlable还有1.1G? - 为什么你可以通过两条命令来清理
buff/cache占用的内存,而想要释放used只能通过结束进程来实现?
品,你细品
思考了几分钟后

我:这么随便就释放了buff/cache所占用的内存,说明它就不重要, 清除它不会对系统的运行造成影响
面试官: 不完全对
我:难道是?想起来《CSAPP》(深入理解计算机系统)里面说过一句话
存储器层次结构的本质是,每一层存储设备都是较低一层设备的缓存

翻译成人话,就是说Linux会把内存当作是硬盘的高速缓存
面试官:现在知道那道送分题应该怎么回答了吧
我:我…

Join算法
面试官:再给你个机会,如果让你来实现Join算法你会怎么做?
我:无索引的话,嵌套循环就完事了嗷。有索引的话,则可以利用索引来提升性能.
面试官:说回join_buffer 你认为join_buffer里面存储的是什么?
我:在扫描过程中,数据库会选择一个表把他要返回以及需要进行和其他表进行比较的数据放进join_buffer
面试官:有索引的情况下是怎么处理的?
我:这个就比较简单了,直接读取两个表的索引树进行比较就完事了嗷,我这边介绍一下无索引的处理方式
Nested Loop Join

嵌套循环,每次只读取表中的一行数据,也就是说如果outerTable有10万行数据, innerTable有100行数据,需要读取10000000次(假设这两个表的文件没有被操作系统给缓存到内存, 我们称之为冷数据表)
当然现在没啥数据库引擎使用这种算法(太慢了)
Block nested loop

Block 块,也就是说每次都会取一块数据到内存以减少I/O的开销
当没有索引可以使用的时候,MySQL InnoDB 就会使用这种算法
考虑以下两个表 t_a 和t_b

当无法使用索引执行join操作的时候,InnoDB会自动使用Block nested loop 算法

总结
上学时,数据库老师最喜欢考数据库范式,直到上班才学会一切以性能为准,能冗余就冗余,实在冗余不了的就join如果join真的影响到性能。试着调大你的join_buffer_size, 或者换固态硬盘。
到此这篇关于为什么代码规范要求SQL语句不要过多的join的文章就介绍到这了,更多相关SQL语句不要过多join内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQL语句优化之JOIN和LEFT JOIN 和 RIGHT JOIN语句的优化
在数据库的应用中,我们经常需要对数据库进行多表查询,然而当数据量非常大时多表查询会对执行效率产生非常大的影响,因此我们在使用JOIN和LEFT JOIN 和 RIGHT JOIN语句时要特别注意: SQL语句的join原理: 数据库中的join操作,实际上是对一个表和另一个表的关联,而很多错误理解为,先把这两个表来一个迪卡尔积,然后扔到内存,用where和having条件来慢慢筛选,其实数据库没那么笨的,那样会占用大量的内存,而且效率不高,比如,我们只需要的一个表的一些行和另一个表的一些行,如果
-
SQL语句中不同的连接JOIN及join的用法
为了从两个表中获取数据,我们有时会用JOIN将两个表连接起来.通常有以下几种连接方式: JOIN or INNER JOIN(内连接) : 这两个是相同的,要求两边表同时有对应的数据,返回行,任何一边缺失数据就不显示. LEFT JOIN(左外连接):即使右边的表中没有匹配,也从左表返回所有的行. RIGHT JOIN(右外连接):即使左边的表中没有匹配,也从右表返回所有的行. FULL JOIN(全外连接):只要其中一个表中存在匹配就返回行. 如例,有grade表(课程号sn,分数scro
-
解析sql语句中left_join、inner_join中的on与where的区别
table a(id, type):id type ----------------------------------1 1 2 1 3 2 table b(id, class):id class ---------------------------------1 12 2sql语句1:select a.*, b.* from a left join b on a.id = b
-
SQL语句的并集UNION 交集JOIN(内连接,外连接)等介绍
1. a. 并集UNION SELECT column1, column2 FROM table1 UNION SELECT column1, column2 FROM table2 b. 交集JOIN SELECT * FROM table1 AS a JOIN table2 b ON a.name=b.name c. 差集NOT IN SELECT * FROM table1 WHERE name NOT IN(SELECT name FROM table2) d. 笛卡尔积 SELECT
-

为什么代码规范要求SQL语句不要过多的join
送分题 面试官:有操作过Linux吗? 我:有的呀 面试官:我想查看内存的使用情况该用什么命令 我:free 或者 top 面试官:那你说一下用free命令都可以看到啥信息 我:那,如下图所示 可以看到内存以及缓存的使用情况 total 总内存 used 已用内存 free 空闲内存 buff/cache 已使用的缓存 avaiable 可用内存 面试官:那你知道怎么清理已使用的缓存吗(buff/cache) 我:em- 不知道 面试官:sync; echo 3 > /proc/sys/vm/d
-
djang常用查询SQL语句的使用代码
将django语法和sql对应一下,希望对大家有所帮助 查询单个列的值 story.object.values_list("url", flat=True) SELECT `story`.`url` FROM `hbtc_story` WHERE `story`.`status` = resolved AND查询 Stories.objects.filter(Q(status='resolved') & Q(status='developing')) SELECT * FROM
-
iOS开发中使用SQL语句操作数据库的基本用法指南
SQL代码应用示例 一.使用代码的方式批量添加(导入)数据到数据库中 1.执行SQL语句在数据库中添加一条信息 插入一条数据的sql语句: 点击run执行语句之后,刷新数据 2.在ios项目中使用代码批量添加多行数据示例 代码示例: 复制代码 代码如下: // // main.m // 01-为数据库添加多行数据 // // Created by apple on 14-7-26. // Copyright (c) 2014年 wendingding. All rights reserv
-
asp经典入门教程 在ASP中使用SQL 语句第1/2页
MySQL.SQL Server和mSQL都是绝佳的SQL工具,可惜,在ASP的环境下你却用不着它们来创建实用的SQL语句.不过,你可以利用自己掌握的Access知识以及相应的Access技能,再加上我们的提示和技巧,相信一定能成功地在你的ASP网页中加入SQL. 1. SELECT 语句 在SQL的世界里,最最基础的操作就是SELECT 语句了.在数据库工具下直接采用SQL的时候很多人都会熟悉下面的操作:SELECT whatFROM whichTableWHERE criteria 执行以上
-
ASP中经常使用的SQL语句与教程说明
1,SELECT 语句 在SQL的世界里,最最基础的操作就是SELECT 语句了.在数据库工具下直接采用SQL的时候很多人都会熟悉下面的操作: 复制代码 代码如下: SELECT what FROM whichTable WHERE criteria 执行以上语句就会创建一个存放其结果的查询. 而在ASP页面文件上,你也可以采用以上的一般语法,不过情况稍微不同,ASP编程的时候,ELECT 语句的内容要作为字符串赋给一个变量: 复制代码 代码如下: SQL = "SELECT what FR
-
通过SQL语句来备份,还原数据库
eg: 复制代码 代码如下: /* 通过SQL 语句备份数据库 */ BACKUP DATABASE mydb TO DISK ='C:\DBBACK\mydb.BAK' --这里指定需要备份数据库的路径和文件名,注意:路径的文件夹是必须已经创建的.文件名可以使用日期来标示 /* 通过SQL语句还原数据库 */ USE master RESTORE DATABASE mydb FROM DISK='C:\DBBACK\mydb.BAK' WITH REPLACE 注意:很多时候不能直接还原,因为
-
在Java的Hibernate框架中使用SQL语句的简单介绍
Hibernate中有HQL查询语法.但我们用得比较熟的还是数SQL语句,那么应该怎么来让Hibernate支持SQL呢?这个不用我们去考虑了,Hibernate团队已经早就做好了. 废话不说,直接来例子啦. select * from t_user usr 上面是一条SQL语句,又是废话,是个人都知道.我们想让Hibernate执行这条语句,怎么办呢?看代码: Query query = session.createSQLQuery("select * from t_user u
-
使用BAT批处理执行sql语句的代码
1.把待执行Sql保存在一个文件,这里为20110224.sql.2.新建一个扩展名.bat的批处理文件,输入下面命令并保存后,双击.bat文件,系统会自动执行20110224.sql的语句: 复制代码 代码如下: osql -S gdjlc -d TestDB -U sa -P 1 -i 20110224.sql osql参数见下面=======================================================================: E:\>osql
-
springmvc+mybatis 做分页sql 语句实例代码
废话不多说了,直接给大家贴代码了,具体代码如下所示: <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="s
-
PHP mysqli 增强 批量执行sql 语句的实现代码
mysqli 增强-批量执行sql 语句 复制代码 代码如下: <?php //mysqli 增强-批量执行sql 语句 //批量执行dql //使用mysqli的mysqli::multi_query() 一次性添加3个用户 $mysqli =new MySQLi("localhost","root","root","test"); if($mysqli->connect_error){