解决BN和Dropout共同使用时会出现的问题
BN与Dropout共同使用出现的问题
BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
相关的研究参考论文:Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift
本论文作者发现理解 Dropout 与 BN 之间冲突的关键是网络状态切换过程中存在神经方差的(neural variance)不一致行为。
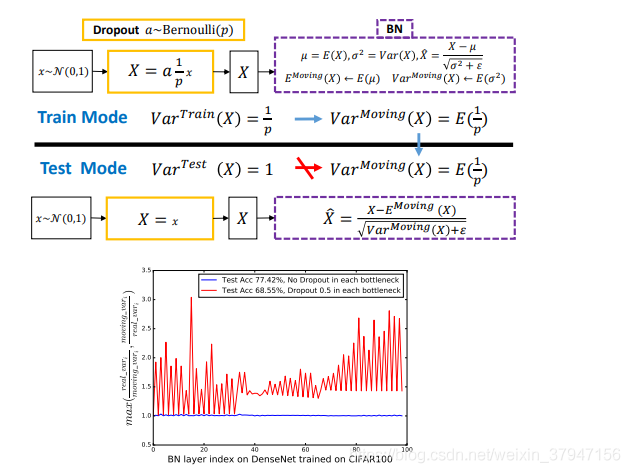
试想若有图一中的神经响应 X,当网络从训练转为测试时,Dropout 可以通过其随机失活保留率(即 p)来缩放响应,并在学习中改变神经元的方差,而 BN 仍然维持 X 的统计滑动方差。
这种方差不匹配可能导致数值不稳定(见下图中的红色曲线)。
而随着网络越来越深,最终预测的数值偏差可能会累计,从而降低系统的性能。
简单起见,作者们将这一现象命名为「方差偏移」。
事实上,如果没有 Dropout,那么实际前馈中的神经元方差将与 BN 所累计的滑动方差非常接近(见下图中的蓝色曲线),这也保证了其较高的测试准确率。
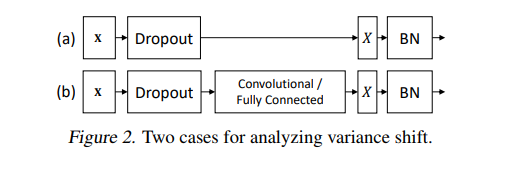
作者采用了两种策略来探索如何打破这种局限。
一个是在所有 BN 层后使用 Dropout,另一个就是修改 Dropout 的公式让它对方差并不那么敏感,就是高斯Dropout。
第一个方案比较简单
把Dropout放在所有BN层的后面就可以了,这样就不会产生方差偏移的问题,但实则有逃避问题的感觉。
第二个方案
来自Dropout原文里提到的一种高斯Dropout,是对Dropout形式的一种拓展。作者进一步拓展了高斯Dropout,提出了一个均匀分布Dropout,这样做带来了一个好处就是这个形式的Dropout(又称为“Uout”)对方差的偏移的敏感度降低了,总得来说就是整体方差偏地没有那么厉害了。
BN、dropout的几个问题和思考
1、BN的scale初始化
scale一般初始化为1.0。
联想到权重初始化时,使用relu激活函数时若采用随机正太分布初始化权重的公式是sqrt(2.0/Nin),其中Nin是输入节点数。即比一般的方法大了2的平方根(原因是relu之后一半的数据变成了0,所以应乘以根号2)。
那么relu前的BN,是否将scale初始化为根号2也会加速训练?
这里主要有个疑点:BN的其中一个目的是统一各层的方差,以适用一个统一的学习率。那么若同时存在sigmoid、relu等多种网络,以上方法会不会使得统一方差以适应不同学习率的效果打了折扣?
没来得及试验效果,如果有试过的朋友请告知下效果。
2、dropout后的标准差改变问题
实践发现droput之后改变了数据的标准差(令标准差变大,若数据均值非0时,甚至均值也会产生改变)。
如果同时又使用了BN归一化,由于BN在训练时保存了训练集的均值与标准差。dropout影响了所保存的均值与标准差的准确性(不能适应未来预测数据的需要),那么将影响网络的准确性。
若输入数据为正太分布,只需要在dropout后乘以sqrt(0.5)即可恢复原来的标准差。但是对于非0的均值改变、以及非正太分布的数据数据,又有什么好的办法解决呢?
3、稀疏自编码的稀疏系数
稀疏自编码使用一个接近0的额外惩罚因子来使得隐层大部分节点大多数时候是抑制的,本质上使隐层输出均值为负数(激活前),例如惩罚因子为0.05,对应sigmoid的输入为-3.5,即要求隐层激活前的输出中间值为-3.5,那么,是不是可以在激活前加一层BN,beta设为-3.5,这样学起来比较快?
经过测试,的确将BN的beta设为负数可加快训练速度。因为网络初始化时就是稀疏的。
但是是不是有什么副作用,没有理论上的研究。
4、max pooling是非线性的,avg pooling是线性的
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
聊聊pytorch测试的时候为何要加上model.eval()
Do need to use model.eval() when I test? Sure, Dropout works as a regularization for preventing overfitting during training. It randomly zeros the elements of inputs in Dropout layer on forward call. It should be disabled during testing since you may
-

解决Pytorch中的神坑:关于model.eval的问题
有时候使用Pytorch训练完模型,在测试数据上面得到的结果令人大跌眼镜. 这个时候需要检查一下定义的Model类中有没有 BN 或 Dropout 层,如果有任何一个存在 那么在测试之前需要加入一行代码: #model是实例化的模型对象 model = model.eval() 表示将模型转变为evaluation(测试)模式,这样就可以排除BN和Dropout对测试的干扰. 因为BN和Dropout在训练和测试时是不同的: 对于BN,训练时通常采用mini-batch,所以每一批中的mean
-
pytorch:model.train和model.eval用法及区别详解
使用PyTorch进行训练和测试时一定注意要把实例化的model指定train/eval,eval()时,框架会自动把BN和DropOut固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大!!!!!! Class Inpaint_Network() ...... Model = Inpaint_Nerwoek() #train: Model.train(mode=True) ..... #test: Model.ev
-
解决BN和Dropout共同使用时会出现的问题
BN与Dropout共同使用出现的问题 BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果. 相关的研究参考论文:Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift 本论文作者发现理解 Dropout 与 BN 之间冲突的关键是网络状态切换过程中存在神经方差的(neural varianc
-
对比分析BN和dropout在预测和训练时区别
目录 Batch Normalization Dropout Batch Normalization和Dropout是深度学习模型中常用的结构. 但BN和dropout在训练和测试时使用却不相同. Batch Normalization BN在训练时是在每个batch上计算均值和方差来进行归一化,每个batch的样本量都不大,所以每次计算出来的均值和方差就存在差异.预测时一般传入一个样本,所以不存在归一化,其次哪怕是预测一个batch,但batch计算出来的均值和方差是偏离总体样本的,所以通常是
-
解决Pytorch在测试与训练过程中的验证结果不一致问题
引言 今天在使用Pytorch导入此前保存的模型进行测试,在过程中发现输出的结果与验证结果差距甚大,经过排查后发现是forward与eval()顺序问题. 现象 此前的错误代码是 input_cpu = torch.ones((1, 2, 160, 160)) target_cpu =torch.ones((1, 2, 160, 160)) target_gpu, input_gpu = target_cpu.cuda(), input_cpu.cuda() model.set_input_2(
-
解决vue路由组件vue-router实例被复用问题
最近在开发过程中遇到如下问题: 当前路由是这样的 http://127.0.0.1:3010/order?keywords=22 只改变keywords的值,路由不跳转 http://127.0.0.1:3010/order?keywords=33338 造成这样的原因如下图所示: 参考文档:https://router.vuejs.org/en/essentials/dynamic-matching.html 这种情况网上的解决方式: 使用vue-router切换路由时会触发组件树的更新,根据
-
springboot配置ssl后启动一直是端口被占用的解决
目录 springboot配置ssl后启动一直是端口被占用 springboot端口被占用一招解决 解决步骤 springboot配置ssl后启动一直是端口被占用 srpingboot 配置 SSL 一直说密码不对然后端口被占用 我之前是这么写的 然后运行报错 怎么解决的呢 就是 把文件放到了 根目录 然后这样写 就解决了 // An highlighted blo #端口号 server.port=8089 #SSL配置 server.ssl.key-store=2503725_xcx.goo
-
keras的三种模型实现与区别说明
前言 一.keras提供了三种定义模型的方式 1. 序列式(Sequential) API 序贯(sequential)API允许你为大多数问题逐层堆叠创建模型.虽然说对很多的应用来说,这样的一个手法很简单也解决了很多深度学习网络结构的构建,但是它也有限制-它不允许你创建模型有共享层或有多个输入或输出的网络. 2. 函数式(Functional) API Keras函数式(functional)API为构建网络模型提供了更为灵活的方式. 它允许你定义多个输入或输出模型以及共享图层的模型.除此之外
-
Pytorch 中net.train 和 net.eval的使用说明
在训练模型时会在前面加上: model.train() 在测试模型时在前面使用: model.eval() 同时发现,如果不写这两个程序也可以运行,这是因为这两个方法是针对在网络训练和测试时采用不同方式的情况,比如Batch Normalization 和 Dropout. 训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念. 由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差. 所有B
-
详解model.train()和model.eval()两种模式的原理与用法
一.两种模式 pytorch可以给我们提供两种方式来切换训练和评估(推断)的模式,分别是:model.train() 和 model.eval(). 一般用法是:在训练开始之前写上 model.trian() ,在测试时写上 model.eval() . 二.功能 1. model.train() 在使用 pytorch 构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是 启用 batch normalization 和 dropout . 如果模型中有BN层(