Python机器学习应用之支持向量机的分类预测篇
目录
- 1、Question?
- 2、Answer!——SVM
- 3、软间隔
- 4、超平面
支持向量机常用于数据分类,也可以用于数据的回归预测
1、Question?
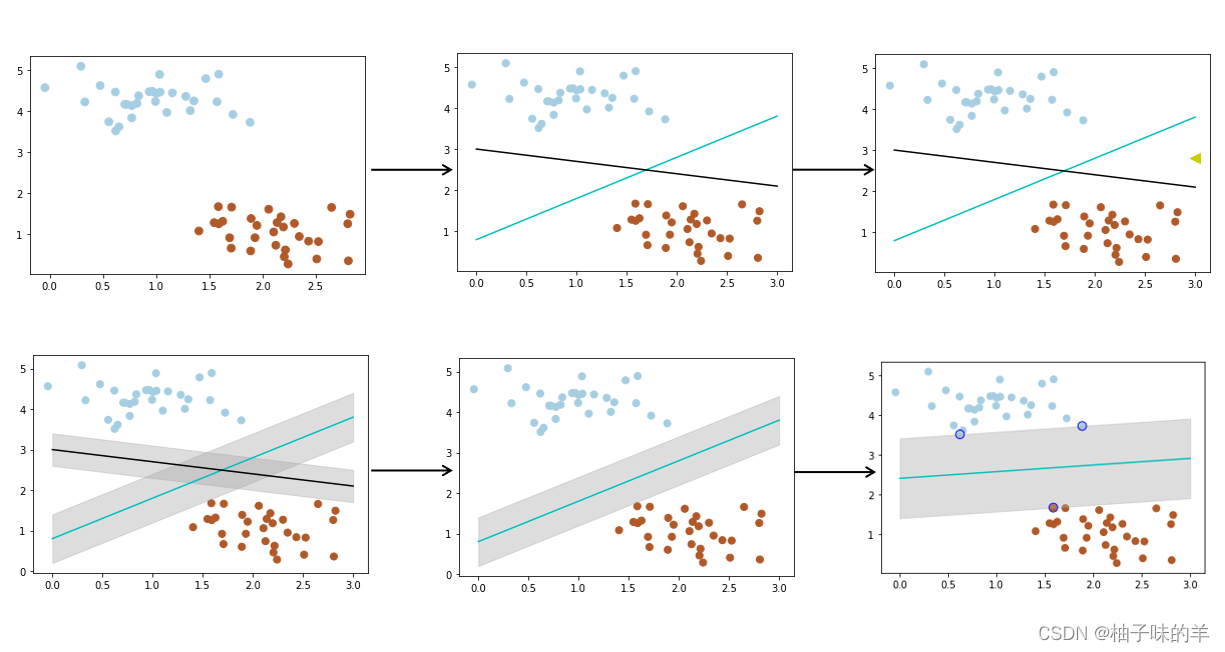
我们经常会遇到这样的问题,给你一些属于两个类别的数据(如子图1),需要一个线性分类器将这些数据分开,有很多分法(如子图2),现在有一个问题,两个分类器,哪一个更好?为了判断好坏,我们需要引入一个准则:好的分类器不仅仅能够很好的分开已有的数据集,还能对为知的数据进行两个划分,假设现在有一个属于红色数据点的新数据(如子图3中的绿三角),可以看到此时黑色的线会把这个新的数据集分错,而蓝色的线不会。**那么如何评判两条线的健壮性?**此时,引入一个重要的概念——最大间隔(刻画着当前分类器与数据集的边界)(如子图4中的阴影部分)可以看到蓝色的线最大的间隔大于黑色的线,所以选择蓝色的线作为我们的分类器。(如子图5)此时的分类器是最优分类器吗?或者说,有没有更好的分类器具有更大的间隔?有的(如子图6)为了找到最优分类器,引入SVM
2、Answer!——SVM
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
x_fit = np.linspace(0, 3)
#使用SVM
from sklearn.svm import SVC
# SVM 函数
clf = SVC(kernel='linear')
clf.fit(X, y)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_p = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下边界
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上届
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_p, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')
运行结果
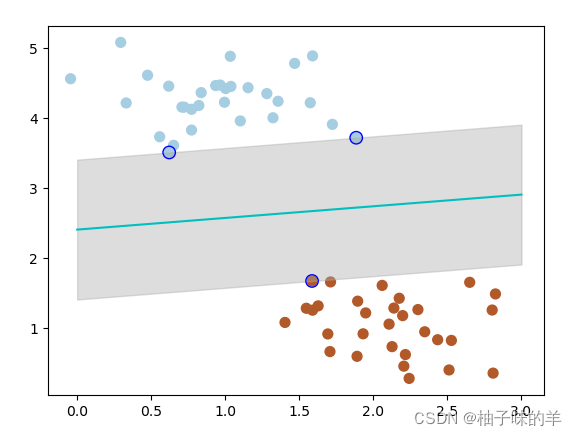
其中带边线的是距离当前分类器最近的点,将这些点称之为支持向量,支持向量机为我们在众多可能的分类器之间进行选择的原则,从而确保对为知数据集具有更高的泛化性
3、软间隔
在很多时候,我们拿到是数据不想上述那样分明(如下图)这种情况并不容易找到上述那样的最大间隔。于是就有了软间隔,相对于硬间隔,我们允许个别数据出现在间隔带中。我们知道,如果没有一个原则进行约束,满足软间隔的分类器也会出现很多条。所以需要对分错的数据进行惩罚,SVM函数,有一个参数C就是惩罚参数。惩罚参数越小,容忍性就越大
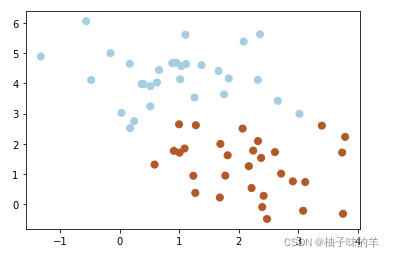
——此处C设置为1
#%%软间隔
X, y = make_blobs(n_samples=60, centers=2, random_state=0, cluster_std=0.9)
x_fit = np.linspace(-2, 4)
# 惩罚参数:C=1,
clf = SVC(C=1, kernel='linear')
clf.fit(X, y)
# 最佳函数
w = clf.coef_[0]
a = -w[0] / w[1]
y_great = a*x_fit - (clf.intercept_[0]) / w[1]
# 最大边距 下边界
b_down = clf.support_vectors_[0]
y_down = a* x_fit + b_down[1] - a * b_down[0]
# 最大边距 上边界
b_up = clf.support_vectors_[-1]
y_up = a* x_fit + b_up[1] - a * b_up[0]
# 画散点图
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 画函数
plt.plot(x_fit, y_great, '-c')
# 画边距
plt.fill_between(x_fit, y_down, y_up, edgecolor='none', color='#AAAAAA', alpha=0.4)
# 画支持向量
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',
s=80, facecolors='none')
运行结果

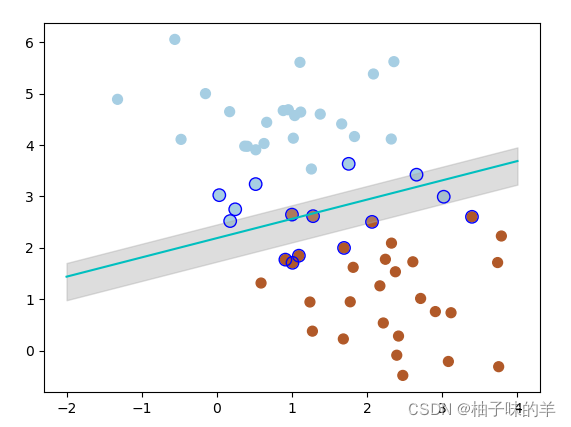
——当将C设置为0.2时,SVM会更有包容性,从而兼容更多的错分样本,结果如下:
4、超平面
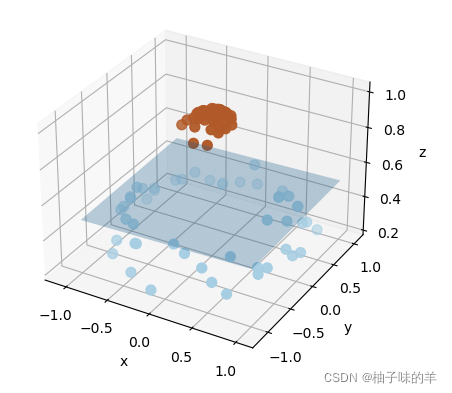
有时,我们得到的数据是这样的(如下图),这时,可以将二维空间(低维)的数据映射到三维空间(高维)中,此时,可以通过一个超平面对数据进行划分,所以,映射的目的在于使用SVM在高维空间找到超平面的能力
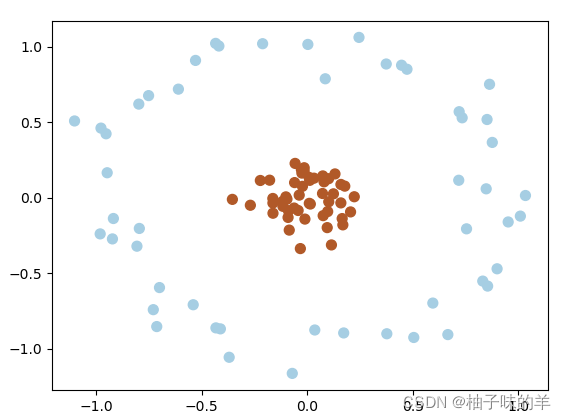
#%%超平面
from sklearn.datasets import make_circles
# 画散点图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
# 数据映射
r = np.exp(-(X[:, 0] ** 2 + X[:, 1] ** 2))
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap=plt.cm.Paired)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
x_1, y_1 = np.meshgrid(np.linspace(-1, 1), np.linspace(-1, 1))
z = 0.01*x_1 + 0.01*y_1 + 0.5
ax.plot_surface(x_1, y_1, z, alpha=0.3)
运行结果
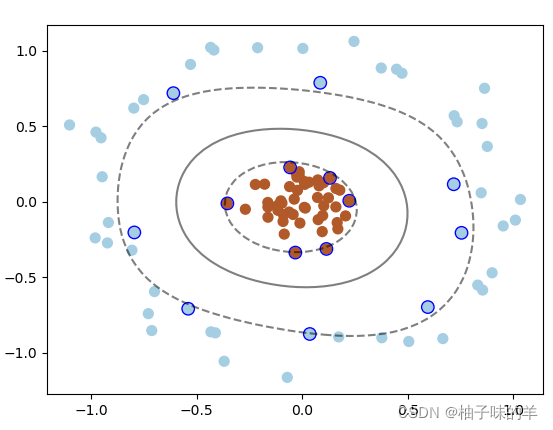
使用高斯核函数实现这种情形的分类
#%%使用高斯核函数实现这种分类:kernel=‘rbf'
# 画图
X, y = make_circles(100, factor=.1, noise=.1, random_state=2019)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap=plt.cm.Paired)
clf = SVC(kernel='rbf')
clf.fit(X, y)
ax = plt.gca()
x = np.linspace(-1, 1)
y = np.linspace(-1, 1)
x_1, y_1 = np.meshgrid(x, y)
P = np.zeros_like(x_1)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function(np.array([[xi, yj]]))
ax.contour(x_1, y_1, P, colors='k', levels=[-1, 0, 0.9], alpha=0.5,linestyles=['--', '-', '--'])
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], edgecolor='b',s=80, facecolors='none');
运行结果
今日告一段落~
到此这篇关于Python机器学习应用之支持向量机的分类预测篇的文章就介绍到这了,更多相关Python 支持向量机内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习算法之决策树算法的实现与优缺点
1.算法概述 决策树算法是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法. 分类算法是利用训练样本集获得分类函数即分类模型(分类器),从而实现将数据集中的样本划分到各个类中.分类模型通过学习训练样本中属性集与类别之间的潜在关系,并以此为依据对新样本属于哪一类进行预测. 决策树算法是直观运用概率分析的一种图解法,是一种十分常用的分类方法,属于有监督学习. 决策树是一种树形结构,其中每个内部结点表示在一个属性上的测试,每个
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取
-
Python DPED机器学习之实现照片美化
目录 前言 环境部署 项目结构 tensorflow安装 其他依赖安装 VGG-19下载 项目运行 准备图片素材 测试效果 前言 最近发现了一个可以把照片美化的项目,自己玩了玩,挺有意思的,分享一下. Github地址:DPED项目地址 下面来看看项目怎么玩?先放一些项目给出的效果图.可以看出照片更明亮好看了. 环境部署 项目结构 下面是项目的原始结构: tensorflow安装 按照项目的说明,我们需要安装tensorflow以及一些必要的库. 如果安装gpu版本的tensorflow需要对照
-
Python机器学习之实现模糊照片人脸恢复清晰
目录 前言 环境安装 验证模型 总结 前言 最近看到一个有意思的机器学习项目--GFPGAN,他可以将模糊的人脸照片恢复清晰.开源项目的Github地址:https://github.com/TencentARC/GFPGAN 我们看一看作者给出的对比图. 最右侧的就是GFPGAN的效果,看一下最左层的输入图片,可以发现GFPGAN将图片恢复的非常清晰.这个效果非常惊艳. 按照以前的惯例,我还是先把这个项目安装使用一下,看看能不能对代码重新封装,变成可以工程化的项目. 环境安装 我们先看一下项目
-
在Python中通过机器学习实现人体姿势估计
目录 什么是姿态估计? 2D 与 3D 姿态估计 为姿态估计准备数据集 创建姿势估计模型 模型结果 结论 姿态检测是计算机视觉领域的一个活跃研究领域.你可以从字面上找到数百篇研究论文和几个试图解决姿势检测问题的模型. 之所以有如此多的机器学习爱好者被姿势估计所吸引,是因为它的应用范围很广,而且实用性很强. 在本文中,我们将介绍一种使用机器学习和 Python 中一些非常有用的库进行姿势检测和估计的应用. 什么是姿态估计? 姿态估计是一种跟踪人或物体运动的计算机视觉技术.这通常通过查找给定对象的关
-
Python机器学习之决策树算法
一.决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构. 决策树的根结点是所有样本中信息量最大的属性.树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性.决策树的叶结点是样本的类别值.决策树是一种知识表示形式,它是对所有样本数据的高度概括决策树能准确地识别所有样本的类别,也能有效地识别新样本的类别. 决策树算法ID3的基本思想: 首先找出最有判别力的属性,把样例分成多个子集,每个子集又选择最有判别力的属性进行划分,一直进行到所有子集仅包含同一类型的数据为止.最后
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Python机器学习应用之朴素贝叶斯篇
朴素贝叶斯(Naive Bayes,NB):朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一.朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等. 1.鸢尾花案例 #%%库函数导入 import warnings warnings.filterwarnings('ignore') import numpy as np # 加载莺尾花数据集 from sklearn import datasets # 导入高斯朴素贝叶斯分类器 from sklearn.naive_b
-
Python机器学习应用之支持向量机的分类预测篇
目录 1.Question? 2.Answer!——SVM 3.软间隔 4.超平面 支持向量机常用于数据分类,也可以用于数据的回归预测 1.Question? 我们经常会遇到这样的问题,给你一些属于两个类别的数据(如子图1),需要一个线性分类器将这些数据分开,有很多分法(如子图2),现在有一个问题,两个分类器,哪一个更好?为了判断好坏,我们需要引入一个准则:好的分类器不仅仅能够很好的分开已有的数据集,还能对为知的数据进行两个划分,假设现在有一个属于红色数据点的新数据(如子图3中的绿三角),可以看
-
Python机器学习应用之基于LightGBM的分类预测篇解读
目录 一.Introduction 1 LightGBM的优点 2 LightGBM的缺点 二.实现过程 1 数据集介绍 2 Coding 三.Keys LightGBM的重要参数 基本参数调整 针对训练速度的参数调整 针对准确率的参数调整 针对过拟合的参数调整 一.Introduction LightGBM是扩展机器学习系统.是一款基于GBDT(梯度提升决策树)算法的分布梯度提升框架.其设计思路主要集中在减少数据对内存与计算性能的使用上,以及减少多机器并行计算时的通讯代价 1 LightGBM
-
Python机器学习之手写KNN算法预测城市空气质量
目录 一.KNN算法简介 二.KNN算法实现思路 三.KNN算法预测城市空气质量 1. 获取数据 2. 生成测试集和训练集 3. 实现KNN算法 一.KNN算法简介 KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中常用算法之一,其指导思想是"近朱者赤,近墨者黑",即由你的邻居来推断出你的类别. KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与
-
Python机器学习之SVM支持向量机
SVM支持向量机是建立于统计学习理论上的一种分类算法,适合与处理具备高维特征的数据集. SVM算法的数学原理相对比较复杂,好在由于SVM算法的研究与应用如此火爆,CSDN博客里也有大量的好文章对此进行分析,下面给出几个本人认为讲解的相当不错的: 支持向量机通俗导论(理解SVM的3层境界) JULY大牛讲的是如此详细,由浅入深层层推进,以至于关于SVM的原理,我一个字都不想写了..强烈推荐. 还有一个比较通俗的简单版本的:手把手教你实现SVM算法 SVN原理比较复杂,但是思想很简单,一句话概括,就
-
Python机器学习logistic回归代码解析
本文主要研究的是Python机器学习logistic回归的相关内容,同时介绍了一些机器学习中的概念,具体如下. Logistic回归的主要目的:寻找一个非线性函数sigmod最佳的拟合参数 拟合.插值和逼近是数值分析的三大工具 回归:对一直公式的位置参数进行估计 拟合:把平面上的一些系列点,用一条光滑曲线连接起来 logistic主要思想:根据现有数据对分类边界线建立回归公式.以此进行分类 sigmoid函数:在神经网络中它是所谓的激励函数.当输入大于0时,输出趋向于1,输入小于0时,输出趋向0
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并
-
Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,
-
Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输