Mybatis-Plus默认主键策略导致自动生成19位长度主键id的坑
某天检查一位离职同事写的代码,发现其对应表虽然设置了AUTO_INCREMENT自增,但页面新增功能生成的数据主键id很诡异,长度达到了19位,且不是从1开始递增的——

我检查了一下,发现该表目前自增主键已经变成从1468844351843872770开始递增了——
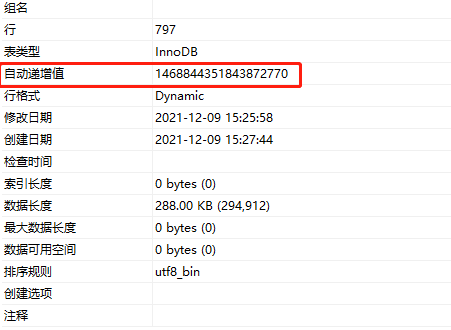
这就很奇怪了,目前该表数据量很少,且主键是设置AUTO_INCREMENT,正常而言,应该自增id仍在1000范围内,但目前已经变成一串长数字。
底层ORM框架用的是Mybatis-Plus,我寻思了一下,这看起来像是在插入数据库就自动生成的id,导致并非默认使用MySql的自增AUTO_INCREMENT来生成id。
因此,决定一步步定位,先给Mybatis-Plus打印出sql日志,看下其insert语句是否自动生成了一个id后才插入数据库。
按照网上的教程,我在yaml文件里对应的mybatis-plus配置处设置了开启sql打印日志——
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
然而,很诡异的是,执行操作时并没有打印出sql日志,故而,某一瞬间,我忽然觉得,这群家伙可能都是互相抄的,没有验证当springboot集成了logback时,单纯这样设置并没有效果。
最后额外在yaml加了以下配置,才能正常打印MP的sql日志信息——
logging:
level:
com:
zhu:
test:
mapper: debug
接下来,验证一番后,发现,Mybatis-Plus在做insert操作时,确实自动生成一条长19的数字当做该条数据的id插入到MySql,导致虽然MySql表设置了自增,但被Mybatis-Plus生成的id为1468844351843872769所影响,导致下一条数据自动递增值变成1468844351843872770,这种过长的id值,在做索引维护时,是很影响效率,占用空间过大,故而,这个问题必须得解决。

到这里,就确定,这个长数字的id,是在代码层次就自动生成了,最后进入对应的实体类中,发现该映射数据表的id字段,并没有显示设置对应的主键生成策略。
@Data
@TableName("test")
public class Test extends Model<Test> implements Serializable {
private Long id;
......
}
Mybatis-Plus主要有以下几种主键生成策略——
@Getter
public enum IdType {
/**
* 数据库ID自增
*/
AUTO(0),
/**
* 该类型为未设置主键类型
*/
NONE(1),
/**
* 用户输入ID
* 该类型可以通过自己注册自动填充插件进行填充
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 全局唯一ID (idWorker),根据雪花算法生成19位数字,long类型
*/
ID_WORKER(3),
/**
* 全局唯一ID (UUID)
*/
UUID(4),
/**
* 字符串全局唯一ID (idWorker 的字符串表示),根据雪花算法生成19位字符串,String
*/
ID_WORKER_STR(5);
private int key;
IdType(int key) {
this.key = key;
}
}
这里验证了一下,当设置成这样时,就能正常生成数据库自增的id了,使用数据库AUTO_INCREMENT从1开始自增的效果了,当然,其实使用IdType.AUTO也是可以的——
@Data
@TableName("test")
public class Test extends Model<Test> implements Serializable {
@TableId(value = "id", type = IdType.INPUT)
private Long id;
......
}
百度网上的说法,当Mybatis-Plus实体类没有显示设置主键策略时,将默认使用雪花算法生成,也就是IdType.ID_WORKER或者IdType.ID_WORKER_STR,具体是long类型的19位还是字符串的19位,应该是根据字段定义类型来判断。
snowflake算法是Twitter开源的分布式ID生成算法,结果是一个long类型的ID 。其核心思想:使用41bit作为毫秒数,10bit作为机器的ID(5bit数据中心,5bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每个毫秒可以产生4096个ID),最后还有一个符号位,永远是0。
接下来,先验证Mybatis-Plus默认主键策略是如何的。
Mybatis-Plus项目在启动时,会对注解实体类进行初始化,然后缓存到系统Map中。
这里,只需要关注Mybatis-Plus源码TableInfoHelper类中的initTableInfo方法即可,这个方法在项目启动时会被调用,然后初始化所有注解@TableName的实体类。与主键根据哪种策略来设置的逻辑在方法initTableFields(clazz, globalConfig, tableInfo)当中——
public synchronized static TableInfo initTableInfo(MapperBuilderAssistant builderAssistant, Class<?> clazz) {
TableInfo tableInfo = TABLE_INFO_CACHE.get(clazz.getName());
if (tableInfo != null) {
if (tableInfo.getConfigMark() == null && builderAssistant != null) {
tableInfo.setConfigMark(builderAssistant.getConfiguration());
}
return tableInfo;
}
/* 没有获取到缓存信息,则初始化 */
tableInfo = new TableInfo();
GlobalConfig globalConfig;
if (null != builderAssistant) {
tableInfo.setCurrentNamespace(builderAssistant.getCurrentNamespace());
tableInfo.setConfigMark(builderAssistant.getConfiguration());
tableInfo.setUnderCamel(builderAssistant.getConfiguration().isMapUnderscoreToCamelCase());
globalConfig = GlobalConfigUtils.getGlobalConfig(builderAssistant.getConfiguration());
} else {
// 兼容测试场景
globalConfig = GlobalConfigUtils.defaults();
}
/* 初始化表名相关 */
initTableName(clazz, globalConfig, tableInfo);
/* 初始化字段相关 */
initTableFields(clazz, globalConfig, tableInfo);
/* 放入缓存 */
TABLE_INFO_CACHE.put(clazz.getName(), tableInfo);
/* 缓存 Lambda 映射关系 */
LambdaUtils.createCache(clazz, tableInfo);
return tableInfo;
}
在初始化字段相关的initTableFields方法里,会判断是否有@TableId 注解,如果没有,就执行initTableIdWithoutAnnotation方法,连续前文提到的,如果实体类id没有加@TableId(value = "id", type = IdType.INPUT),那么就会取默认的主键策略。这里的判断是否有@TableId 注解,就是判断是否需要取默认的主键策略,至于具体是如何设置默认主键的,我们可以直接进入到initTableIdWithoutAnnotation方法当中。
public static void initTableFields(Class<?> clazz, GlobalConfig globalConfig, TableInfo tableInfo) {
/* 数据库全局配置 */
GlobalConfig.DbConfig dbConfig = globalConfig.getDbConfig();
List<Field> list = getAllFields(clazz);
// 标记是否读取到主键
boolean isReadPK = false;
// 是否存在 @TableId 注解
boolean existTableId = isExistTableId(list);
List<TableFieldInfo> fieldList = new ArrayList<>();
for (Field field : list) {
/*
* 主键ID 初始化
*/
if (!isReadPK) {
if (existTableId) {
isReadPK = initTableIdWithAnnotation(dbConfig, tableInfo, field, clazz);
} else {
isReadPK = initTableIdWithoutAnnotation(dbConfig, tableInfo, field, clazz);
}
if (isReadPK) {
continue;
}
}
......
}
......
}
initTableIdWithoutAnnotation方法——
private static final String DEFAULT_ID_NAME = "id";
/**
* <p>
* 主键属性初始化
* </p>
*
* @param tableInfo 表信息
* @param field 字段
* @param clazz 实体类
* @return true 继续下一个属性判断,返回 continue;
*/
private static boolean initTableIdWithoutAnnotation(GlobalConfig.DbConfig dbConfig, TableInfo tableInfo,
Field field, Class<?> clazz) {
//获取实体类字段名
String column = field.getName();
if (dbConfig.isCapitalMode()) {
column = column.toUpperCase();
}
//当字段名为id
if (DEFAULT_ID_NAME.equalsIgnoreCase(column)) {
if (StringUtils.isEmpty(tableInfo.getKeyColumn())) {
tableInfo.setKeyRelated(checkRelated(tableInfo.isUnderCamel(), field.getName(), column))
//设置表策略
.setIdType(dbConfig.getIdType())
.setKeyColumn(column)
.setKeyProperty(field.getName())
.setClazz(field.getDeclaringClass());
return true;
} else {
throwExceptionId(clazz);
}
}
return false;
}
Debug到这里,可以看到,如果没有 @TableId 注解显示设置主键策略情况下,默认设置的是 ID_WORKER(3),即会根据雪花算法生成19位数字,long类型。

可以进一步发现,这里的 dbConfig是GlobalConfig.DbConfig实例,进入到DbConfig类,可以看到原来实体类映射的数据库设置在这里,主键类型默认是IdType.ID_WORKER。
@Data
public static class DbConfig {
/**
* 数据库类型
*/
private DbType dbType = DbType.OTHER;
/**
* 主键类型(默认 ID_WORKER)
*/
private IdType idType = IdType.ID_WORKER;
/**
* 表名前缀
*/
private String tablePrefix;
/**
* 表名、是否使用下划线命名(默认 true:默认数据库表下划线命名)
*/
private boolean tableUnderline = true;
/**
* String 类型字段 LIKE
*/
private boolean columnLike = false;
/**
* 大写命名
*/
private boolean capitalMode = false;
/**
* 表关键词 key 生成器
*/
private IKeyGenerator keyGenerator;
/**
* 逻辑删除全局值(默认 1、表示已删除)
*/
private String logicDeleteValue = "1";
/**
* 逻辑未删除全局值(默认 0、表示未删除)
*/
private String logicNotDeleteValue = "0";
/**
* 字段验证策略
*/
private FieldStrategy fieldStrategy = FieldStrategy.NOT_NULL;
}
至于如何生成雪花算法id,这里就不一一详细介绍,具体逻辑是在MybatisDefaultParameterHandler类populateKeys方法里,核心代码如下——
protected static Object populateKeys(MetaObjectHandler metaObjectHandler, TableInfo tableInfo,
MappedStatement ms, Object parameterObject, boolean isInsert) {
if (null == tableInfo) {
/* 不处理 */
return parameterObject;
}
/* 自定义元对象填充控制器 */
MetaObject metaObject = ms.getConfiguration().newMetaObject(parameterObject);
// 填充主键
if (isInsert && !StringUtils.isEmpty(tableInfo.getKeyProperty())
&& null != tableInfo.getIdType() && tableInfo.getIdType().getKey() >= 3) {
Object idValue = metaObject.getValue(tableInfo.getKeyProperty());
/* 自定义 ID */
if (StringUtils.checkValNull(idValue)) {
if (tableInfo.getIdType() == IdType.ID_WORKER) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getId());
} else if (tableInfo.getIdType() == IdType.ID_WORKER_STR) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getIdStr());
} else if (tableInfo.getIdType() == IdType.UUID) {
metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.get32UUID());
}
}
}
......
}
前边提到,默认的主键策略是IdType.ID_WORKER,这里有一个判断tableInfo.getIdType() == IdType.ID_WORKER,对代码Debug可以看到,metaObject的setValue(tableInfo.getKeyProperty(), IdWorker.getId())代码的作用,是对注解id进行了值填充。

填充的值为IdWorker.getId()返回的1468970800437465089,刚好是19位长度,这就意味着,这里产生的id值,就是我们最后要找的。
IdWorker.getId()实现本质,正好是基于Snowflake实现64位自增ID算法,而Snowflake,正是引用了雪花算法——
/**
* <p>
* 高效GUID产生算法(sequence),基于Snowflake实现64位自增ID算法。 <br>
* 优化开源项目 http://git.oschina.net/yu120/sequence
* </p>
*
* @author hubin
* @since 2016-08-01
*/
public class IdWorker {
/**
* 主机和进程的机器码
*/
private static final Sequence WORKER = new Sequence();
public static long getId() {
return WORKER.nextId();
}
public static String getIdStr() {
return String.valueOf(WORKER.nextId());
}
/**
* <p>
* 获取去掉"-" UUID
* </p>
*/
public static synchronized String get32UUID() {
return UUID.randomUUID().toString().replace(StringPool.DASH, StringPool.EMPTY);
}
}
到此这篇关于Mybatis-Plus默认主键策略导致自动生成19位长度主键id的坑的文章就介绍到这了,更多相关Mybatis-Plus id主键生成内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

mybatis-plus主键id生成、字段自动填充的实现代码
一.主键id的生成 数据库表里通常都会有一个主键id,来作为这条数据的唯一标识. 常见的方式 1.数据库自动增长 这种很常见了,可以做到全库唯一.因为id是天然排序的,对于涉及到排序的操作会很方便. 2.UUID 上面的自动增长,虽然简单,但是对于分表这样的操作来说就比较麻烦.因为你在第二张插入数据的时候,需要拿到上一张表最后一个数据的id. UUID则不同,每次都一个随机唯一的值,不过因为是随机,所以也就没有排序了. 3.redis redis也可以用来生成id,利用redis的原子操作.好处
-
mybatis-plus的selectById(或者selectOne)在根据主键ID查询实体对象的时候偶尔会出现null的问题记录
mybatis-plus的selectById/selectOne查询结果偶尔出错(为null)的问题记录 错误截图: 亲测重复执行此段代码10次中大概会有连续的2次出现结果为null的情况. 由于后续还需引用到这个查询结果的某些字段信息,会导致程序出现空指针异常,故投机取巧做了如下处理(加了一个while循环让其一直执行selectById(或者selectOne)直到查询结果不为空): 但这终归不是从根本上解决了问题.我也不清白他出现这个问题的根本原因是什么. 到此这篇关于mybatis-p
-
mybatis-plus id主键生成的坑
简要说明 由于mybatis-plus会自动插入一个id到实体对象, 不管你封装与否, 所以有时候导致一些意外的情况发生 默认是生成一个长数字字符串(编码不同可能结尾带有字母) 错误 ested exception is org.apache.ibatis.reflection.ReflectionException: Could not set property 'id' of 'class com.xxx' with value '1110423703487479810' Cause: ja
-
Mybatis-Plus默认主键策略导致自动生成19位长度主键id的坑
某天检查一位离职同事写的代码,发现其对应表虽然设置了AUTO_INCREMENT自增,但页面新增功能生成的数据主键id很诡异,长度达到了19位,且不是从1开始递增的-- 我检查了一下,发现该表目前自增主键已经变成从1468844351843872770开始递增了-- 这就很奇怪了,目前该表数据量很少,且主键是设置AUTO_INCREMENT,正常而言,应该自增id仍在1000范围内,但目前已经变成一串长数字. 底层ORM框架用的是Mybatis-Plus,我寻思了一下,这看起来像是在插入数据库就
-
Mybatis-Plus自动生成的数据库id过长的解决
目录 Mybatis-Plus自动生成的数据库id过长 一.问题 二.解决方案 三.原理 Mybatis-Plus id主键生成的问题 简要说明 错误 解决方案一 解决方案二 Mybatis-Plus自动生成的数据库id过长 一.问题 作为一名第一次使用mybatis-plus的萌新开发工程师,在项目开发过程中遇到一个问题. 当使用mybatis-plus自带的mybatis-generate生成DO文件,如下图所示 DO类由注释@Table修饰,主键id由注释@Id,@GeneratedVal
-
mybatis-plus实体类主键策略有3种(小结)
mybatis plus 实体类主键策略有3种( 注解 > 全局 > 默认 ) 当IdType的类型为ID_WORKER.ID_WORKER_STR或者UUID时,主键由MyBatis Plus的IdWorker类生成,idWorker中调用了分布式唯一 ID 生成器 - Sequence 1.注解方式 @TableId(type = IdType.AUTO)在实体类增加注解即可 @TableName("t_article") public class TArticle e
-
mysql把主键定义为自动增长标识符类型
1.把主键定义为自动增长标识符类型 在mysql中,如果把表的主键设为auto_increment类型,数据库就会自动为主键赋值.例如: create table customers(id int auto_increment primary key notnull, name varchar(15)); insert into customers(name) values("name1"),("name2"); 一旦把id设为auto_increment类型,my
-
Mybatis插件之自动生成不使用默认的驼峰式操作
数据库里面表的字段中带有""_"下划线,我们知道插件默认的是将这些带有下划线的字段默认的变成"优美的驼峰式"的.表是肯定不能动的,实体类的字段也是非常多,改起来非常麻烦,所以就研究了下面这种依靠代码来实现的方式. 修改配置文件: <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE generatorConfiguration PUBLIC "
-
MyBatis框架之mybatis逆向工程自动生成代码
Mybatis属于半自动ORM,在使用这个框架中,工作量最大的就是书写Mapping的映射文件,由于手动书写很容易出错,我们可以利用Mybatis-Generator来帮我们自动生成文件. 逆向工程 1.什么是逆向工程 mybaits需要程序员自己编写sql语句,mybatis官方提供逆向工程 可以针对单表自动生成mybatis执行所需要的代码(mapper.java,mapper.xml.po..) 企业实际开发中,常用的逆向工程方式: 由于数据库的表生成java代码. 2.下载逆向工程 my
-
如何自动生成Mybatis的Mapper文件详解
前言 工作中使用mybatis时我们需要根据数据表字段创建pojo类.mapper文件以及dao类,并且需要配置它们之间的依赖关系,这样的工作很琐碎和重复,mybatis官方也发现了这个问题,因此给我们提供了mybatis generator工具来帮我们自动创建pojo类.mapper文件以及dao类并且会帮我们配置好它们的依赖关系. 实际上,最非常流行MyBatis-Plus中内置了代码生成器:采用代码或者 Maven 插件可快速生成 Mapper . Model . Service . Co
-
Mybatis如何自动生成数据库表结构总结
一般情况下,用Mybatis的时候是先设计表结构再进行实体类以及映射文件编写的,特别是用代码生成器的时候. 但有时候不想用代码生成器,也不想定义表结构,那怎么办? 这个时候就会想到Hibernate,然后想到它的hibernate.hbm2ddl.auto配置项. 所以手工创表的问题可以很方便的迅速用Hibernate来解决. 那有人问啦:就是不想用Hibernate才换的Mybatis,你这又兜回去了吗? 其实不是的,我们需要的就是单单一个hbm2ddl功能. 其实应该这么想:有一款工具能够自
-
Mybatis如何自动生成数据库表的实体类
第一步引入jar 第二步,配置文本文件 # 数据库驱动jar 路径 本地创库的包 drive.class.path=C:/Users/Administrator/.m2/repository/mysql/mysql-connector-java/5.1.30/mysql-connector-java-5.1.30.jar # 数据库连接参数 jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://192.168.1.188:3306/sxh
-
Springboot Mybatis Plus自动生成工具类详解代码
前言 代码生成器,也叫逆向工程,是根据数据库里的表结构,自动生成对应的实体类.映射文件和接口. 看到很多小伙伴在为数据库生成实体类发愁,现分享给大家,提高开发效率. 一.pom依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.1</version> &