Python-Selenium自动化爬虫
目录
- 1.安装
- 2.下载浏览器驱动
- 3.实例
- 3.1下载对应版本的浏览器驱动
- 3.2测试code,打开一个网页,并获取网页的标题
- 3.3一个小样例
- 3.4自动输入并跳转
- 4.开启无头模式
- 5.保存页面截图
- 6.模拟输入和点击
- 6.1根据文本值查找节点
- 6.2获取当前节点的文本
- 6.3打印当前网页的一些信息
- 6.4关闭浏览器driver.close() # 关闭当前网页
- 6.5模拟鼠标滚动
- 7.ChromeOptions
- 8.验证滑块移动
- 9.打开多窗口和页面切换
- 10.Cookie操作
- 11.模拟登录
- 12.优缺点
简单介绍:
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器(2018年开发者说暂停开发,chromedriver也可以实现同样的功能)),可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏。
1.安装
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
2.下载浏览器驱动
这里用的谷歌浏览器
http://npm.taobao.org/mirrors/chromedriver/
查看自己的浏览器版本下载对应的驱动。
把解压后的驱动放在自己的python.exe 目录下。
3.实例
3.1下载对应版本的浏览器驱动
http://npm.taobao.org/mirrors/chromedriver/

把解压后的驱动放在自己的python.exe 目录下
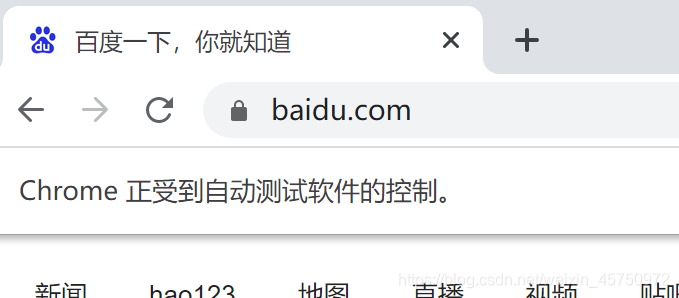
3.2测试code,打开一个网页,并获取网页的标题
from selenium.webdriver import Chrome
if __name__ == '__main__':
web = Chrome()
web.get("https://baidu.com")
print(web.title)

3.3一个小样例
from selenium.webdriver import Chrome
if __name__ == '__main__':
web = Chrome()
url = 'https://ac.nowcoder.com/acm/home'
web.get(url)
# 获取要点击的a标签
el = web.find_element_by_xpath('/html/body/div/div[3]/div[1]/div[1]/div[1]/div/a')
# 点击
el.click() # "/html/body/div/div[3]/div[1]/div[2]/div[2]/div[2]/div[1]/h4/a"
# 爬取想要的内容
lists = web.find_elements_by_xpath("/html/body/div/div[3]/div[1]/div[2]/div[@class='platform-item js-item ']/div["
"2]/div[1]/h4/a")
print(len(lists))
for i in lists:
print(i.text)
3.4自动输入并跳转
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
if __name__ == '__main__':
web = Chrome()
url = 'https://ac.nowcoder.com/acm/home'
web.get(url)
el = web.find_element_by_xpath('/html/body/div/div[3]/div[1]/div[1]/div[1]/div/a')
el.click()
time.sleep(1)
input_el = web.find_element_by_xpath('/html/body/div/div[3]/div[1]/div[1]/div[1]/form/input[1]')
input_el.send_keys('牛客', Keys.ENTER)
# do something
4.开启无头模式
是否开启无头模式(即是否需要界面)
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
option = Options() # 实例化option对象
option.add_argument("--headless") # 给option对象添加无头参数
if __name__ == '__main__':
web = Chrome(executable_path='D:\PyProject\spider\venv\Scripts\chromedriver.exe',options=option) # 指定驱动位置,否则从python解释器目录下查找.
web.get("https://baidu.com")
print(web.title)
5.保存页面截图
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
option = Options() # 实例化option对象
option.add_argument("--headless") # 给option对象添加无头参数
if __name__ == '__main__':
web = Chrome()
web.maximize_window() # 浏览器窗口最大化
web.get("https://baidu.com")
print(web.title)
web.save_screenshot('baidu.png') # 保存当前网页的截图 保存到当前文件夹下
web.close() # 关闭当前网页
6.模拟输入和点击
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
option = Options() # 实例化option对象
option.add_argument("--headless") # 给option对象添加无头参数
if __name__ == '__main__':
web = Chrome()
web.maximize_window() # 浏览器窗口最大化
web.get("https://baidu.com")
el = web.find_element_by_id('kw')
el.send_keys('Harris-H')
btn = web.find_element_by_id('su')
btn.click()
# web.close() # 关闭当前网页
貌似现在百度可以识别出selenium,还需要图片验证。
6.1根据文本值查找节点
# 找到文本值为百度一下的节点
driver.find_element_by_link_text("百度一下")
# 根据链接包含的文本获取元素列表,模糊匹配
driver.find_elements_by_partial_link_text("度一下")
6.2获取当前节点的文本
ele.text # 获取当前节点的文本
ele.get_attribute("data-click") # 获取到属性对应的value
6.3打印当前网页的一些信息
print(driver.page_source) # 打印网页的源码 print(driver.get_cookies()) # 打印出网页的cookie print(driver.current_url) # 打印出当前网页的url
6.4关闭浏览器driver.close() # 关闭当前网页
driver.close() # 关闭当前网页 driver.quit() # 直接关闭浏览器
6.5模拟鼠标滚动
from selenium.webdriver import Chrome import time if __name__ == '__main__': driver = Chrome() driver.get( "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=78000241_12_hao_pg&wd=selenium%20js%E6%BB%91%E5%8A%A8&fenlei=256&rsv_pq=8215ec3a00127601&rsv_t=a763fm%2F7SHtPeSVYKeWnxKwKBisdp%2FBe8pVsIapxTsrlUnas7%2F7Hoo6FnDp6WsslfyiRc3iKxP2s&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=31&rsv_sug1=17&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=9266&rsv_sug4=9770") # 1.滚动到网页底部 js = "document.documentElement.scrollTop=1000" # 执行js driver.execute_script(js) time.sleep(2) # 滚动到顶部 js = "document.documentElement.scrollTop=0" driver.execute_script(js) # 执行js time.sleep(2) driver.close()
7.ChromeOptions
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999") # 添加代理
options.add_argument("--headless") # 无头模式
options.add_argument("--lang=en-US") # 网页显示英语
prefs = {"profile.managed_default_content_settings.images": 2, 'permissions.default.stylesheet': 2} # 禁止渲染
options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip")
8.验证滑块移动
目标:滑动验证码
- 1.定位按钮
- 2.按住滑块
- 3.滑动按钮
import time
from selenium import webdriver
if __name__ == '__main__':
chrome_obj = webdriver.Chrome()
chrome_obj.get('https://www.helloweba.net/demo/2017/unlock/')
# 1.定位滑动按钮
click_obj = chrome_obj.find_element_by_xpath('//div[@class="bar1 bar"]/div[@class="slide-to-unlock-handle"]')
# 2.按住
# 创建一个动作链对象,参数就是浏览器对象
action_obj = webdriver.ActionChains(chrome_obj)
# 点击并且按住,参数就是定位的按钮
action_obj.click_and_hold(click_obj)
# 得到它的宽高
size_ = click_obj.size
width_ = 298 - size_['width'] # 滑框的宽度 减去 滑块的 宽度 就是 向x轴移动的距离(向右)
print(width_)
# 3.定位滑动坐标
action_obj.move_by_offset(298-width_, 0).perform()
# 4.松开滑动
action_obj.release()
time.sleep(6)
chrome_obj.quit()
9.打开多窗口和页面切换
有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to_window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到
from selenium import webdriver
if __name__ == '__main__':
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.implicitly_wait(2)
driver.execute_script("window.open('https://www.douban.com/')")
driver.switch_to.window(driver.window_handles[1])
print(driver.page_source)
10.Cookie操作
# 1.获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
# 2.根据cookie的key获取value:
value = driver.get_cookie(key)
# 3.删除所有的cookie:
driver.delete_all_cookies()
# 4.删除某个cookie:
driver.delete_cookie(key)
# 添加cookie:
driver.add_cookie({"name":"password","value":"111111"})
11.模拟登录
这里模拟登录我们学校教务处:
from selenium.webdriver import Chrome
if __name__ == '__main__':
web = Chrome()
web.get('http://bkjx.wust.edu.cn/')
username = web.find_element_by_id('userAccount')
username.send_keys('xxxxxxx') # 这里填自己的学号
password = web.find_element_by_id('userPassword')
password.send_keys('xxxxxxx') # 这里填自己的密码
btn = web.find_element_by_xpath('//*[@id="ul1"]/li[4]/button')
btn.click()
# do something
因为没有滑块啥的验证,所以就很简单qwq。然后后面进行自己的操作即可。
12.优缺点
selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易。
selenium由于在获取页面的过程中会发送很多请求,所以效率非常低,所以在很多时候需要酌情使用。
到此这篇关于Python-Selenium自动化爬虫的文章就介绍到这了,更多相关 Selenium自动化爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python + selenium 自动化测试框架详解
目录 自动化测试框架 1.基础层(通用层) 2.功能层(页面层) 3.业务层 4.用例层 4层框架对应的项目工程 总结 自动化测试框架 项目自动化测试框架设计为4层 1.基础层(通用层) 基础层: 将通用,重复性比较高的代码封装到这里. 写通用的代码的. 其他3层想要的话,就可以直接调用. 例如: 读取测试数据的代码,读取配置信息的代码:截图的代码的,定位元素的代码等等 2.功能层(页面层) 功能层: pages 封装页面的. 把页面封装成类.类中包含:属性和方法 把页面上的界面元素定义成类的属
-
关于Python Selenium自动化导出新版WOS(web of science)检索结果的问题
selenium 介绍 selenium 是一个 web 的自动化测试工具,不少学习功能自动化的同学开始首选 selenium ,因为它相比 QTP 有诸多有点: 免费,也不用再为破解 QTP 而大伤脑筋 小巧,对于不同的语言它只是一个包而已,而 QTP 需要下载安装1个多 G 的程序. 这也是最重要的一点,不管你以前更熟悉 C. java.ruby.python.或都是 C# ,你都可以通过 selenium 完成自动化测试,而 QTP 只支持 VBS 支持多平台:windows.linux.
-
po+selenium+unittest自动化测试项目实战
目录 一.项目工程目录: 二.具体工程文件代码: 一.项目工程目录: 二.具体工程文件代码: 1.新建一个包名:common(用于存放基本函数封装) (1)在common包下新建一个base.py文件,作用:页面操作封装.base.py文件代码如下: # coding=utf-8 """ ------------------------------------ @Time : 2020/01/15 @Auth : Anker @File : base.py @Descript
-
selenium自动化测试简单准备
目录 下载驱动器 chrome版本查看 基本函数 练习一(简单网页注册) 练习二 练习三 下载驱动器 http://chromedriver.storage.googleapis.com/index.html 下载与谷歌版本相同或最近版本. chrome版本查看 帮助中查看 导包 from selenium import webdriver 创建浏览器对象(以chrome为例) driverpath = r' '# 驱动器路径(chromedriver.exe) driver = webdriv
-
一篇文章带你了解Python之Selenium自动化爬虫
目录 Python之Selenium自动化爬虫 0.介绍 1.安装 2.下载浏览器驱动 3.实例 4.开启无头模式 5.保存页面截图 6.模拟输入和点击 a.根据文本值查找节点 b.获取当前节点的文本 c.打印当前网页的一些信息 d.关闭浏览器 e.模拟鼠标滚动 7.ChromeOptions 8.验证滑块移动 9.打开多窗口和页面切换 10.Cookie操作 11.模拟登录 12.使用代理 14.更换UA 15.鼠标悬停 16.优缺点 总结 Python之Selenium自动化爬虫 0.介绍
-
学习Python selenium自动化网页抓取器
直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击.跳转页面.搜索框的输入.页面的价值数据存储.mongodb自动id标识等等等. 1.首先介绍一下 Python selenium ---自动化测试工具,用来控制浏览器来对网页的操作,在爬虫中与BeautifulSoup结合那就是天衣无缝,除去国外的一些变态的验证网页,对于图片验证码我有自己写的破解图片验证码的源代码,成功率在85%. 详情请咨询QQ群--607021567(这不算广告,群里有好多P
-
Python + selenium自动化环境搭建的完整步骤
前言 本文主要介绍了关于Python+selenium自动化环境搭建的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 Python +selenium+googledriver 小白的血泪安装使,不停的总结写心得是理解透彻的毕竟之路 一,python的安装: 首先去Python的官网下载安装包:https://www.python.org/ ,大家也可以通过我们进行下载://www.jb51.net/softs/415916.html 2.下载完成后如下图所示 3.双
-
Python selenium 自动化脚本打包成一个exe文件(推荐)
目标 打包Python selenium 自动化脚本(如下run.py文件)为exe执行文件,使之可以直接在未安装python环境的windows下运行 run.py文件源码: 文件路径:D:\gongcheng 注:chromedriver.exe 文件在D:\gongcheng目录下 #!/usr/bin/python3 # encoding:utf-8 from selenium import webdriver import time as t brw = webdriver.Chrom
-
python+selenium自动化框架搭建的方法步骤
环境及使用软件信息 python 3 selenium 3.13.0 xlrd 1.1.0 chromedriver HTMLTestRunner 说明: selenium/xlrd只需要再python环境下使用pip install 名称即可进行对应的安装. 安装完成后可使用pip list查看自己的安装列表信息. chromedriver:版本需和自己的chrome浏览器对应,百度下载. 作用:对chrome浏览器进行驱动. HTMLTestRunner:HTMLTestRunner是Pyt
-
Python Selenium自动化获取页面信息的方法
1.获取页面title title:获取当前页面的标题显示的字段 from selenium import webdriver import time browser = webdriver.Chrome() browser.get('https://www.baidu.com') #打印网页标题 print(browser.title) #输出内容:百度一下,你就知道 2.获取页面URL current_url:获取当前页面的URL from selenium import webdriver
-
python+selenium自动化实战携带cookies模拟登陆微博
首先获取cookies,使用手机扫码登录斗鱼,然后利用网页cookies保存在本地 有些同学可能会问,这不是相当于自己登录了吗,还模拟什么呢,其实来说这是一次获取cookies可以使用很久 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/12/29 16:27 # @Author : huni # @File : 微博cookies.py # @Software: PyCharm from selenium import
-
Python+selenium 自动化快手短视频发布的实现过程
第一章:效果展示 ① 效果展示 ② 素材展示 一个为视频,另一个为像素大小不小于视频的封面. 第二章:实现过程 ① 调用已启用的浏览器 通过调用已启用的浏览器,可以实现直接跳过每次的登录过程. from selenium import webdriver options = webdriver.ChromeOptions() options.add_experimental_option("debuggerAddress", "127.0.0.1:5003") dr
-
Python+Selenium自动化环境搭建与操作基础详解
目录 一.环境搭建 1.python安装 2.pycharm下载安装 3.selenium下载安装 4.浏览器驱动下载安装 二.Selenium简介 (1)SeleniumIDE (2)SeleniumRC (3)SeleniumWebDriver (4)SeleniumGrid 三.常用方法 1.浏览器操作 2.如何获取页面元素 3.查找定位页面元素的方法 4.操作方法 5.下拉框操作 6.WINDOS弹窗 7.iframe内嵌页面处理 8.上传文件 9.切换页面 10.截图 11.等待时间