python pandas处理excel表格数据的常用方法总结
目录
- 前言
- 1、读取xlsx表格:pd.read_excel()
- 2、获取表格的数据大小:shape
- 3、索引数据的方法:[ ] / loc[] / iloc[]
- 4、判断数据为空:np.isnan() / pd.isnull()
- 5、查找符合条件的数据
- 6、修改元素值:replace()
- 7、增加数据:[ ]
- 8、删除数据:del() / drop()
- 9、保存到excel文件:to_excel()
- 总结
前言
最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了个脚本自动吧原始导出的成绩誊写到老师给的名单中了哈哈哈,这里就记录下用到的pandas处理excel的常用方式。(注意:只适用于.xlsx类型的文件)
1、读取xlsx表格:pd.read_excel()
原始内容如下:
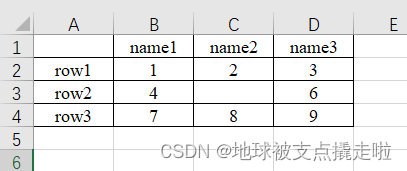
a)读取第n个Sheet(子表,在左下方可以查看或增删子表)的数据
import pandas as pd # 每次都需要修改的路径 path = "test.xlsx" # sheet_name默认为0,即读取第一个sheet的数据 sheet = pd.read_excel(path, sheet_name=0) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 """
可以注意到,原始表格左上角没有填入内容,读取的结果是“Unnamed: 0” ,这是由于read_excel函数会默认把表格的第一行为列索引名。另外,对于行索引名来说,默认从第二行开始编号(因为默认第一行是列索引名,所以默认第一行不是数据),如果不特意指定,则自动从0开始编号,如下。
sheet = pd.read_excel(path) # 查看列索引名,返回列表形式 print(sheet.columns.values) # 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式 print(sheet.index.values) """ ['Unnamed: 0' 'name1' 'name2' 'name3'] [0 1 2] """
b)列索引名还可以自定义,如下:
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4']) print(sheet) # 查看列索引名,返回列表形式 print(sheet.columns.values) """ col1 col2 col3 col4 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 ['col1' 'col2' 'col3' 'col4'] """
c)也可以指定第n列为行索引名,如下:
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""
d)读取时跳过第n行的数据
# 跳过第2行的数据(第一行索引为0) sheet = pd.read_excel(path, skiprows=[1]) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row2 4 NaN 6 1 row3 7 8.0 9 """
2、获取表格的数据大小:shape
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""
3、索引数据的方法:[ ] / loc[] / iloc[]
1、直接加方括号索引
可以使用方括号加列名的方式 [col_name] 来提取某列的数据,然后再用方括号加索引数字 [index] 来索引这列的具体位置的值。这里索引名为name1的列,然后打印位于该列第1行(索引是1)位置的数据:4,如下:
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name1'] print(col) # 打印该列第二个数据 print(col[1]) # 4 """ 0 1 1 4 2 7 Name: name1, dtype: int64 4 """
2、iloc方法,按整数编号索引
使用 sheet.iloc[ ] 索引,方括号内为行列的整数位置编号(除去作为行索引的那一列和作为列索引的哪一行后,从 0 开始编号)。
a)sheet.iloc[1, 2] :提取第2行第3列数据。第一个是行索引,第二个是列索引
b)sheet.iloc[0: 2] :提取前两行数据
c)sheet.iloc[0:2, 0:2] :通过分片的方式提取 前两行 的 前两列 数据
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = sheet.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""
3、loc方法,按行列名称索引
使用 sheet.loc[ ] 索引,方括号内为行列的名称字符串。具体使用方式同 iloc ,只是把 iloc 的整数索引替换成了行列的名称索引。这种索引方式用起来更直观。
注意:iloc[1: 2] 是不包含2的,但是 loc['row1': 'row2'] 是包含 'row2' 的。
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""
4、判断数据为空:np.isnan() / pd.isnull()
1、使用 numpy 库的 isnan() 或 pandas 库的 isnull() 方法判断是否等于 nan 。
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name2'] print(np.isnan(col[1])) # True print(pd.isnull(col[1])) # True """ True True """
2、使用 str() 转为字符串,判断是否等于 'nan' 。
sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""
5、查找符合条件的数据
下面的代码意会一下吧
# 提取name1 == 1 的行
mask = (sheet['name1'] == 1)
x = sheet.loc[mask]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""
6、修改元素值:replace()
sheet['name2'].replace(2, 100, inplace=True) :把 name2 列的元素 2 改为元素 100,原位操作。
sheet['name2'].replace(2, 100, inplace=True)
print(sheet)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""
sheet['name2'].replace(np.nan, 100, inplace=True) :把 name2 列的空元素(nan)改为元素 100,原位操作。
import numpy as np
sheet['name2'].replace(np.nan, 100, inplace=True)
print(sheet)
print(type(sheet.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""
7、增加数据:[ ]
增加列,直接使用中括号 [ 要添加的名字 ] 添加。
sheet['name_add'] = [55, 66, 77] :添加名为 name_add 的列,值为[55, 66, 77]
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('====================================')
# 添加名为 name_add 的列,值为[55, 66, 77]
sheet['name_add'] = [55, 66, 77]
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name_add
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""
8、删除数据:del() / drop()
a)del(sheet['name3']) :使用 del 方法删除
sheet = pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(sheet['name3'])
print(sheet)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""
b)sheet.drop('row1', axis=0)
使用 drop 方法删除 row1 行,删除列的话对应的 axis=1。
当 inplace 参数为 True 时,不会返回参数,直接在原数据上删除
当 inplace 参数为 False (默认)时不会修改原数据,而是返回修改后的数据
sheet.drop('row1', axis=0, inplace=True)
print(sheet)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""
c)sheet.drop(labels=['name1', 'name2'], axis=1)
使用 label=[ ] 参数可以删除多行或多列
# 删除多列,默认 inplace 参数位 False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""
9、保存到excel文件:to_excel()
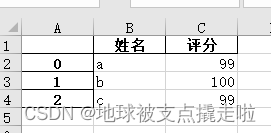
1、把 pandas 格式的数据另存为 .xlsx 文件
names = ['a', 'b', 'c']
scores = [99, 100, 99]
result_excel = pd.DataFrame()
result_excel["姓名"] = names
result_excel["评分"] = scores
# 写入excel
result_excel.to_excel('test3.xlsx')
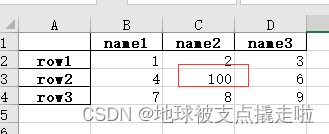
2、把改好的 excel 文件另存为 .xlsx 文件。
比如修改原表格中的 nan 为 100 后,保存文件:
import numpy as np
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
sheet['name2'].replace(np.nan, 100, inplace=True)
sheet.to_excel('test2.xlsx')
打开 test2.xlsx 结果如下:
总结
到此这篇关于python pandas处理excel表格数据的常用方法的文章就介绍到这了,更多相关pandas处理excel数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pandas数据分析之批量拆分/合并Excel
目录 前言 一.假造数据 二.程序演示 1.将一个大Excel等份拆成多个Excel 2.合并多个小Excel到一个大Excel 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中数据的合并(concat和append) 将一个大的Excel等份拆成多个Excel将多个小Excel合并成一个大的Excel并且标记来源 一.假造数据 work_dir="./datas" splits_dir=f"{work_dir}/
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
python读写excel数据--pandas详解
目录 一.读写excel数据 1.1 读: 1.2写: 二.举例 2.1 要求 2.2 实现 总结 一.读写excel数据 利用pandas可以很方便的读写excel数据 1.1 读: data_in = pd.read_excel('M2FENZISHI.xlsx') 1.2写: 首先要创建数据框 # example df = pd.DataFrame({'A':[0,1,2]}) writer = pd.ExcelWriter('test.xlsx') #name of excel file
-
python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
Python入门之使用pandas分析excel数据
1.问题 在python中,读写excel数据方法很多,比如xlrd.xlwt和openpyxl,实际上限制比较多,不是很方便.比如openpyxl也不支持csv格式.有没有更好的方法? 2.方案 更好的方法可以使用pandas,虽然pandas不是专门处理excel数据,但处理excel数据确实很方便. 本文使用excel的数据来自网络,数据内容如下: 2.1.安装 使用pip进行安装. pip3 install pandas 导入pandas: import pandas as pd 下文使
-
Python pandas如何向excel添加数据
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas可以写入一个或者工作簿,两种方法介绍如下: 1.如果是将整个DafaFrame写入excel,则调用to_excel()方法即可实现,示例代码如下: # output为要保存的Dataframe output.to_excel('保存路径 + 文件名.xlsx') 2.有多个数据需要写入多个exce
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
Python Pandas读取Excel日期数据的异常处理方法
目录 异常描述 出现原因 解决方案:修改自定义格式 pandas直接解析Excel数值为日期 总结 异常描述 有时我们的Excel有一个调整过自定义格式的日期字段: 当我们用pandas读取时却是这样的效果: 不管如何指定参数都无效. 出现原因 没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值. 解决方案:修改自定义格式 可以修改为系统内置的自定义格式: 或者在自定义格式上补充负数的定义: 增加;@即可 p
-
python使用xlsx和pandas处理Excel表格的操作步骤
目录 一.使用xls和xlsx处理Excel表格 1.1 用openpyxl模块打开Excel文档,查看所有sheet表 1.2 通过sheet名称获取表格 1.3 获取活动表的获取行数和列数 读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file: not supported 二.使用pandas读取xlsx 2.1 读取数据 2.2 使用pandas查找两个列表中相同的元素 解决ValueError: Excel file format cannot
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
利用Python改正excel表格数据
目录 一.前言 二.代码实现及讲解 1.模块的导入 2.获取“数据原表”中数据 3.获取生产记录更新表中的日期和材料 4.对生产数据更新表中数据的修改 5.最后,调用函数并保存数据 三.效果展示 四.结尾 一.前言 大家好,今天我来介绍我接一个Python单子.我完成这个单子前后不到2小时.首先我接到这个单子的想法是处理Excel表,在两个表之间建立联系,并通过项目需求,修改excel表中的数据.我是运用面向过程写的,将每一步都放在了不同的函数中,下面让我来介绍一下我是怎么通过自己的思路一步一步
-
Python导入Excel表格数据并以字典dict格式保存的操作方法
本文介绍基于Python语言,将一个Excel表格文件中的数据导入到Python中,并将其通过字典格式来存储的方法~ 本文介绍基于Python语言,将一个Excel表格文件中的数据导入到Python中,并将其通过字典格式来存储的方法. 我们以如下所示的一个表格(.xlsx格式)作为简单的示例.其中,表格共有两列,第一列为学号,第二列为姓名,且每一行的学号都不重复:同时表格的第一行为表头. 假设我们需要将第一列的学号数据作为字典的键,而第二列姓名数据作为字典的值. 首先,导入必要的
-
python Pandas 读取txt表格的实例
运行环境 Python 2.7 操作实例 1.原始文本格式:空格分隔的txt,例如 2016-03-22 00:06:24.4463094 中文测试字符 2016-03-22 00:06:32.4565680 需要编辑encoding 2016-03-22 00:06:32.6835965 abc 2016-03-22 00:06:32.8041945 egb 2.pandas 读取数据 import pandas as pd data = pd.read_table('Z:/test.txt'
-
Python实现合并excel表格的方法分析
本文实例讲述了Python实现合并excel表格的方法.分享给大家供大家参考,具体如下: 需求 将一个文件夹中的excel表格合并成我们想要的形式,主要要pandas中的concat()函数 思路 用os库将所需要处理的表格放到同一个列表中,然后遍历列表,依次把所有文件纵向连接起来. 最开始的第一种思路是先拿一个文件出来,然后让这个文件依次去和列表中的剩余文件合并: 第二种是用文件夹中第一个文件和剩余的文件合并,使用range(1,len(file)),可以省去单独取第一个文件的步骤. 遇到的问
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成