基于HTTP浏览器缓存机制全面解析
目录
- 什么是浏览器缓存
- 非HTTP协议定义的缓存机制
- 缓存流程图
- HTTP缓存机制
- 服务端如何判断缓存已失效
- Last-Modified/If-Modified-Since
- Etag/If-None-Match
- 为什么有了Last-Modified还要Etag?
- 200 OK(from cache)与304 Not Modified的区别
- 200 OK( from cache ) 出现操作:
- 304 Not Modified 出现操作:
- 缓存的不同来源
- 不能被缓存的请求
什么是浏览器缓存
Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本。缓存会根据进来的请求保存输出内容的副本;当下一个请求来到的时候,如果是相同的URL,缓存会根据缓存机制决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。
比较常见的就是浏览器会缓存访问过网站的网页,当再次访问这个URL地址的时候,如果网页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。
只有当网站明确标识资源已经更新,浏览器才会再次下载网页。浏览器和网站服务器是根据缓存机制进行缓存的
非HTTP协议定义的缓存机制
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的节点中加入标签
<meta http-equiv="Pragma" content="no-cache">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。
缓存流程图
利用浏览器缓存的过程:
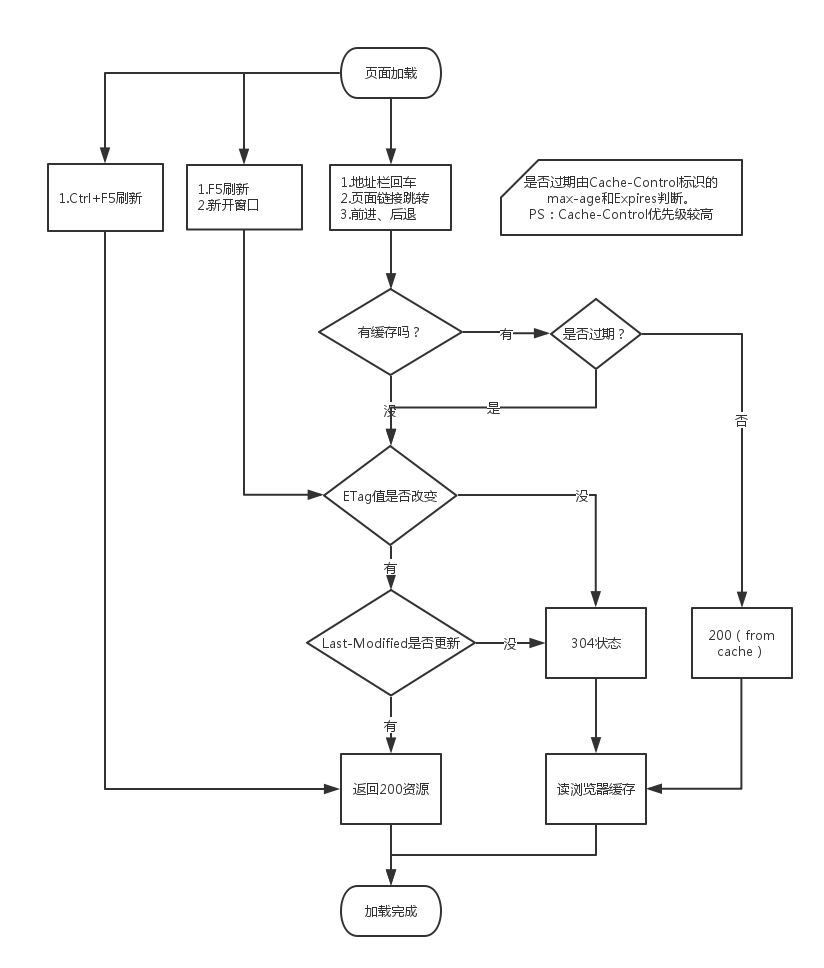
HTTP缓存机制
根据Response Header里面的Cache-Control和Expires这两个属性,当两个都存在时,Cache-Control优先级较高。
Cache-Control
该字段用于控制浏览器在什么情况下直接使用本地缓存而不向服务器发送请求。一般具有以下值:
Public:指示响应可被任何缓存区缓存。Private:指示对于单个用户的整个或部分响应消息,不能被共享缓存处理。这允许服务器仅仅描述当用户的部分响应消息,此响应消息对于其他用户的请求无效。no-cache:指示请求或响应消息不能缓存。no-store:用于防止重要的信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存。max-age:指示浏览器可以接收生存期不大于指定时间(以秒为单位)的响应。min-fresh:指示浏览器可以接收响应时间小于当前时间加上指定时间的响应。max-stale:指示浏览器可以接收超出超时期间的响应消息。如果指定max-stale消息的值,那么浏览器可以接收超出超时期指定值之内的响应消息。
Expires(石器时代的缓存机制)
Expires 头部字段提供一个日期和时间,在该日期前的所有对该资源的请求都会直接使用浏览器缓存而不用向服务器请求。
例如:Expires: Sun, 08 Nov 2009 03:37:26 GMT
注意:
- cache-control max-age 和 max-stale将覆盖Expires header。
- 使用Expires存在服务器端时间和浏览器时间不一致的问题。
- 另外有人说Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1。
服务端如何判断缓存已失效
服务端通过If-Modified-Since(Last-Modified)和If-None-Match(Etag)这两个属性的值来判断缓存是否失效的。
Last-Modified/If-Modified-Since
Last-Modified/If-Modified-Since要配合Cache-Control使用。
Last-Modified:响应资源的最后修改时间。
If-Modified-Since:当缓存过期时,发现资源具有Last-Modified声明,则在请求头带上If-Modified-Since(值就是Last-Modified)。服务器收到请求后发现有头If-Modified-Since则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应HTTP 200整片资源内容(写在响应消息包体内);若最后修改时间较旧,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
Etag/If-None-Match
Etag/If-None-Match也要配合Cache-Control使用。
Etag:资源在服务器的唯一标识(生成规则由服务器决定)。Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
If-None-Match:当缓存过期时,发现资源具有Etage声明,则在请求头带上If-None-Match(值就是Etag)。服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定返回200或304。
为什么有了Last-Modified还要Etag?
Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
- Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间。
- 如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存。
- 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形。
200 OK(from cache)与304 Not Modified的区别
200 OK( from cache )不向服务器发送请求,直接使用本地缓存文件。304 Not Modified则向服务器询问,若服务器认为浏览器的缓存版本还可用,那么便会返回304。
200 OK( from cache ) 出现操作:
1.地址栏回车
2.页面链接跳转
3.前进、后退
304 Not Modified 出现操作:
1.F5刷新
2.新开窗口
缓存的不同来源
from disk cache:从磁盘中获取缓存资源,等待下次访问时不需要重新下载资源,而直接从磁盘中获取。它的直接操作对象为CurlCacheManager。
from memory cache:从内存中获取资源,等待下次访问时不需要重新下载资源,而直接从内存中获取。
两者区别:当退出进程时,内存中的数据会被清空,而磁盘的数据不会,所以,当下次再进入该进程时,该进程仍可以从diskCache中获得数据,而memoryCache则不行。
不能被缓存的请求
当然并不是所有请求都能被缓存。
无法被浏览器缓存的请求:
- HTTP信息头中包含Cache-Control:no-cache,pragma:no-cache(HTTP1.0),或Cache-Control:max-age=0等告诉浏览器不用缓存的请求
- 需要根据Cookie,认证信息等决定输入内容的动态请求是不能被缓存的
- 经过HTTPS安全加密的请求
- POST请求无法被缓存
- HTTP响应头中不包含Last-Modified/Etag,也不包含Cache-Control/Expires的请求无法被缓存
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

浏览器缓存知识小结及应用分析
浏览器缓存,也就是客户端缓存,既是网页性能优化里面静态资源相关优化的一大利器,也是无数web开发人员在工作过程不可避免的一大问题,所以在产品开发的时候我们总是想办法避免缓存产生,而在产品发布之时又在想策略管理缓存提升网页的访问速度.了解浏览器的缓存命中原理,是开发web应用的基础,本文着眼于此,学习浏览器缓存的相关知识,总结缓存避免和缓存管理的方法,结合具体的场景说明缓存的相关问题.希望能对有需要的人有所帮助. 1. 浏览器缓存基本认识 它分为强缓存和协商缓存: 1)浏览器在加载资源时,先根据这
-
详解浏览器缓存和webpack缓存配置
浏览器缓存 浏览器缓存分为两种类型: 强缓存:也称为本地缓存,不向服务器发送请求,直接使用客户端本地缓存数据 协商缓存:也称304缓存,向服务器发送请求,由服务器判断请求文件是否发生改变.如果未发生改变,则返回304状态码,通知客户端直接使用本地缓存:如果发生改变,则直接返回请求文件. 浏览器缓存机制的过程如下: 强缓存(本地缓存) 强缓存是最彻底的缓存,无需向服务器发送请求,通常用于css.js.图片等静态资源.浏览器发送请求后会先判断本地是否有缓存.如果无缓存,则直接向服务器发送请求:如果有
-
解析浏览器端的AJAX缓存机制
AJAX的缓存是由浏览器维持的,对于发向服务器的某个url,ajax仅在第一次请求时与服务器交互信息,之后的请求中,ajax不再向服务器提交请求,而是直接从缓存中提取数据. 有些情况下,我们需要每一次都从服务器得到更新后数据.思路是让每次请求的url都不同,而又不影响正常应用:在url之后加入随机内容. e.g. url=url+"&"+Math.random(); Key points: 1.每次请求的url都不一样(ajax的缓存便不起作用) 2.不影响正常应用(最基本的)
-
详解浏览器的缓存机制
目录 前言 1 浏览器缓存 1.1 浏览器缓存 1.2 浏览器缓存的意义 2 缓存类型 2.1 第一次请求数据 2.2 强制缓存 2.3 协商缓存 2.4 强制缓存和协商缓存的关系 3 缓存相关header 3.1 强制缓存 3.2 协商缓存 3.3 缓存请求 4 实例分析 4.1 官网首页: 4.2 社区 4.3 云市场 4.4 个人中心 4.5 论坛 4.6 App 总结 前言 浏览器缓存是前端性能优化的重要一环,对于前端效率提升的重要性,不言而喻. 之前对于浏览器缓存也是一知半解,这次借着
-
基于HTTP浏览器缓存机制全面解析
目录 什么是浏览器缓存 非HTTP协议定义的缓存机制 缓存流程图 HTTP缓存机制 服务端如何判断缓存已失效 Last-Modified/If-Modified-Since Etag/If-None-Match 为什么有了Last-Modified还要Etag? 200 OK(from cache)与304 Not Modified的区别 200 OK( from cache ) 出现操作: 304 Not Modified 出现操作: 缓存的不同来源 不能被缓存的请求 什么是浏览器缓存 Web
-
Python 基于jwt实现认证机制流程解析
1.jwt的优缺点 jwt的优点: 1. 实现分布式的单点登陆非常方便 2. 数据实际保存在客户端,所以我们可以分担数据库或服务器的存储压力 jwt的缺点: 1. 数据保存在了客户端,我们服务端只认jwt,不识别客户端. 2. jwt可以设置过期时间,但是因为数据保存在了客户端,所以对于过期时间不好调整. 2.安装jwt pip install djangorestframework-jwt -i https://pypi.douban.com/simple 3.在settings.dev中 R
-
浅析IE浏览器关于ajax的缓存机制
IE浏览器对于同一个URL只返回相同结果.因为,在默认情况下,IE会缓存ajax的请求结果.对于同一个URL地址,在缓存过期之前,只有第一次请求会真正发送到服务端.大多数情况下,我们使用ajax是希望实现局部刷新的,所以这就牵扯到一个改进的问题. 如果想每次都获取到最新数据,我们只需保证每次传入的URL不一样.最简单的方法就是通过给url拼接参数.利用math函数的random()方法生成随机数. 比如访问百度www.baidu.com,我们就可以把地址写成www.baidu.com?t=Mat
-
Hibernate缓存机制实例代码解析
本文研究的主要是Hibernate缓存机制的相关内容,具体如下. 演示项目: Student.java: public class Student { /*学生ID*/ private int id; /*学生姓名*/ private String name; /*学生和班级的关系*/ private Classes classes; //省略setter和getter方法 } Classes.java: public class Classes { /*班级ID*/ private int i
-
localStorage的黑科技-js和css缓存机制
一.发现黑科技的起因 今天在微信公众号看到一篇技术博文,想用印象笔记收藏,所以发送了文章链接到pc上.然后习惯性地打开控制台,看看源码,想了解下最近微信用了什么新技术. 呵呵,以下勾起了我侦探的欲望.页面加载后的异常点就是只加载了一个js,如下图所示: 我很诧异,为什么已经开启了Disable cache,js只加载了一个,而且体积这么小.接着,我按住Ctrl+O进行资源文件查找,发现我被"忽悠"了.其实根本就不止一个js文件. 脑袋里灵光一闪,不会是用localStorage做了缓存
-
asp.net 客户端浏览器缓存的Http头介绍
让浏览器做缓存需要给浏览器发送指定的Http头,告诉浏览器缓存多长时间,或者坚决不要缓存.作为.net的程序员,其实我们一直都在用这种方法,在OutputCache指令中指定缓存的Location为Client时,其实就是给浏览器发送了一个Http头,告诉浏览器这个Url要缓存多长时间,最后修改的时间. 微软在OutputCacheModule中对这些缓存用到的Http头给我们进行了很好的封装,但是了解这些Http头可以更灵活的使用它们. 和客户端缓存相关的Http头有以下几个,分别是: 1.