分享python机器学习中应用所产生的聚类数据集方法
目录
- 01直接生成
- 一、基础类型
- 1、月牙形数据集合
- 2、方形数据集
- 3、螺旋形数据集合
- 02样本生成器
- 一、基础数据集
- 1、点簇形数据集合
- 2、线簇形数据集合
- 3、环形数据集合
- 4、月牙数据集合
- 测试结论

01直接生成
这类方法是利用基本程序软件包numpy的随机数产生方法来生成各类用于聚类算法数据集合,也是自行制作轮子的生成方法。
一、基础类型
1、月牙形数据集合
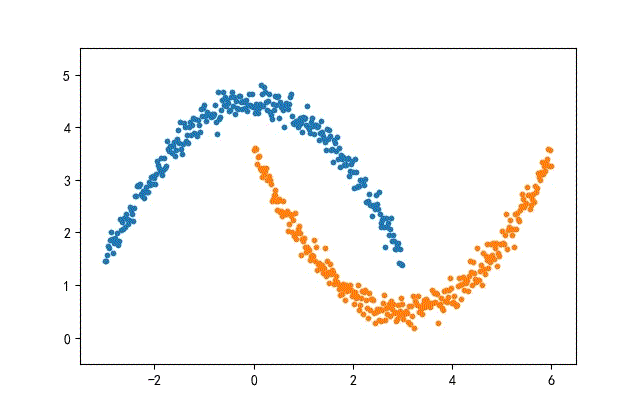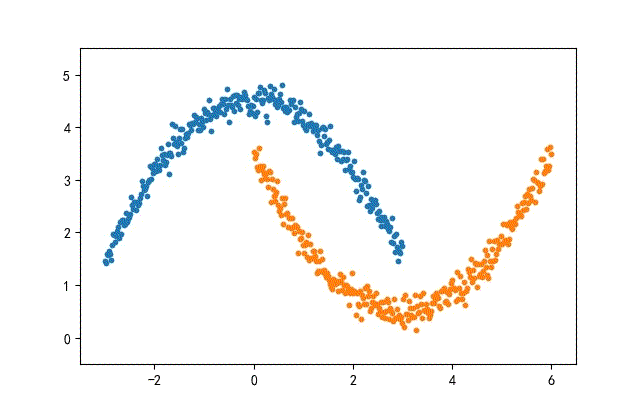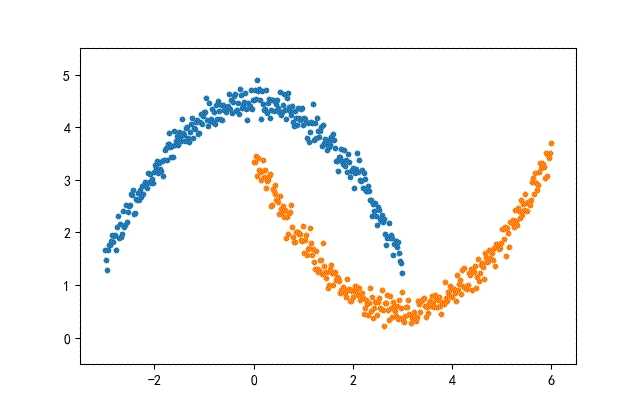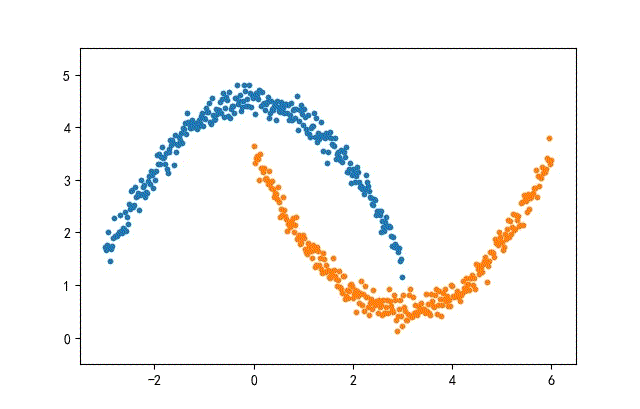
from headm import *
import numpy as np
pltgif = PlotGIF()
def moon2Data(datanum):
x1 = linspace(-3, 3, datanum)
noise = np.random.randn(datanum) * 0.15
y1 = -square(x1) / 3 + 4.5 + nois
x2 = linspace(0, 6, datanum)
noise = np.random.randn(datanum) * 0.15
y2 = square(x2 - 3) / 3 + 0.5 + noise
plt.clf()
plt.axis([-3.5, 6.5, -.5, 5.5])
plt.scatter(x1, y1, s=10)
plt.scatter(x2, y2, s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
moon2Data(300)
pltgif.save(r'd:\temp\GIF1.GIF')
2、方形数据集
from headm import *
import numpy as np
pltgif = PlotGIF()
def moon2Data(datanum):
x = np.random.rand(datanum, 2)
condition1 = x[:, 1] <= x[:, 0]
condition2 = x[:, 1] <= (1-x[:, 0])
index1 = np.where(condition1 & condition2)
x1 = x[index1]
x = np.delete(x, index1, axis=0)
index2 = np.where(x[:, 0] <= 0.5)
x2 = x[index2]
x3 = np.delete(x, index2, axis=0)
plt.clf()
plt.scatter(x1[:, 0], x1[:, 1], s=10)
plt.scatter(x2[:, 0], x2[:, 1], s=10)
plt.scatter(x3[:, 0], x3[:, 1], s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
moon2Data(1000)
pltgif.save(r'd:\temp\GIF1.GIF')
3、螺旋形数据集合
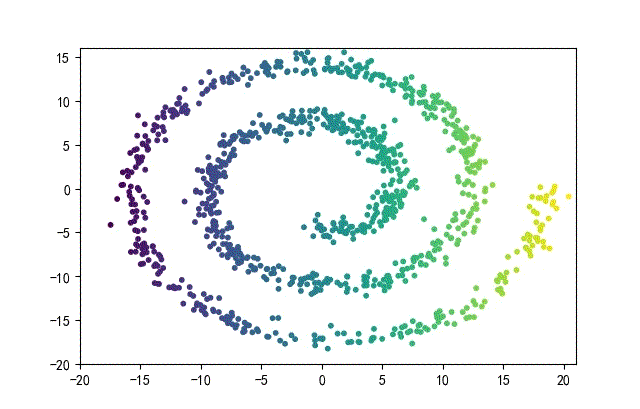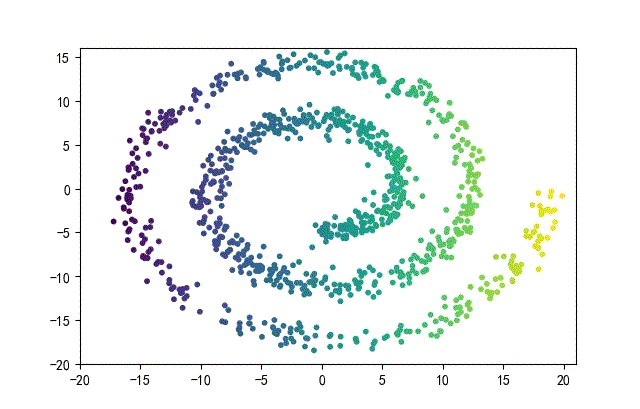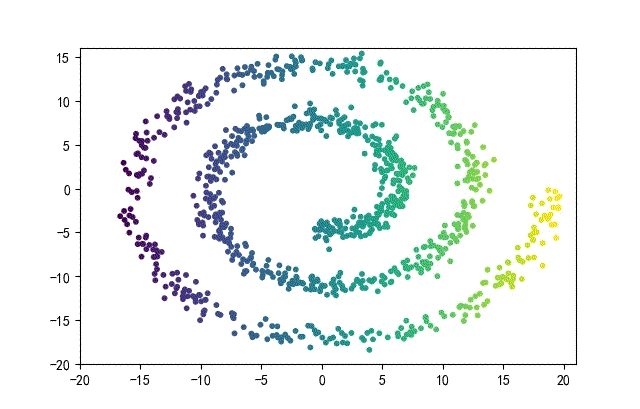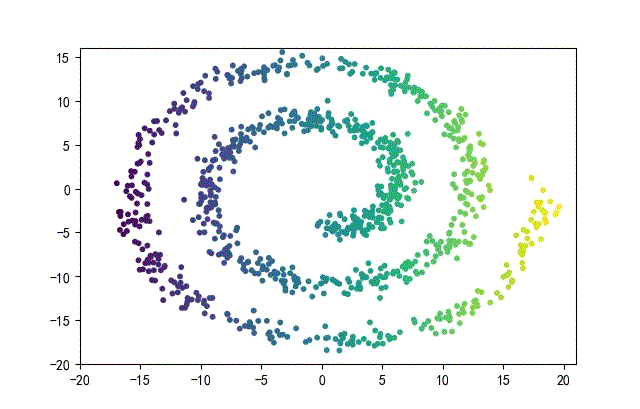
from headm import *
import numpy as np
pltgif = PlotGIF()
def randData(datanum):
t = 1.5 * pi * (1+3*random.rand(1, datanum))
x = t * cos(t)
y = t * sin(t)
X = concatenate((x,y))
X += 0.7 * random.randn(2, datanum)
X = X.T
norm = plt.Normalize(y.min(), y.max())
plt.clf()
plt.scatter(X[:, 0], X[:, 1], s=10, c=norm(X[:,0]), cmap='viridis')
plt.axis([-20, 21, -20, 16])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\GIF1.GIF')
下面的知识螺旋线,没有随机移动的点。
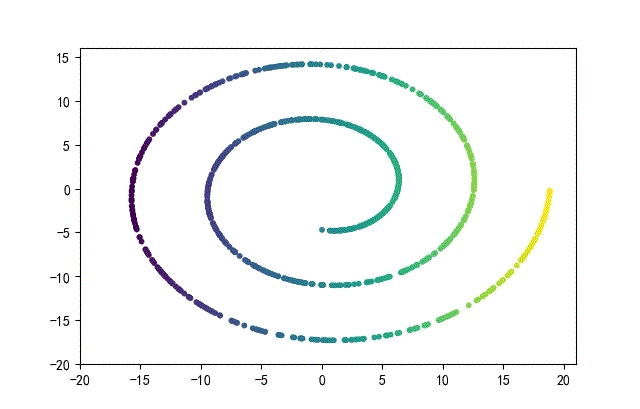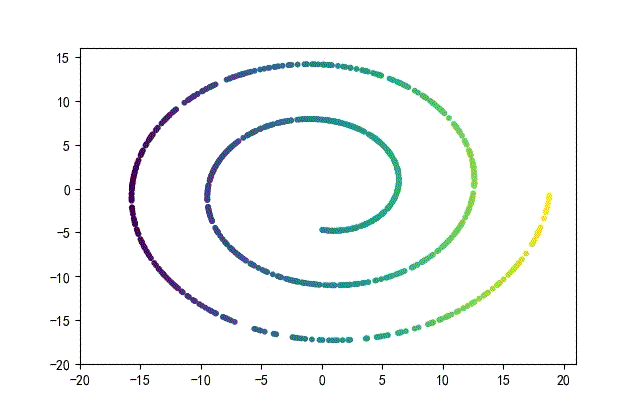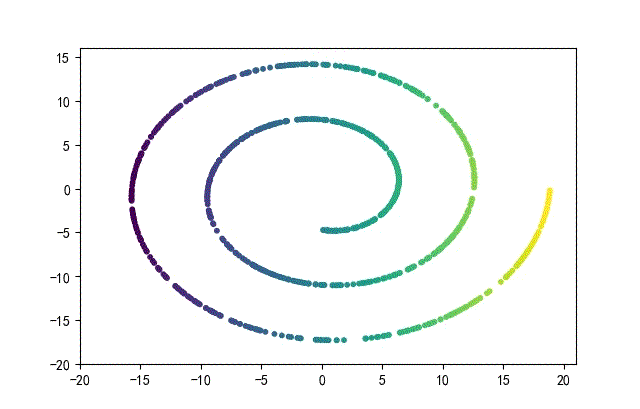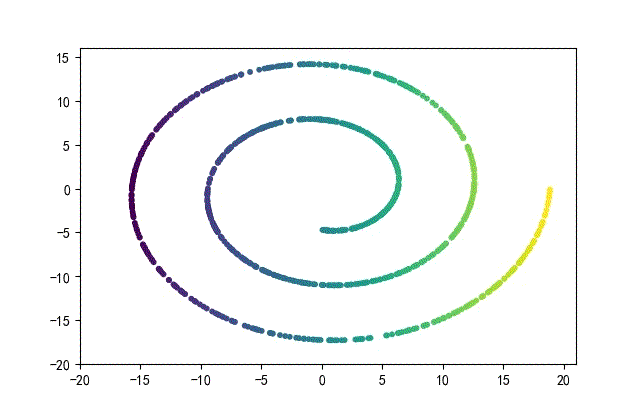
将随机幅值从原来的0.7增大到1.5,对应的数据集合为:
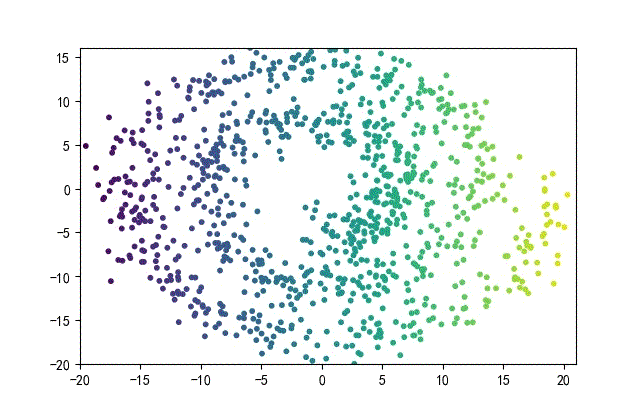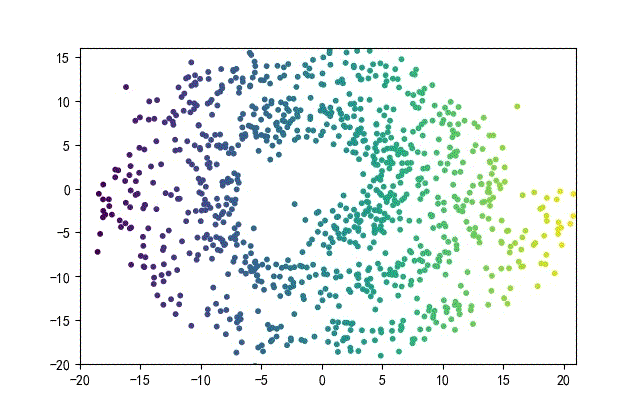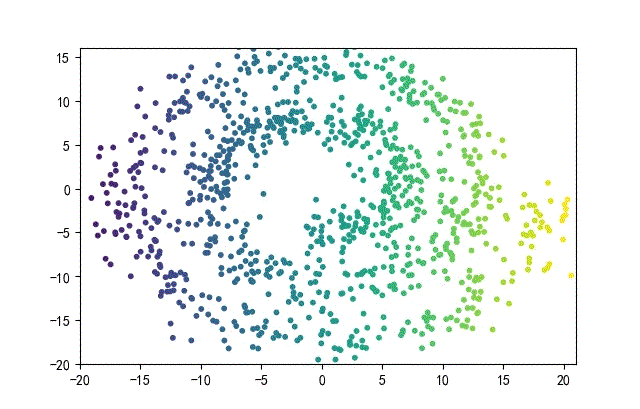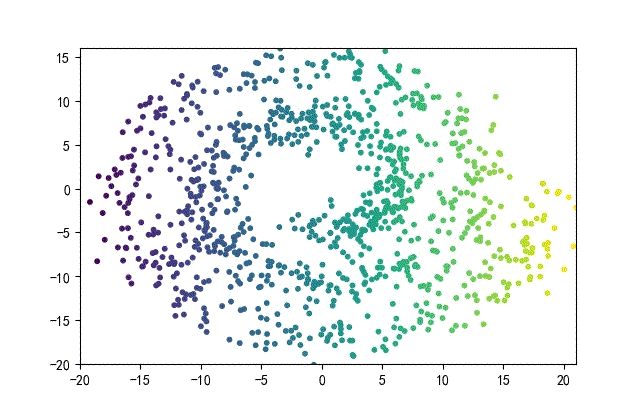

02样本生成器
利用sklearn.datasets自带的样本生成器来生成相应的数据集合。
一、基础数据集
1、点簇形数据集合

from headm import *
from sklearn.datasets import make_blobs
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_blobs(n_samples=datanum, n_features=2, centers=3, random_state=random.randint(0, 1000))
plt.clf()
plt.scatter(x1[:,0], x1[:, 1], c=y1, s=10)
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(300)
pltgif.save(r'd:\temp\gif1.gif')
绘制三簇点集合,也可以使用如下的语句:
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10) plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10) plt.scatter(x1[y1==2][:,0], x1[y1==2][:,1], s=10)
2、线簇形数据集合
生成代码,只要在前面的x1后面使用旋转矩阵。
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]] x1 = dot(x1, transformation)
其中转换矩阵的特征值与特征向量为:
- 特征值:[0.20581711.25506068]
- 特征向量:[[-0.845237740.7015526][-0.53439045-0.71261768]]
3、环形数据集合
from headm import *
from sklearn.datasets import make_circles
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_circles(n_samples=datanum, noise=0.07, random_state=random.randint(0, 1000), factor=0.6)
plt.clf()
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10)
plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10)
plt.axis([-1.2, 1.2, -1.2, 1.2])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\gif1.gif')
4、月牙数据集合
from headm import *
from sklearn.datasets import make_moons
pltgif = PlotGIF()
def randData(datanum):
x1,y1 = make_moons(n_samples=datanum, noise=0.07, random_state=random.randint(0, 1000))
plt.clf()
plt.scatter(x1[y1==0][:,0], x1[y1==0][:,1], s=10)
plt.scatter(x1[y1==1][:,0], x1[y1==1][:,1], s=10)
plt.axis([-1.5, 2.5, -1, 1.5])
plt.draw()
plt.pause(.1)
pltgif.append(plt)
for _ in range(20):
randData(1000)
pltgif.save(r'd:\temp\gif1.gif')
测试结论
sklearn里面还有好多函数来自定制数据,除此之外还可以使用numpy生成,然后通过高级索引进行划分,最好结合着matplotlib中的cmap来做颜色映射,这样可以做出好玩又好看的数据集,希望大家以后多多支持我们!
相关推荐
-
机器学习10大经典算法详解
本文为大家分享了机器学习10大经典算法,供大家参考,具体内容如下 1.C4.5 C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进: 1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足: 2)在树构造过程中进行剪枝: 3)能够完成对连续属性的离散化处理: 4)能够对不完整数据进行处理. C4.5算法有如下优点:产生的分类规则易于理解,准确率较高.其缺点是:在构造树的过
-
python机器学习实战之K均值聚类
本文实例为大家分享了python K均值聚类的具体代码,供大家参考,具体内容如下 #-*- coding:utf-8 -*- #!/usr/bin/python ''''' k Means K均值聚类 ''' # 测试 # K均值聚类 import kMeans as KM KM.kMeansTest() # 二分K均值聚类 import kMeans as KM KM.biKMeansTest() # 地理位置 二分K均值聚类 import kMeans as KM KM.clusterClu
-

如何用 Python 处理不平衡数据集
1. 什么是数据不平衡 所谓的数据不平衡(imbalanced data)是指数据集中各个类别的数量分布不均衡:不平衡数据在现实任务中十分的常见.如 信用卡欺诈数据:99%都是正常的数据, 1%是欺诈数据 贷款逾期数据 不平衡数据一般是由于数据产生的原因导致的,类别少的样本通常是发生的频率低,需要很长的周期进行采集. 在机器学习任务(如分类问题)中,不平衡数据会导致训练的模型预测的结果会偏向于样本数量多的类别,这个时候除了要选择合适的评估指标外,想要提升模型的性能,就要对数据和模型做一些预处理.
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
分享python机器学习中应用所产生的聚类数据集方法
目录 01直接生成 一.基础类型 1.月牙形数据集合 2.方形数据集 3.螺旋形数据集合 02样本生成器 一.基础数据集 1.点簇形数据集合 2.线簇形数据集合 3.环形数据集合 4.月牙数据集合 测试结论 01直接生成 这类方法是利用基本程序软件包numpy的随机数产生方法来生成各类用于聚类算法数据集合,也是自行制作轮子的生成方法. 一.基础类型 1.月牙形数据集合 from headm import * import numpy as np pltgif = PlotGIF() def mo
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
python 筛选数据集中列中value长度大于20的数据集方法
如果我有一个数据集,他的某个列名下面的value很长,我们需要筛选出,所有列名中value值字符串大于20的数据集. 其实比较简单啦,一句代码就可以搞定 #对该列进行强制的字符类型转换 df["token"] = df["token"].astype(str) #筛选df这个数据集下,token这个字段下面的value字符串长度大于20的 df= df[df['token'].str.len() >20] 以上这篇python 筛选数据集中列中value长度大
-
在python tkinter中Canvas实现进度条显示的方法
如下所示: from tkinter import * import time #更新进度条函数 def change_schedule(now_schedule,all_schedule): canvas.coords(fill_rec, (5, 5, 6 + (now_schedule/all_schedule)*100, 25)) root.update() x.set(str(round(now_schedule/all_schedule*100,2)) + '%') if round(
-
Python 获取中文字拼音首个字母的方法
Python:3.5 代码如下: def single_get_first(unicode1): str1 = unicode1.encode('gbk') try: ord(str1) return str1.decode('gbk') except: asc = str1[0] * 256 + str1[1] - 65536 if asc >= -20319 and asc <= -20284: return 'a' if asc >= -20283 and asc <= -1
-
Python 实现中值滤波、均值滤波的方法
红包: Lena椒盐噪声图片: # -*- coding: utf-8 -*- """ Created on Sat Oct 14 22:16:47 2017 @author: Don """ from tkinter import * from skimage import io import numpy as np im=io.imread('lena_sp.jpg', as_grey=True) im_copy_med = io.imrea
-
Python字符串中添加、插入特定字符的方法
分析 我们将添加.插入.删除定义为: 添加 : 在字符串的后面或者前面添加字符或者字符串 插入 : 在字符串之间插入特定字符 在Python中,字符串是不可变的.所以无法直接删除.插入字符串之间的特定字符. 所以想对字符串中字符进行操作的时候,需要将字符串转变为列表,列表是可变的,这样就可以实现对字符串中特定字符的操作. 1.添加字符实现 添加字符或字符串 如果想在字符串 土堆 后面或者前面添加 碎念 字符串. 可以使用 + 号实现字符串的连接,或者使用方法 .join() 来连接字符串. .j
-
在Python dataframe中出生日期转化为年龄的实现方法
我们在做数据挖掘项目或大数据竞赛时,如果个体是人的时候,获得的数据中可能有出生日期的Series,举个简单例子,比如这样的一些数: # -*- coding: utf-8 -*- import pandas as pd from pandas import Series, DataFrame import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline data = {'bi
-
Python Numpy中数据的常用保存与读取方法
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多. 下面就常用的保存数据到二进制文件和保存数据到文本文件进行介绍: 1.保存为二进制文件(.npy/.npz) numpy.save 保存一个数组到一个二进制的文件中,保存格式是.npy 参数介绍 numpy.save(file, arr, allow_pickle=True, fix_imports=True) file:文件名/文件路径 arr:要存