PyTorch数据读取的实现示例
前言
PyTorch作为一款深度学习框架,已经帮助我们实现了很多很多的功能了,包括数据的读取和转换了,那么这一章节就介绍一下PyTorch内置的数据读取模块吧
模块介绍
- pandas 用于方便操作含有字符串的表文件,如csv
- zipfile python内置的文件解压包
- cv2 用于图片处理的模块,读入的图片模块为BGR,N H W C
- torchvision.transforms 用于图片的操作库,比如随机裁剪、缩放、模糊等等,可用于数据的增广,但也不仅限于内置的图片操作,也可以自行进行图片数据的操作,这章也会讲解
- torch.utils.data.Dataset torch内置的对象类型
- torch.utils.data.DataLoader 和Dataset配合使用可以实现数据的加速读取和随机读取等等功能
import zipfile # 解压 import pandas as pd # 操作数据 import os # 操作文件或文件夹 import cv2 # 图像操作库 import matplotlib.pyplot as plt # 图像展示库 from torch.utils.data import Dataset # PyTorch内置对象 from torchvision import transforms # 图像增广转换库 PyTorch内置 import torch
初步读取数据
数据下载到此处
我们先初步编写一个脚本来实现图片的展示
# 解压文件到指定目录 def unzip_file(root_path, filename): full_path = os.path.join(root_path, filename) file = zipfile.ZipFile(full_path) file.extractall(root_path) unzip_file(root_path, zip_filename) # 读入csv文件 face_landmarks = pd.read_csv(os.path.join(extract_path, csv_filename)) # pandas读出的数据如想要操作索引 使用iloc image_name = face_landmarks.iloc[:,0] landmarks = face_landmarks.iloc[:,1:] # 展示 def show_face(extract_path, image_file, face_landmark): plt.imshow(plt.imread(os.path.join(extract_path, image_file)), cmap='gray') point_x = face_landmark.to_numpy()[0::2] point_y = face_landmark.to_numpy()[1::2] plt.scatter(point_x, point_y, c='r', s=6) show_face(extract_path, image_name.iloc[1], landmarks.iloc[1])
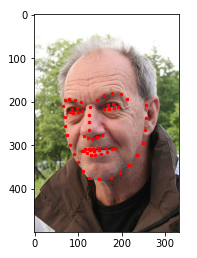
使用内置库来实现
实现MyDataset
使用内置库是我们的代码更加的规范,并且可读性也大大增加
继承Dataset,需要我们实现的有两个地方:
- 实现
__len__返回数据的长度,实例化调用len()时返回 __getitem__给定数据的索引返回对应索引的数据如:a[0]transform数据的额外操作时调用
class FaceDataset(Dataset):
def __init__(self, extract_path, csv_filename, transform=None):
super(FaceDataset, self).__init__()
self.extract_path = extract_path
self.csv_filename = csv_filename
self.transform = transform
self.face_landmarks = pd.read_csv(os.path.join(extract_path, csv_filename))
def __len__(self):
return len(self.face_landmarks)
def __getitem__(self, idx):
image_name = self.face_landmarks.iloc[idx,0]
landmarks = self.face_landmarks.iloc[idx,1:].astype('float32')
point_x = landmarks.to_numpy()[0::2]
point_y = landmarks.to_numpy()[1::2]
image = plt.imread(os.path.join(self.extract_path, image_name))
sample = {'image':image, 'point_x':point_x, 'point_y':point_y}
if self.transform is not None:
sample = self.transform(sample)
return sample
测试功能是否正常
face_dataset = FaceDataset(extract_path, csv_filename)
sample = face_dataset[0]
plt.imshow(sample['image'], cmap='gray')
plt.scatter(sample['point_x'], sample['point_y'], c='r', s=2)
plt.title('face')
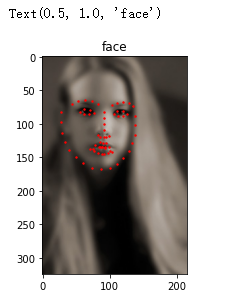
实现自己的数据处理模块
内置的在torchvision.transforms模块下,由于我们的数据结构不能满足内置模块的要求,我们就必须自己实现
图片的缩放,由于缩放后人脸的标注位置也应该发生对应的变化,所以要自己实现对应的变化
class Rescale(object):
def __init__(self, out_size):
assert isinstance(out_size,tuple) or isinstance(out_size,int), 'out size isinstance int or tuple'
self.out_size = out_size
def __call__(self, sample):
image, point_x, point_y = sample['image'], sample['point_x'], sample['point_y']
new_h, new_w = self.out_size if isinstance(self.out_size,tuple) else (self.out_size, self.out_size)
new_image = cv2.resize(image,(new_w, new_h))
h, w = image.shape[0:2]
new_y = new_h / h * point_y
new_x = new_w / w * point_x
return {'image':new_image, 'point_x':new_x, 'point_y':new_y}
将数据转换为torch认识的数据格式因此,就必须转换为tensor
注意: cv2和matplotlib读出的图片默认的shape为N H W C,而torch默认接受的是N C H W因此使用tanspose转换维度,torch转换多维度使用permute
class ToTensor(object):
def __call__(self, sample):
image, point_x, point_y = sample['image'], sample['point_x'], sample['point_y']
new_image = image.transpose((2,0,1))
return {'image':torch.from_numpy(new_image), 'point_x':torch.from_numpy(point_x), 'point_y':torch.from_numpy(point_y)}
测试
transform = transforms.Compose([Rescale((1024, 512)), ToTensor()])
face_dataset = FaceDataset(extract_path, csv_filename, transform=transform)
sample = face_dataset[0]
plt.imshow(sample['image'].permute((1,2,0)), cmap='gray')
plt.scatter(sample['point_x'], sample['point_y'], c='r', s=2)
plt.title('face')

使用Torch内置的loader加速读取数据
data_loader = DataLoader(face_dataset, batch_size=4, shuffle=True, num_workers=0) for i in data_loader: print(i['image'].shape) break
torch.Size([4, 3, 1024, 512])
注意: windows环境尽量不使用num_workers会发生报错
总结
这节使用内置的数据读取模块,帮助我们规范代码,也帮助我们简化代码,加速读取数据也可以加速训练,数据的增广可以大大的增加我们的训练精度,所以本节也是训练中比较重要环节
到此这篇关于PyTorch数据读取的实现示例的文章就介绍到这了,更多相关PyTorch数据读取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python、PyTorch图像读取与numpy转换实例
Tensor转为numpy np.array(Tensor) numpy转换为Tensor torch.Tensor(numpy.darray) PIL.Image.Image转换成numpy np.array(PIL.Image.Image) numpy 转换成PIL.Image.Image Image.fromarray(numpy.ndarray) 首先需要保证numpy.ndarray 转换成np.uint8型 numpy.astype(np.uint8),像素值[0,255]. 同时灰
-
pytorch读取图像数据转成opencv格式实例
pytorch读取图像数据转成opencv格式方法:先转成numpy通用的格式,再将其转换成opencv格式. pytorch读取的数据使用loaddata这类函数实现.pytorch网络输入图像的格式为(C, H, W),就是(通道数,高,宽)而numpy中图像的格式为(H,W,C). 那就将其通道调换一下.用到函数transpose. 转换方法如下 例如A 的格式为(c,h,w) 那么经过 A = A.transpose(1,2,0) 后就变成了(h,w,c)了 然后用语句 B= cv2.c
-
PyTorch读取Cifar数据集并显示图片的实例讲解
首先了解一下需要的几个类所在的package from torchvision import transforms, datasets as ds from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np #transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等. #DataLoader读入的数据类型是PIL.Image
-
Pytorch之保存读取模型实例
pytorch保存数据 pytorch保存数据的格式为.t7文件或者.pth文件,t7文件是沿用torch7中读取模型权重的方式.而pth文件是python中存储文件的常用格式.而在keras中则是使用.h5文件. # 保存模型示例代码 print('===> Saving models...') state = { 'state': model.state_dict(), 'epoch': epoch # 将epoch一并保存 } if not os.path.isdir('checkpoin
-
使用pytorch进行图像的顺序读取方法
产生此次实验的原因:当我使用pytorch进行神经网络的训练时,需要每次向CNN传入一组图像,并且这些图片的存放位置是在两个文件夹中: A文件夹:图片1a,图片2a,图片3a--图片1000a B文件夹:图片1b, 图片2b,图片3b--图片1000b 所以在每个循环里,我都希望能从A中取出图片Na,同时从B文件夹中取出对应的图片Nb. 测试一:通过pytorch官方文档中的dataloader搭配python中的迭代器iterator dataset = dset.ImageFolder( r
-
从Pytorch模型pth文件中读取参数成numpy矩阵的操作
目的: 把训练好的pth模型参数提取出来,然后用其他方式部署到边缘设备. Pytorch给了很方便的读取参数接口: nn.Module.parameters() 直接看demo: from torchvision.models.alexnet import alexnet model = alexnet(pretrained=True).eval().cuda() parameters = model.parameters() for p in parameters: numpy_para =
-
Pytorch 实现数据集自定义读取
以读取VOC2012语义分割数据集为例,具体见代码注释: VocDataset.py from PIL import Image import torch import torch.utils.data as data import numpy as np import os import torchvision import torchvision.transforms as transforms import time #VOC数据集分类对应颜色标签 VOC_COLORMAP = [[0,
-

PyTorch数据读取的实现示例
前言 PyTorch作为一款深度学习框架,已经帮助我们实现了很多很多的功能了,包括数据的读取和转换了,那么这一章节就介绍一下PyTorch内置的数据读取模块吧 模块介绍 pandas 用于方便操作含有字符串的表文件,如csv zipfile python内置的文件解压包 cv2 用于图片处理的模块,读入的图片模块为BGR,N H W C torchvision.transforms 用于图片的操作库,比如随机裁剪.缩放.模糊等等,可用于数据的增广,但也不仅限于内置的图片操作,也可以自行进行图片数
-
Pytorch数据读取与预处理该如何实现
在炼丹时,数据的读取与预处理是关键一步.不同的模型所需要的数据以及预处理方式各不相同,如果每个轮子都我们自己写的话,是很浪费时间和精力的.Pytorch帮我们实现了方便的数据读取与预处理方法,下面记录两个DEMO,便于加快以后的代码效率. 根据数据是否一次性读取完,将DEMO分为: 1.串行式读取.也就是一次性读取完所有需要的数据到内存,模型训练时不会再访问外存.通常用在内存足够的情况下使用,速度更快. 2.并行式读取.也就是边训练边读取数据.通常用在内存不够的情况下使用,会占用计算资源,如果分
-
Pytorch数据读取之Dataset和DataLoader知识总结
一.前言 确保安装 scikit-image numpy 二.Dataset 一个例子: # 导入需要的包 import torch import torch.utils.data.dataset as Dataset import numpy as np # 编造数据 Data = np.asarray([[1, 2], [3, 4],[5, 6], [7, 8]]) Label = np.asarray([[0], [1], [0], [2]]) # 数据[1,2],对应的标签是[0],数据
-
Android设备与外接U盘实现数据读取操作的示例
现在越来越多手机支持OTG功能,通过OTG可以实现与外接入的U盘等USB设备实现数据传输. USB OTG(On The Go)作为USB2.0的补充协议,于2001年由USB-IF提出.它提出的背景是移动消费类电子产品的迅猛增加,而之前USB协议的主从协议标准让这些电子产品在离开PC电脑时的数据传输变得艰难,OTG技术正是为了解决这一问题的标准. 通过OTG技术实现设备间端到端互联 OTG协议规定连接时默认情况作为Host的设备为A设备,A设备负责为总线供电:默认作为Device的设备为B设备
-
如何使用PyTorch实现自由的数据读取
目录 前言 PyTorch数据读入函数介绍 ImageFolder Dataset DataLoader 问题来源 自定义数据读入的举例实现 总结 前言 很多前人曾说过,深度学习好比炼丹,框架就是丹炉,网络结构及算法就是单方,而数据集则是原材料,为了能够炼好丹,首先需要一个使用称手的丹炉,同时也要有好的单方和原材料,最后就需要炼丹师们有着足够的经验和技巧掌握火候和时机,这样方能炼出绝世好丹. 对于刚刚进入炼丹行业的炼丹师,网上都有一些前人总结的炼丹技巧,同时也有很多炼丹师的心路历程以及丹师对整个
-
Python 读取串口数据,动态绘图的示例
最近工作需要把单片机读取的传感器电压数据实时在PC上通过曲线显示出来,刚好在看python, 就试着用了python 与uart端口通讯,并且通过matplotlib.pyplot 模块实时绘制图形出来. 1. 废话少说,上图 因为没有UI,运行时需要在提示符下输入串口相关参数,com端口,波特率... 代码如下: #-*- coding: utf-8 -*- # 串口测试程序 import serial import matplotlib.pyplot as plt import numpy
-
Pytorch 如何加速Dataloader提升数据读取速度
在利用DL解决图像问题时,影响训练效率最大的有时候是GPU,有时候也可能是CPU和你的磁盘. 很多设计不当的任务,在训练神经网络的时候,大部分时间都是在从磁盘中读取数据,而不是做 Backpropagation . 这种症状的体现是使用 Nividia-smi 查看 GPU 使用率时,Memory-Usage 占用率很高,但是 GPU-Util 时常为 0% ,如下图所示: 如何解决这种问题呢? 在 Nvidia 提出的分布式框架 Apex 里面,我们在源码里面找到了一个简单的解决方案: htt
-
微信小程序 本地数据读取实例
微信小程序 本地数据读取实例 一般情况下,小程序的utils这个文件夹下,我们可以把本地的数据写进去,封装成.js文件,提供对外暴露的接口,然后读取本地数据.如果涉及到一些针对这些数据的处理方法,也可以把方法写好,封装到.js文件里面,然后需要时调用. module.exports = { mtData: mtData, searchmtdata: searchmtdata, usedraw: usedraw } var mt_data = mtData() function searchmtd
-
java利用注解实现简单的excel数据读取
实现工具类 利用注解实现简单的excel数据读取,利用注解对类的属性和excel中的表头映射,使用Apache的poi就不用在业务代码中涉及row,rows这些属性了. 定义注解: @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface Excel { String name(); } 由于本例中只涉及根据Excel表头部分对Excel进行解析,只定义了一个name作为和Excel表头的隐射
-
用十张图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,文章的最后还会给出实战代码以供参考. TensorFlow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示: 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg--我们只需要把