python 如何用map()函数创建多线程任务
对于多线程的使用,我们经常是用thread来创建,比较繁琐. 在Python中,可以使用map函数简化代码。map可以实现多任务的并发
简单说明map()实现多线程原理:
task = [‘任务1', ‘任务2', ‘任务3', …]
map 函数一手包办了序列操作、参数传递和结果保存等一系列的操作,map函数负责将线程分给不同的CPU。

在 Python 中有个两个库包含了 map 函数: multiprocessing 和它鲜为人知的子库 multiprocessing.dummy.dummy 是 multiprocessing 模块的完整克隆,唯一的不同在于 multiprocessing 作用于进程,而 dummy 模块作用于线程。
代码如下:
from multiprocessing.dummy import Pool as ThreadPool
import os
import requests
import time
import numpy as np
# 文件夹位置
filepath = r'C:\Users\Administrator\Desktop\ceshi'
pool = ThreadPool(10)#开启线程数,即一次性抛出的请求数
time_list = []#用来计算时间
xml_list = []#数据集
pathDir = os.listdir(filepath)
for i, allDir in enumerate(pathDir):
filename = os.path.join('%s%s' % (filepath + '\\', allDir))
kk = open(filename, 'r', encoding='utf-8').read()
data = kk.encode('utf-8')
for k in range(10):
xml_list.append(data)
def res(data):
# 访问目标服务器地址
url_host = 'https://mp.csdn.net/mdeditor#'
start = time.clock()
s = requests.post(url_host, data=data)
end = time.clock()
if s.status_code == 200:
print(end-start)
time_list.append(end-start)
else:
print('请求失败')
# 传入的参数,1为函数, 2为参数
result = pool.map(res, xml_list)
all_arr = np.array(time_list)
aver = np.mean(all_arr)
variance = np.var(all_arr)
mid = np.median(all_arr)
min_num = np.min(all_arr)
max_num = np.max(all_arr)
print('平均值 : '+ str(aver))
print('方差 : ' + str(variance))
print('中值 : ' + str(mid))
print('最小值 : ' + str(min_num))
print('最大值 : ' + str(max_num))
个人做的小测试,如果有错误的地方希望留言提出意见及建议。
补充:python多进程(multiprocessing)(map)
map的基本使用:
map函数一手包办了序列操作,参数传递和结果保存等一系列的操作。
from multiprocessing.dummy import Pool
poop = Pool(4) # 4代表电脑是多少核的
results = pool.map(爬取函数,网址列表)
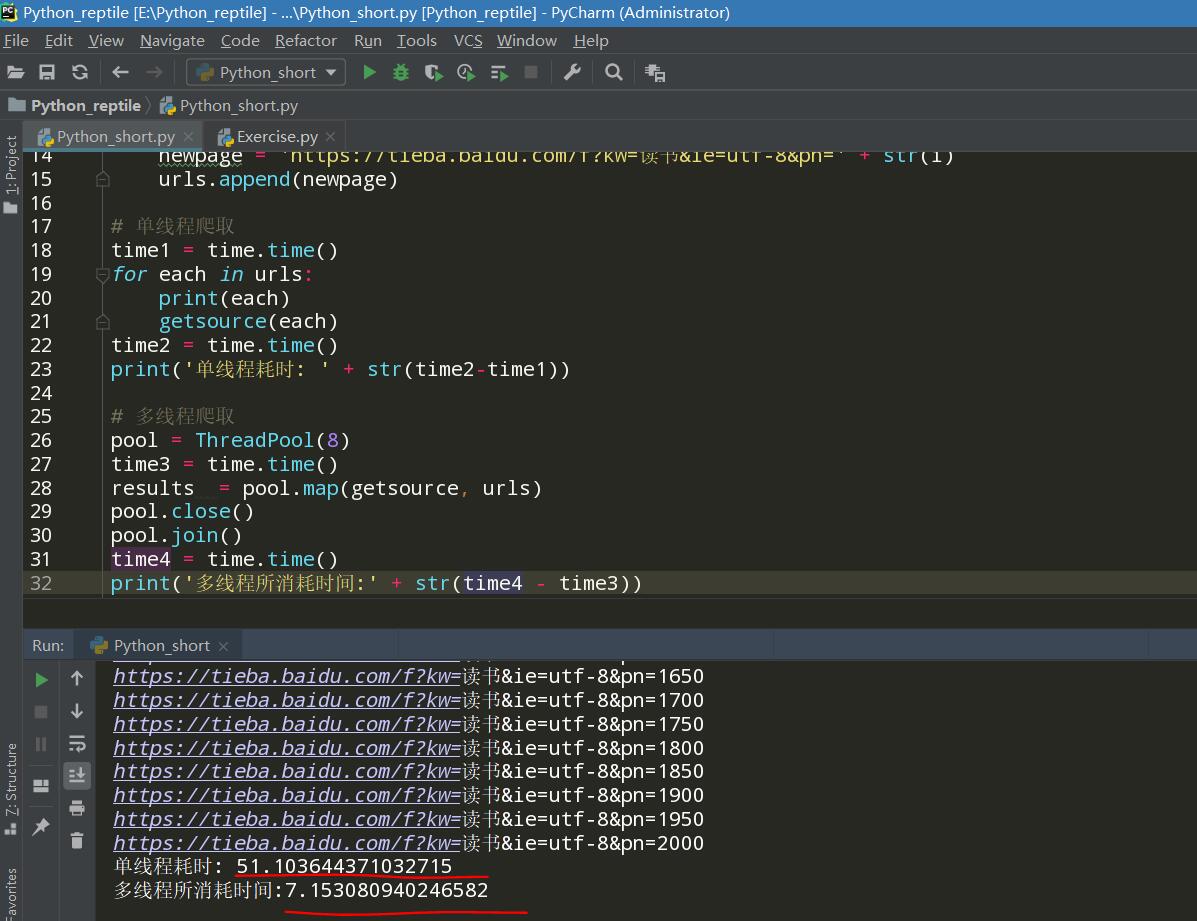
from multiprocessing.dummy import Pool as ThreadPool
import requests
import time
kv = {'user-agent':'Mozilla/5.0'}
def getsource(url):
html = requests.get(url,headers=kv)
urls = []
for i in range(0,41):
i = i*50
newpage = 'https://tieba.baidu.com/f?kw=读书&ie=utf-8&pn=' + str(i)
urls.append(newpage)
# 单线程爬取
time1 = time.time()
for each in urls:
print(each)
getsource(each)
time2 = time.time()
print('单线程耗时: ' + str(time2-time1))
# 多线程爬取
pool = ThreadPool(8)
time3 = time.time()
results = pool.map(getsource, urls)
pool.close()
pool.join()
time4 = time.time()
print('多线程所消耗时间:' + str(time4 - time3))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python 实现多进程日志轮转ConcurrentLogHandler
记录日志是我们程序中必不可少的一个功能,但是日志文件如果没有合理的管理,时间长了几百兆的日志文件就很难分析了(都不想打开看),但是又不可能经常手动去管理它 日志轮转:根据时间或者文件大小控制日志的文件个数,不用我们手动管理 python中logging模块内置的有几个支持日志轮转的handler 常用的有TimedRotatingFileHandler根据时间轮转 RotatingFileHandler根据文件大小轮转 但是内置的这些handler是多线程安全的,而不支持多进程(可以修改源码加锁
-
Python之多进程与多线程的使用
进程与线程 想象在学校的一个机房,有固定数量的电脑,老师安排了一个爬虫任务让大家一起完成,每个学生使用一台电脑爬取部分数据,将数据放到一个公共数据库.共同资源就像公共数据库,进程就像每一个学生,每多一个学生,就多一个进程来完成这个任务,机房里的电脑数量就像CPU,所以进程数量是CPU决定的,线程就像学生用一台电脑开多个爬虫,爬虫数量由每台电脑的运行内存决定. 一个CPU可以有多个进程,一个进程有一个或多个线程. 多进程 1.导包 from multiprocessing import Proce
-

python 多线程爬取壁纸网站的示例
基本开发环境 · Python 3.6 · Pycharm 需要导入的库 目标网页分析 网站是静态网站,没有加密,可以直接爬取 整体思路: 1.先在列表页面获取每张壁纸的详情页地址 2.在壁纸详情页面获取壁纸真实高清url地址 3.保存地址 代码实现 模拟浏览器请请求网页,获取网页数据 这里只选择爬取前10页的数据 代码如下 import threading import parsel import requests def get_html(html_url): ''' 获取网页源代码 :pa
-
python基于concurrent模块实现多线程
引言 之前也写过多线程的博客,用的是 threading ,今天来讲下 python 的另外一个自带库 concurrent .concurrent 是在 Python3.2 中引入的,只用几行代码就可以编写出线程池/进程池,并且计算型任务效率和 mutiprocessing.pool 提供的 poll 和 ThreadPoll 相比不分伯仲,而且在 IO 型任务由于引入了 Future 的概念效率要高数倍.而 threading 的话还要自己维护相关的队列防止死锁,代码的可读性也会下降,相反
-
python程序中的线程操作 concurrent模块使用详解
一.concurrent模块的介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor:进程池,提供异步调用 ProcessPoolExecutor 和 ThreadPoolExecutor:两者都实现相同的接口,该接口由抽象Executor类定义. 二.基本方法 submit(fn, *args, **kwargs) :异步提交任务 map(func, *iterables,
-
python 多进程和多线程使用详解
进程和线程 进程是系统进行资源分配的最小单位,线程是系统进行调度执行的最小单位: 一个应用程序至少包含一个进程,一个进程至少包含一个线程: 每个进程在执行过程中拥有独立的内存空间,而一个进程中的线程之间是共享该进程的内存空间的: 计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 假定工厂的电力有限,一次只能供给一个车间使用.也就是说,一个车间开工的时候,其他车间都必须停工.背后的含义就是,单个CPU一次只能运行一个任务.编者注: 多核的CPU就像有了多个发电厂,使多工厂
-
Python concurrent.futures模块使用实例
这篇文章主要介绍了Python concurrent.futures模块使用实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 concurrent.futures的作用: 管理并发任务池.concurrent.futures模块提供了使用工作线程或进程池运行任务的接口.线程和进程池API都是一样,所以应用只做最小的修改就可以在线程和进程之间地切换 1.基于线程池使用map() futures_thread_pool_map.py #!/usr
-
Python 多线程之threading 模块的使用
简介 Python 通过 _thread 和 threading 模块提供了对多线程的支持,threading 模块兼具了 _thread 模块的现有功能,又扩展了一些新的功能,具有十分丰富的线程操作功能 创建线程 使用 threading 模块创建线程通常有两种方式: 1)使用 threading 模块中 Thread 类的构造器创建线程,即直接对类 threading.Thread 进行实例化,并调用实例化对象的 start 方法创建线程: 2)继承 threading 模块中的 Threa
-
Python多进程与多线程的使用场景详解
前言 Python多进程适用的场景:计算密集型(CPU密集型)任务 Python多线程适用的场景:IO密集型任务 计算密集型任务一般指需要做大量的逻辑运算,比如上亿次的加减乘除,使用多核CPU可以并发提高计算性能. IO密集型任务一般指输入输出型,比如文件的读取,或者网络的请求,这类场景一般会遇到IO阻塞,使用多核CPU来执行并不会有太高的性能提升. 下面使用一台64核的虚拟机来执行任务,通过示例代码来区别它们, 示例1:执行计算密集型任务,进行1亿次运算 使用多进程 from multipro
-
Python并发concurrent.futures和asyncio实例
说明 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码. 从Python3.2开始,标准库为我们提供了concurrent.futures模块,concurrent.futures 模块的主要特色是 ThreadPoolExecutor 和 ProcessPoolExecutor 类,这两个类实现的接口能分别在不同的线程或进程中执行可调 用的对象.这两个类在内部维护着一个工作线程或进程池,以及要执行的任务队列. Python 3.4
-
python多线程超详细详解
python中的多线程是一个非常重要的知识点,今天为大家对多线程进行详细的说明,代码中的注释有多线程的知识点还有测试用的实例. import threading from threading import Lock,Thread import time,os ''' python多线程详解 什么是线程? 线程也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位. 线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程