python 共现矩阵的实现代码
目录
- python共现矩阵实现
- 项目背景
- 什么是共现矩阵
- 共现矩阵的构建思路
- 共现矩阵的代码实现
- 共现矩阵(共词矩阵)计算
- 共现矩阵(共词矩阵)
- 补充一点
python共现矩阵实现
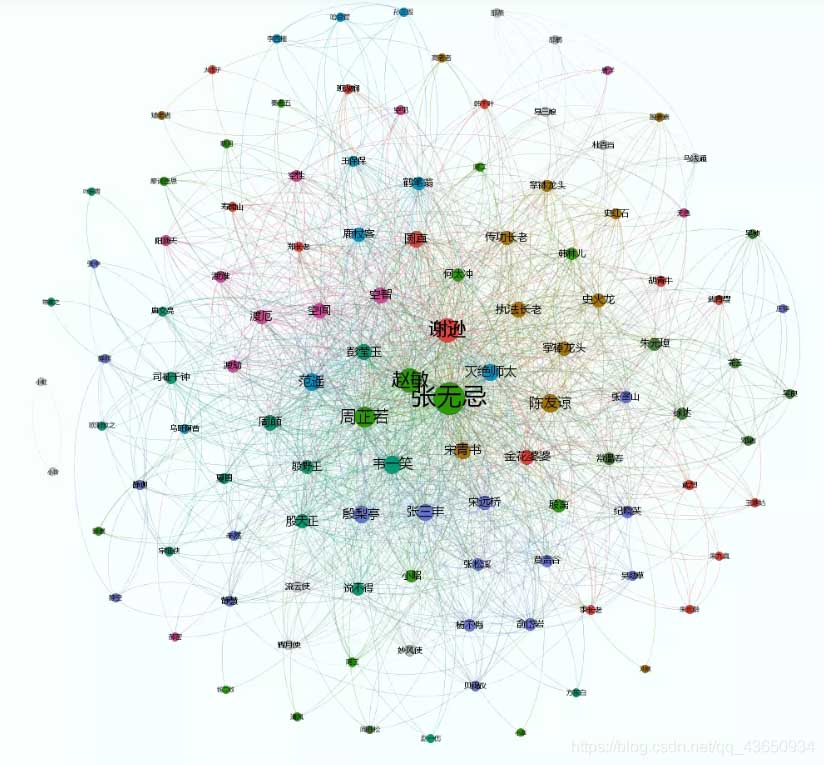
最近在学习python词库的可视化,其中有一个依据共现矩阵制作的可视化,感觉十分炫酷,便以此复刻。
项目背景
本人利用爬虫获取各大博客网站的文章,在进行jieba分词,得到每篇文章的关键词,对这些关键词进行共现矩阵的可视化。
什么是共现矩阵
比如我们有两句话:
ls = ['我永远喜欢三上悠亚', '三上悠亚又出新作了']
在jieba分词下我们可以得到如下效果:
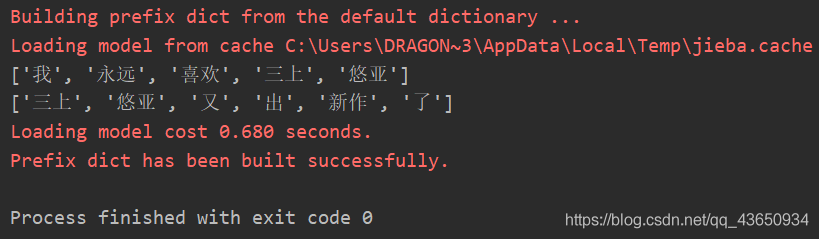
我们就可以构建一个以关键词的共现矩阵:
['', '我', '永远', '喜欢', '三上', '悠亚', '又', '出', '新作', '了'] ['我', 0, 1, 1, 1, 1, 0, 0, 0, 0] ['永远', 1, 0, 1, 1, 1, 0, 0, 0, 0] ['喜欢' 1, 1, 0, 1, 1, 0, 0, 0, 0] ['三上', 1, 1, 1, 0, 1, 1, 1, 1, 1] ['悠亚', 1, 1, 1, 1, 0, 1, 1, 1, 1] ['又', 0, 0, 0, 1, 1, 0, 1, 1, 1] ['出', 0, 0, 0, 1, 1, 1, 0, 1, 1] ['新作', 0, 0, 0, 1, 1, 1, 1, 0, 1] ['了', 0, 0, 0, 1, 1, 1, 1, 1, 0]]
解释一下,“我永远喜欢三上悠亚”,这一句话中,“我”和“永远”共同出现了一次,在共现矩阵对应的[ i ] [ j ]和[ j ][ i ]上+1,并依次类推。
基于这个原因,我们可以发现,共现矩阵的特点是:
- 共现矩阵的[0][0]为空。
- 共现矩阵的第一行第一列是关键词。
- 对角线全为0。
- 共现矩阵其实是一个对称矩阵。
当然,在实际的操作中,这些关键词是需要经过清洗的,这样的可视化才干净。
共现矩阵的构建思路
- 每篇文章关键词的二维数组data_array。
- 所有关键词的集合set_word。
- 建立关键词长度+1的矩阵matrix。
- 赋值矩阵的第一行与第一列为关键词。
- 设置矩阵对角线为0。
- 遍历formated_data,让取出的行关键词和取出的列关键词进行组合,共现则+1。
共现矩阵的代码实现
# coding:utf-8
import numpy as np
import pandas as pd
import jieba.analyse
import os
# 获取关键词
def Get_file_keywords(dir):
data_array = [] # 每篇文章关键词的二维数组
set_word = [] # 所有关键词的集合
try:
fo = open('dic_test.txt', 'w+', encoding='UTF-8')
# keywords = fo.read()
for home, dirs, files in os.walk(dir): # 遍历文件夹下的每篇文章
for filename in files:
fullname = os.path.join(home, filename)
f = open(fullname, 'r', encoding='UTF-8')
sentence = f.read()
words = " ".join(jieba.analyse.extract_tags(sentence=sentence, topK=30, withWeight=False,
allowPOS=('n'))) # TF-IDF分词
words = words.split(' ')
data_array.append(words)
for word in words:
if word not in set_word:
set_word.append(word)
set_word = list(set(set_word)) # 所有关键词的集合
return data_array, set_word
except Exception as reason:
print('出现错误:', reason)
return data_array, set_word
# 初始化矩阵
def build_matirx(set_word):
edge = len(set_word) + 1 # 建立矩阵,矩阵的高度和宽度为关键词集合的长度+1
'''matrix = np.zeros((edge, edge), dtype=str)''' # 另一种初始化方法
matrix = [['' for j in range(edge)] for i in range(edge)] # 初始化矩阵
matrix[0][1:] = np.array(set_word)
matrix = list(map(list, zip(*matrix)))
matrix[0][1:] = np.array(set_word) # 赋值矩阵的第一行与第一列
return matrix
# 计算各个关键词的共现次数
def count_matrix(matrix, formated_data):
for row in range(1, len(matrix)):
# 遍历矩阵第一行,跳过下标为0的元素
for col in range(1, len(matrix)):
# 遍历矩阵第一列,跳过下标为0的元素
# 实际上就是为了跳过matrix中下标为[0][0]的元素,因为[0][0]为空,不为关键词
if matrix[0][row] == matrix[col][0]:
# 如果取出的行关键词和取出的列关键词相同,则其对应的共现次数为0,即矩阵对角线为0
matrix[col][row] = str(0)
else:
counter = 0 # 初始化计数器
for ech in formated_data:
# 遍历格式化后的原始数据,让取出的行关键词和取出的列关键词进行组合,
# 再放到每条原始数据中查询
if matrix[0][row] in ech and matrix[col][0] in ech:
counter += 1
else:
continue
matrix[col][row] = str(counter)
return matrix
def main():
formated_data, set_word = Get_file_keywords(r'D:\untitled\test')
print(set_word)
print(formated_data)
matrix = build_matirx(set_word)
matrix = count_matrix(matrix, formated_data)
data1 = pd.DataFrame(matrix)
data1.to_csv('data.csv', index=0, columns=None, encoding='utf_8_sig')
main()
共现矩阵(共词矩阵)计算
共现矩阵(共词矩阵)
统计文本中两两词组之间共同出现的次数,以此来描述词组间的亲密度
code(我这里求的对角线元素为该字段在文本中出现的总次数):
import pandas as pd
def gx_matrix(vol_li):
# 整合一下,输入是df列,输出直接是矩阵
names = locals()
all_col0 = [] # 用来后续求所有字段的集合
for row in vol_li:
all_col0 += row
for each in row: # 对每行的元素进行处理,存在该字段字典的话,再进行后续判断,否则创造该字段字典
try:
for each1 in row: # 对已存在字典,循环该行每个元素,存在则在已有次数上加一,第一次出现创建键值对“字段:1”
try:
names['dic_' + each][each1] = names['dic_' + each][each1] + 1 # 尝试,一起出现过的话,直接加1
except:
names['dic_' + each][each1] = 1 # 没有的话,第一次加1
except:
names['dic_' + each] = dict.fromkeys(row, 1) # 字段首次出现,创造字典
# 根据生成的计数字典生成矩阵
all_col = list(set(all_col0)) # 所有的字段(所有动物的集合)
all_col.sort(reverse=False) # 给定词汇列表排序排序,为了和生成空矩阵的横向列名一致
df_final0 = pd.DataFrame(columns=all_col) # 生成空矩阵
for each in all_col: # 空矩阵中每列,存在给字段字典,转为一列存入矩阵,否则先创造全为零的字典,再填充进矩阵
try:
temp = pd.DataFrame(names['dic_' + each], index=[each])
except:
names['dic_' + each] = dict.fromkeys(all_col, 0)
temp = pd.DataFrame(names['dic_' + each], index=[each])
df_final0 = pd.concat([df_final0, temp]) # 拼接
df_final = df_final0.fillna(0)
return df_final
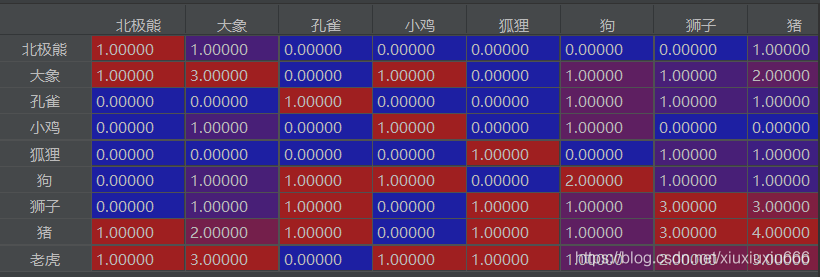
if __name__ == '__main__':
temp1 = ['狗', '狮子', '孔雀', '猪']
temp2 = ['大象', '狮子', '老虎', '猪']
temp3 = ['大象', '北极熊', '老虎', '猪']
temp4 = ['大象', '狗', '老虎', '小鸡']
temp5 = ['狐狸', '狮子', '老虎', '猪']
temp_all = [temp2, temp1, temp3, temp4, temp5]
vol_li = pd.Series(temp_all)
df_matrix = gx_matrix(vol_li)
print(df_matrix)
输入是整成这个样子的series

求出每个字段与各字段的出现次数的字典

最后转为df
补充一点
这里如果用大象所在列,除以大象出现的次数,比值高的,表明两者一起出现的次数多,如果这列比值中,有两个元素a和b的比值均大于0.8(也不一定是0.8啦),就是均比较高,则说明a和b和大象三个一起出现的次数多!!!
即可以求出文本中经常一起出现的词组搭配,比如这里的第二列,大象一共出现3次,与老虎出现3次,与猪出现2次,则可以推导出大象,老虎,猪一起出现的概率较高。
也可以把出现总次数拎出来,放在最后一列,则代码为:
# 计算每个字段的出现次数,并列为最后一行
df_final['all_times'] = ''
for each in df_final0.columns:
df_final['all_times'].loc[each] = df_final0.loc[each, each]
放在上述代码df_final = df_final0.fillna(0)的后面即可
结果为

我第一次放代码上来的时候中间有一块缩进错了,感谢提出问题的同学的提醒,现在是更正过的代码!!!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python 的矩阵传播机制Broadcasting和矩阵运算
目录 一.Python的矩阵传播机制(Broadcasting) 二.下面展示什么是python的传播机制 三.利用numpy的内置函数对矩阵进行操作 四.定义自己的函数来处理矩阵 五.总结 一.Python的矩阵传播机制(Broadcasting) 我们知道在深度学习中经常要操作各种矩阵(matrix) .回想一下,我们在操作数组(list)的时候,经常习惯于用**for循环(for-loop)**来对数组的每一个元素进行操作.例如: my_list = [1,2,3,4] new_list
-
使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
python机器学习混淆矩阵及confusion matrix函数使用
目录 1.混淆矩阵 2.confusion_matrix函数的使用 实现例子: 运行结果: 关于混淆矩阵的概念,可参考此篇博文混淆矩阵 1.混淆矩阵 混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总.这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class) 下图是混淆矩阵的一个例子 其中灰色部分是真实分类和预测分类结果相一致的,绿色部分是真实分类和预测分类不一致的,即
-
详解Python NumPy中矩阵和通用函数的使用
目录 一.创建矩阵 二.从已有矩阵创建新矩阵 三.通用函数 四.算术运算 在NumPy中,矩阵是 ndarray 的子类,与数学概念中的矩阵一样,NumPy中的矩阵也是二维的,可以使用 mat . matrix 以及 bmat 函数来创建矩阵. 一.创建矩阵 mat 函数创建矩阵时,若输入已为 matrix 或 ndarray 对象,则不会为它们创建副本. 因此,调用 mat() 函数和调用 matrix(data, copy=False) 等价. 1) 在创建矩阵的专用字符串中,矩阵的行与行之
-
mat矩阵和npy矩阵实现互相转换(python和matlab)
目录 mat矩阵和npy矩阵互相转换 numpy.narray矩阵保存为mat文件 读取mat文件 npy文件与mat文件的保存与读取 1. npy文件 2. mat文件 mat矩阵和npy矩阵互相转换 numpy.narray矩阵保存为mat文件 import numpy as np import scipy.io as io mat_path = 'your_mat_save_path' mat = np.zeros([4, 20]) io.savemat(mat_path, {'name'
-
Python实现两种多分类混淆矩阵
目录 1.什么是混淆矩阵 2.分类模型评价指标 3.两种多分类混淆矩阵 3.1直接打印出每一个类别的分类准确率. 3.2打印具体的分类结果的数值 4.总结 1.什么是混淆矩阵 深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法.它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分.它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class). 首先要明确几个概念: T或者F:该样本 是否被正确分类
-
python 共现矩阵的实现代码
目录 python共现矩阵实现 项目背景 什么是共现矩阵 共现矩阵的构建思路 共现矩阵的代码实现 共现矩阵(共词矩阵)计算 共现矩阵(共词矩阵) 补充一点 python共现矩阵实现 最近在学习python词库的可视化,其中有一个依据共现矩阵制作的可视化,感觉十分炫酷,便以此复刻. 项目背景 本人利用爬虫获取各大博客网站的文章,在进行jieba分词,得到每篇文章的关键词,对这些关键词进行共现矩阵的可视化. 什么是共现矩阵 比如我们有两句话: ls = ['我永远喜欢三上悠亚', '三上悠亚又出新作
-
python 顺时针打印矩阵的超简洁代码
如下所示: # -*- coding:utf-8 -*- class Solution: # matrix类型为二维列表,需要返回列表 def printMatrix(self, matrix): # write code here res=[] n=len(matrix) m=len(matrix[0]) if m==1 and n==1: res=[matrix[0][0]] return res else: for o in range((min(m,n)+1)//2): [res.app
-
python中numpy矩阵的零填充的示例代码
目录 需求: 一.再new一个更大的所需要的矩阵大小 二.pad函数 其他想法 需求: 对于图像处理中的一些过程,我需要对读取的numpy矩阵进行size的扩充,比如原本是(4,6)的矩阵,现在需要上下左右各扩充3行,且为了不影响数值计算,都用0填充. 比如下图,我有一个4x5大小的全1矩阵,但是现在我要在四周都加上3行的0来扩充大小,最后扩充完还要对原区域进行操作. 方法: 想到了几种方法,记录一下. 一.再new一个更大的所需要的矩阵大小 a = np.ones((4,5)) #假设原矩阵是
-
Python实现的矩阵类实例
本文实例讲述了Python实现的矩阵类.分享给大家供大家参考,具体如下: 科学计算离不开矩阵的运算.当然,python已经有非常好的现成的库:numpy(numpy的简单安装与使用可参考http://www.jb51.net/article/66236.htm). 我写这个矩阵类,并不是打算重新造一个轮子,只是作为一个练习,记录在此. 注:这个类的函数还没全部实现,慢慢在完善吧. 全部代码: import copy class Matrix: '''矩阵类''' def __init__(sel
-
Python类的继承和多态代码详解
Python类的继承 在OOP(ObjectOrientedProgramming)程序设计中,当我们定义一个class的时候,可以从某个现有的class继承,新的class称为子类(Subclass),而被继承的class称为基类.父类或超类(Baseclass.Superclass). 我们先来定义一个classPerson,表示人,定义属性变量name及sex(姓名和性别): 定义一个方法print_title():当sex是male时,printman:当sex是female时,prin
-
Python实现螺旋矩阵的填充算法示例
本文实例讲述了Python实现螺旋矩阵的填充算法.分享给大家供大家参考,具体如下: afanty的分析: 关于矩阵(二维数组)填充问题自己动手推推,分析下两个下表的移动规律就很容易咯. 对于螺旋矩阵,不管它是什么鬼,反正就是依次向右.向下.向右.向上移动. 向右移动:横坐标不变,纵坐标加1 向下移动:纵坐标不变,横坐标加1 向右移动:横坐标不变,纵坐标减1 向上移动:纵坐标不变,横坐标减1 代码实现: #coding=utf-8 import numpy ''''' Author: afanty
-
python+pillow绘制矩阵盖尔圆简单实例
本文主要研究的是使用Python+pillow绘制矩阵盖尔圆的一个实例,具体如下. 盖尔圆是矩阵特征值估计时常用的方法之一,其定义为: 与盖尔圆有关的两个定理为: 定理1:矩阵A的所有特征值均落在它的所有盖尔圆的并集之中. 定理2:将矩阵A的全体盖尔圆的并集按连通部分分成若干个子集,(一个子集由完全连通的盖尔圆组成,不同子集没有相连通的部分),对每个子集,若它恰好由K个盖尔圆组成,则该子集中恰好包含A的K个特征值. 与盖尔圆定理有关的几个推论为: 推论1:孤立盖尔圆中恰好包含一个特征值. 推论2
-
python 列表,数组,矩阵两两转换tolist()的实例
通过代码熟悉过程: # -*- coding: utf-8 -*- from numpy import * a1 =[[1,2,3],[4,5,6]] #列表 print('a1 :',a1) #('a1 :', [[1, 2, 3], [4, 5, 6]]) a2 = array(a1) #列表 -----> 数组 print('a2 :',a2) #('a2 :', array([[1, 2, 3],[4, 5, 6]])) a3 = mat(a1) #列表 ----> 矩阵 print(
-
Python实现的矩阵转置与矩阵相乘运算示例
本文实例讲述了Python实现的矩阵转置与矩阵相乘运算.分享给大家供大家参考,具体如下: 矩阵转置 方法一 :使用常规的思路 def transpose(M): # 初始化转置后的矩阵 result = [] # 获取转置前的行和列 row, col = shape(M) # 先对列进行循环 for i in range(col): # 外层循环的容器 item = [] # 在列循环的内部进行行的循环 for index in range(row): item.append(M[index][
-
python使用__slots__让你的代码更加节省内存
前言 在默认情况下,Python的新类和旧类的实例都有一个字典来存储属性值.这对于那些没有实例属性的对象来说太浪费空间了,当需要创建大量实例的时候,这个问题变得尤为突出. 因此这种默认的做法可以通过在新式类中定义了一个__slots__属性从而得到了解决.__slots__声明中包含若干实例变量,并为每个实例预留恰好足够的空间来保存每个变量,因此没有为每个实例都创建一个字典,从而节省空间. 本文主要介绍了关于python使用__slots__让你的代码更加节省内存的相关内容,分享出来供大家参考学