Redis数据结构SortedSet的底层原理解析
目录
- 概述
- 一些常用命令
- 实现
- 跳跃表
- 跳表的插入
- 压缩列表
概述
一些常用命令
- 存储:zadd key score value
- 获取:zrange key start end
- 获取:同时获取分数:zrange key start end with score
- 删除:zrem key value
存储的时候我们可以发现,是有一个score(分数)的,这个就是用来排序的字段。
实现
先说结论,SortedSet底层,根据配置会在不同的时候选用两种不同的数据结构zset,或ziplist进行存储:
首先,我们来看几个参数:
zset-max-ziplist-entries 128 zset-max-ziplist-value 64
if (
field-value对的数量 > ziplist.entries.size ||
任意一个filed或value长度 > zset-max-ziplist-value
) {
// 使用 zset 进行存储
} else {
// 使用 ziplist 进行存储
zset的结构如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset
可以发现,是由字典+跳跃表实现的。
zset结构体里有两个元素,一个是 dict,用来维护 数据 到 分数 的关系,一个是 zskiplist,用来维护 分数所在链表 的关系dict里通过维护 哈希表 存储了 张三=>100,李四=>90 的分数关系。
而跳表则是排序的关键
跳跃表
先上图:

我们知道,链表的检索效率是非常低的,如果要拿到100条数据中间的数据,则需要遍历50个数据才行,为了解决这个问题,跳表应运而生
如上图,就是常规的跳表,会在原有的数据上加上若干层,指向当前层的下一个节点。
跳表的插入
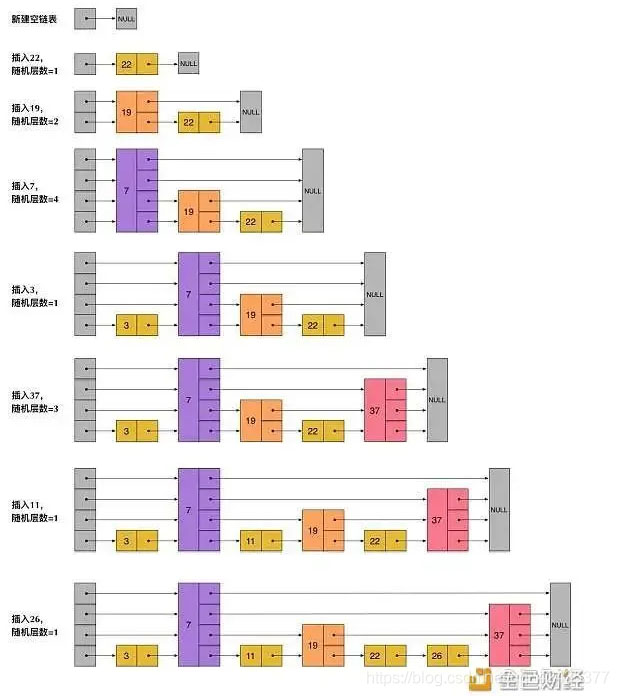
如上图所示:其实每个节点的层数是随机的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist跳表的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。
如下图,假如我们需要查询23,查询的路径如下。

事实上,在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
这也是SortedSet实现排序的原理。
压缩列表
压缩列表 ziplist 是为 Redis 节约内存而开发的。
压缩列表是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点 (entry),每个节点可以保存 一个字节数组 或者 一个整数值 。

1、zl bytes:用于记录整个压缩列表占用的内存字节数
2、zl tail:记录要列表尾节点距离压缩列表的起始地址有多少字节
3、zl len:记录了压缩列表包含的节点数量。
4、entryX:要说列表包含的各个节点
5、zl end:用于标记压缩列表的末端
压缩列表是一种为了节约内存而开发的顺序型数据结构
压缩列表被用作列表键和哈希键的底层实现之一
压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值
添加新节点到压缩列表,可能会引发连锁更新操作。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Redis源码分析之set 和 sorted set 使用
目录 set 和 sorted set 前言 set 常见命令 set 的使用场景 看下源码实现 sorted set 常见的命令 使用场景 分析下源码实现 总结 参考 set 和 sorted set 前言 前面在几个文章聊到了 list,string,hash 等结构的实现,这次来聊一下 set 和 sorted set 的细节. set Redis 的 Set 是 String 类型的无序集合,集合成员是唯一的. 底层实现主要用到了两种数据结构 hashtable 和 inset(整数集合
-
通俗易懂的Redis数据结构基础教程(入门)
Redis有5个基本数据结构,string.list.hash.set和zset.它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这5个数据结构都吃透了,你就掌握了Redis应用知识的一半了. string 首先我们从string谈起.string表示的是一个可变的字节数组,我们初始化字符串的内容.可以拿到字符串的长度,可以获取string的子串,可以覆盖string的子串内容,可以追加子串. Redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayL
-
分布式架构Redis中有哪些数据结构及底层实现原理
目录 引言 1.面试官:我看你提到,项目中使用了Reids作为缓存,为什么是Reids而不是其他,Redis有什么优势吗? 2.面试官:刚刚你提到Redis是单线程,为什么单线程模型的Redis性能不减. 3.面试官:那你刚刚说的Redis数据结构都有哪几种,如何选择使用哪种? 深入分析 1.简单动态字符串结构,Redis字符串的实现方式 2.链表数据结构,List底层结构 3.跳跃表,sortedset底层结构 关于缓存的一些算法 常用缓存数据淘汰策略 缓存数据更新策略 总结 引言 面完了负载
-
详解Redis数据结构之跳跃表
1.简介 我们先不谈Redis,来看一下跳表. 1.1.业务场景 场景来自小灰的算法之旅,我们需要做一个拍卖行系统,用来查阅和出售游戏中的道具,类似于魔兽世界中的拍卖行那样,还有以下需求: 拍卖行拍卖的商品需要支持四种排序方式,分别是:按价格.按等级.按剩余时间.按出售者ID排序,排序查询要尽可能地快.还要支持输入道具名称的精确查询和不输入名称的全量查询. 这样的业务场景所需要的数据结构该如何设计呢?拍卖行商品列表是线性的,最容易表达线性结构的是数组和链表.假如用有序数组,虽然查找的时候可以使用
-
Redis数据结构SortedSet的底层原理解析
目录 概述 一些常用命令 实现 跳跃表 跳表的插入 压缩列表 概述 一些常用命令 存储:zadd key score value 获取:zrange key start end 获取:同时获取分数:zrange key start end with score 删除:zrem key value 存储的时候我们可以发现,是有一个score(分数)的,这个就是用来排序的字段. 实现 先说结论,SortedSet底层,根据配置会在不同的时候选用两种不同的数据结构zset,或ziplist进行存储:
-
php redis setnx分布式锁简单原理解析
我就废话不多说了,大家还是直接看代码吧~ <?php //高并发分布式锁 header("Content-type:text/html;charset=utf-8"); $redis = new Redis(); $redis->connect('127.0.0.1', 6379); echo "Connection to server sucessfully"; //echo $redis->get("name");exit;
-
Activiti工作流学习笔记之自动生成28张数据库表的底层原理解析
网上关于工作流引擎Activiti生成表的机制大多仅限于四种策略模式,但其底层是如何实现的,相关文章还是比较少,因此,觉得撸一撸其生成表机制的底层原理. 我接触工作流引擎Activiti已有两年之久,但一直都只限于熟悉其各类API的使用,对底层的实现,则存在较大的盲区. Activiti这个开源框架在设计上,其实存在不少值得学习和思考的地方,例如,框架用到以命令模式.责任链模式.模板模式等优秀的设计模式来进行框架的设计. 故而,是值得好好研究下Activiti这个框架的底层实现. 我在工作当中现
-
Python matplotlib底层原理解析
目录 1. matplotlib 框架组成 2. 脚本层(scripting) 3. 美工层(artist) 4. 后端层(backend) 复习回顾: 前期,我们已经学习了matplotlib模块相关的基础知识,对 matplotlib 模块折线图.饼图.柱状图进行操作. 我们都知道matplotlib 是偏向底层用于可视化数据处理的库,我们在绘制图表的时候主要步骤主要有四大步骤: 导入 matplotlib.pplot库 使用pandas/numpy模块对数据进行整分析理 调用pyplot中
-
Golang底层原理解析String使用实例
目录 引言 String底层 stringStruct结构 引言 本人因为种种原因(说来听听),放弃大学学的java,走上了golang这条路,本着干一行爱一行的情怀,做开发嘛,不能只会使用这门语言,所以打算开一个底层原理系列,深挖一下,狠狠的掌握一下这门语言 废话不多说,上货 String底层 既然研究底层,那就得全方面覆盖,必须先搞一下基础的东西,那必须直接基本数据类型走起啊, 字符串String的底层我看就很基础 string大家应该都不陌生,go中的string是所有8位字节字符串的集合
-
SpringBoot整合log4j日志与HashMap的底层原理解析
一,SpringBoot与日志 1.springboot整合log4j日志记录 1.在resources目录下面创建日志文件,并引入: 代码如下(示例): #log4j.rootLogger=CONSOLE,info,error,DEBUG log4j.rootLogger=info,error,CONSOLE,DEBUG log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.layout=o
-
Docker基本概念和底层原理解析
目录 1.Docker的底层原理 2.Docker中常用的基本概念 3.run命令的运行流程 4.为什么Docker比VM快 Docker架构图: 我们依照Docker架构图进行Docker基础概念的说明. 1.Docker的底层原理 Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上,然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器.容器是一个运行时环境,就好比是我们前面说到的集装箱. 例如架构图中的客户端(Clien
-
Redis高效检索地理位置的原理解析
Redis GEO 用做存储地理位置信息,并对存储的信息进行操作.通过geo相关的命令,可以很容易在redis中存储和使用经纬度坐标信息.Redis中提供的Geo命令有如下几个: geoadd:添加经纬度坐标和对应地理位置名称. geopos:获取地理位置的经纬度坐标. geodist:计算两个地理位置的距离. georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合. georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合. geoh
-
使用Redis实现令牌桶算法原理解析
在限流算法中有一种令牌桶算法,该算法可以应对短暂的突发流量,这对于现实环境中流量不怎么均匀的情况特别有用,不会频繁的触发限流,对调用方比较友好. 例如,当前限制10qps,大多数情况下不会超过此数量,但偶尔会达到30qps,然后很快就会恢复正常,假设这种突发流量不会对系统稳定性产生影响,我们可以在一定程度上允许这种瞬时突发流量,从而为用户带来更好的可用性体验.这就是使用令牌桶算法的地方. 令牌桶算法原理 如下图所示,该算法的基本原理是:有一个容量为X的令牌桶,每Y单位时间内将Z个令牌放入该桶.如
-
高效异步redis客户端aredis优劣势原理解析
背景 aredis 是一款由同步的 redis 客户端 redis-py 改写而成的高效的异步 redis 客户端,在最新的 1.0.7 版本中完成了对于 redis 集群的支持. 改动 主要重写了底部建立连接和读取数据部分的代码,接口部分都向下兼容,便于使用者从 redis-py 的同步代码迁移到 async 和 await 的协程版本,详细文档请看 aredis 文档 使用 安装 pip install aredis 具体姿势可以参阅项目文档和例子,接口向下兼容 redis-py,支持 Py