关于pytorch相关部分矩阵变换函数的问题分析
目录
- 1、tensor 维度顺序变换 BCHW顺序的调整
- 2、矩阵乘法相关函数,矩阵乘,点乘
- 3、求取矩阵对角线元素,或非对角线元素
1、tensor 维度顺序变换 BCHW顺序的调整
tensor.permute(dims)
将tensor的维度换位。参数是一系列的整数,代表原来张量的维度。比如三维就有0,1,2这些dimension。
import torch a = torch.rand(8,256,256,3) #---> n,h,w,c print(a.shape) b = a.permute(0,3,1,2) # ---> n,c,h,w print(b.shape) #输出 torch.Size([8, 256, 256, 3]) torch.Size([8, 3, 256, 256])
numpy内进行维度顺序变换采用_numy.transpose(a,axis=None)_
参数 a: 输入数组
axis: int类型的列表,这个参数是可选的。默认情况下,反转的输入数组的维度,当给定这个参数时,按照这个参数所定的值进行数组变换。
返回值 p: ndarray 返回转置过后的原数组的视图。
import numpy as ?np ? x = np.random.randn(8,256,256,3) ?# ---> n,h,w,c print(x.shape) y=x.transpose((0,3,1,2)) ? # ?----> n,c,h,w print(y.shape) #输出 (8, 256, 256, 3) (8, 3, 256, 256)
2、矩阵乘法相关函数,矩阵乘,点乘
二维矩阵乘法torch.mm()
torch.mm(mat1,mat2,out=None),其中mat1(NXM),mat2(MXD),输出out的维度为(NXD)
该函数一般只用来计算两个二维矩阵的矩阵乘法,并且不支持broadcast操作。
三维带batch的矩阵乘法 torch.bmm()
由于神经网络训练一般采用mini-batch,经常输入的时三维带batch的矩阵,所以提供torch.bmm(bmat1, bmat2, out=None),其中bmat1(b×n×mb×n×m),bmat2(b×m×db×m×d),输出out的维度是(b×n×db×n×d)。
该函数的两个输入必须是三维矩阵且第一维相同(表示Batch维度),不支持broadcast操作。
多维矩阵乘法 torch.matmul()
torch.matmul(input, other, out=None)支持broadcast操作,使用起来比较复杂。
针对多维数据 matmul()乘法,我们可以认为该matmul()乘法使用使用两个参数的后两个维度来计算,其他的维度都可以认为是batch维度。假设两个输入的维度分别是input(1000×500×99×111000×500×99×11), other(500×11×99500×11×99)那么我们可以认为torch.matmul(input, other, out=None)乘法首先是进行后两位矩阵乘法得到(99×11)×(11×99)(99×99)(99×11)×(11×99)(99×99) ,然后分析两个参数的batch size分别是 (1000×500)(1000×500) 和 500500 , 可以广播成为 (1000×500)(1000×500), 因此最终输出的维度是(1000×500×99×991000×500×99×99)。
矩阵逐元素(Element-wise)乘法 torch.mul()
torch.mul(mat1, other, out=None),其中other乘数可以是标量,也可以是任意维度的矩阵,只要满足最终相乘是可以broadcast的即可
@ :矩阵乘法,自动执行适合的矩阵乘法函数
* :element-wise乘法
3、求取矩阵对角线元素,或非对角线元素
取对角线元素可以用torch.diagonal()
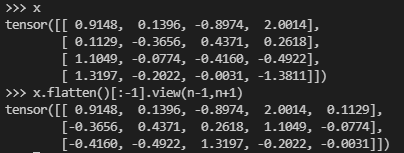
x = torch.randn(4,4) # tensor([[ 0.9148, 0.1396, -0.8974, 2.0014], # [ 0.1129, -0.3656, 0.4371, 0.2618], # [ 1.1049, -0.0774, -0.4160, -0.4922], # [ 1.3197, -0.2022, -0.0031, -1.3811]]) torch.diagonal(x) # tensor([ 0.9148, -0.3656, -0.4160, -1.3811])
非对角线元素没有特定API,如果是求和,可以矩阵求和 减去对角线元素和 。
网上看到一个巧妙的非对角线元素方法
n, m = x.shape assert n == m x.flatten()[:-1].view(n-1,n+1)[:,1:].flatten() # tensor([ 0.1396, -0.8974, 2.0014, 0.1129, 0.4371, 0.2618, 1.1049, -0.0774, # -0.4922, 1.3197, -0.2022, -0.0031])
首先利用flatten()拉直向量,然后去掉最后一个元素,得到n^2 - 1个元素,然后构造为一个维度为[N-1, N+1]的矩阵。在这个矩阵中,之前所有的对角线元素全部出现在第1列,然后根据索引获取[:, 1:]元素,得到的就是原矩阵的非对角线元素。
到此这篇关于pytorch相关部分矩阵变换函数的文章就介绍到这了,更多相关pytorch矩阵变换函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch 转换矩阵的维数位置方法
例如: preds = to_numpy(preds)#preds是[2985x16x2] preds = preds.transpose(2, 1, 0)#preds[2x16x2985] 以上这篇pytorch 转换矩阵的维数位置方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
从Pytorch模型pth文件中读取参数成numpy矩阵的操作
目的: 把训练好的pth模型参数提取出来,然后用其他方式部署到边缘设备. Pytorch给了很方便的读取参数接口: nn.Module.parameters() 直接看demo: from torchvision.models.alexnet import alexnet model = alexnet(pretrained=True).eval().cuda() parameters = model.parameters() for p in parameters: numpy_para =
-
PyTorch 对应点相乘、矩阵相乘实例
一,对应点相乘,x.mul(y) ,即点乘操作,点乘不求和操作,又可以叫作Hadamard product:点乘再求和,即为卷积 data = [[1,2], [3,4], [5, 6]] tensor = torch.FloatTensor(data) tensor Out[27]: tensor([[ 1., 2.], [ 3., 4.], [ 5., 6.]]) tensor.mul(tensor) Out[28]: tensor([[ 1., 4.], [ 9., 16.], [ 25.
-
Numpy与Pytorch 矩阵操作方式
Numpy 随机矩阵: np.random.randn(d0, d1, d2, ...) 矩阵大小与形状: np.ndarray.size 与 np.dnarray.shape Pytorch 随机矩阵: torch.randn(d0, d1, d2, ...) 添加维度: tensor.unsqueeze(0) 压缩维度: tensor.squeeze(0) 按维度拼接tensor: torch.cat(inputs, dim=0, ...) 维度堆叠: torch.stack(inputs,
-

关于pytorch相关部分矩阵变换函数的问题分析
目录 1.tensor 维度顺序变换 BCHW顺序的调整 2.矩阵乘法相关函数,矩阵乘,点乘 3.求取矩阵对角线元素,或非对角线元素 1.tensor 维度顺序变换 BCHW顺序的调整 tensor.permute(dims) 将tensor的维度换位.参数是一系列的整数,代表原来张量的维度.比如三维就有0,1,2这些dimension. import torch a = torch.rand(8,256,256,3) #---> n,h,w,c print(a.shape) b = a.per
-
Python实现矩阵转置的方法分析
本文实例讲述了Python实现矩阵转置的方法.分享给大家供大家参考,具体如下: 前几天群里有同学提出了一个问题:手头现在有个列表,列表里面两个元素,比如[1, 2],之后不断的添加新的列表,往原来相应位置添加.例如添加[3, 4]使原列表扩充为[[1, 3], [2, 4]],再添加[5, 6]扩充为[[1, 3, 5], [2, 4, 6]]等等. 其实不动脑筋的话,用个二重循环很容易写出来: def trans(m): a = [[] for i in m[0]] for i in m: f
-
Pytorch中Softmax与LogSigmoid的对比分析
Pytorch中Softmax与LogSigmoid的对比 torch.nn.Softmax 作用: 1.将Softmax函数应用于输入的n维Tensor,重新改变它们的规格,使n维输出张量的元素位于[0,1]范围内,并求和为1. 2.返回的Tensor与原Tensor大小相同,值在[0,1]之间. 3.不建议将其与NLLLoss一起使用,可以使用LogSoftmax代替之. 4.Softmax的公式: 参数: 维度,待使用softmax计算的维度. 例子: # 随机初始化一个tensor a
-
pytorch分类模型绘制混淆矩阵以及可视化详解
目录 Step 1. 获取混淆矩阵 Step 2. 混淆矩阵可视化 其它分类指标的获取 总结 Step 1. 获取混淆矩阵 #首先定义一个 分类数*分类数 的空混淆矩阵 conf_matrix = torch.zeros(Emotion_kinds, Emotion_kinds) # 使用torch.no_grad()可以显著降低测试用例的GPU占用 with torch.no_grad(): for step, (imgs, targets) in enumerate(test_loader)
-
关于Pytorch的MNIST数据集的预处理详解
关于Pytorch的MNIST数据集的预处理详解 MNIST的准确率达到99.7% 用于MNIST的卷积神经网络(CNN)的实现,具有各种技术,例如数据增强,丢失,伪随机化等. 操作系统:ubuntu18.04 显卡:GTX1080ti python版本:2.7(3.7) 网络架构 具有4层的CNN具有以下架构. 输入层:784个节点(MNIST图像大小) 第一卷积层:5x5x32 第一个最大池层 第二卷积层:5x5x64 第二个最大池层 第三个完全连接层:1024个节点 输出层:10个节点(M
-
pytorch学习教程之自定义数据集
自定义数据集 在训练深度学习模型之前,样本集的制作非常重要.在pytorch中,提供了一些接口和类,方便我们定义自己的数据集合,下面完整的试验自定义样本集的整个流程. 开发环境 Ubuntu 18.04 pytorch 1.0 pycharm 实验目的 掌握pytorch中数据集相关的API接口和类 熟悉数据集制作的整个流程 实验过程 1.收集图像样本 以简单的猫狗二分类为例,可以在网上下载一些猫狗图片.创建以下目录: data-------------根目录 data/test-------测
-
python中numpy矩阵的零填充的示例代码
目录 需求: 一.再new一个更大的所需要的矩阵大小 二.pad函数 其他想法 需求: 对于图像处理中的一些过程,我需要对读取的numpy矩阵进行size的扩充,比如原本是(4,6)的矩阵,现在需要上下左右各扩充3行,且为了不影响数值计算,都用0填充. 比如下图,我有一个4x5大小的全1矩阵,但是现在我要在四周都加上3行的0来扩充大小,最后扩充完还要对原区域进行操作. 方法: 想到了几种方法,记录一下. 一.再new一个更大的所需要的矩阵大小 a = np.ones((4,5)) #假设原矩阵是
-
使用java写的矩阵乘法实例(Strassen算法)
Strassen算法于1969年由德国数学家Strassen提出,该方法引入七个中间变量,每个中间变量都只需要进行一次乘法运算.而朴素算法却需要进行8次乘法运算. 原理 Strassen算法的原理如下所示,使用sympy验证Strassen算法的正确性 import sympy as s A = s.Symbol("A") B = s.Symbol("B") C = s.Symbol("C") D = s.Symbol("D"
-
Java实现矩阵乘法以及优化的方法实例
传统的矩阵乘法实现 首先,两个矩阵能够相乘,必须满足一个前提:前一个矩阵的行数等于后一个矩阵的列数. 第一个矩阵的第m行和第二个矩阵的第n列的乘积和即为乘积矩阵第m行第n列的值,可用如下图像表示这个过程. 矩阵乘法过程展示 C[1][1] = A[1][0] * B[0][1] + A[1][1] * B[1][1] + A[1][2] * B[2][1] + A[1][3] * B[3][1] + A[1][4] * B[4][1] 而用Java实现该过程的传统方法就是按照该规则实
-
NumPy 矩阵乘法的实现示例
NumPy 支持的几类矩阵乘法也很重要. 元素级乘法 你已看过了一些元素级乘法.你可以使用 multiply 函数或 * 运算符来实现.回顾一下,它看起来是这样的: m = np.array([[1,2,3],[4,5,6]]) m # 显示以下结果: # array([[1, 2, 3], # [4, 5, 6]]) n = m * 0.25 n # 显示以下结果: # array([[ 0.25, 0.5 , 0.75], # [ 1. , 1.25, 1.5 ]]) m * n # 显示以