Python实现解析参数的三种方法详解
目录
- 先决条件
- 使用 argparse
- 使用 JSON 文件
- 使用 YAML 文件
- 最后的想法
今天我们分享的主要目的就是通过在 Python 中使用命令行和配置文件来提高代码的效率
Let's go!
我们以机器学习当中的调参过程来进行实践,有三种方式可供选择。第一个选项是使用 argparse,它是一个流行的 Python 模块,专门用于命令行解析;另一种方法是读取 JSON 文件,我们可以在其中放置所有超参数;第三种也是鲜为人知的方法是使用 YAML 文件!好奇吗,让我们开始吧!

先决条件
在下面的代码中,我将使用 Visual Studio Code,这是一个非常高效的集成 Python 开发环境。这个工具的美妙之处在于它通过安装扩展支持每种编程语言,集成终端并允许同时处理大量 Python 脚本和 Jupyter 笔记本
当然如果你还不知道怎么配置 VSCode,可以看这里
手把手将Visual Studio Code变成Python开发神器
数据集,使用的是Kaggle 上的共享自行车数据集,可以在这里下载或者在文末获取
使用 argparse
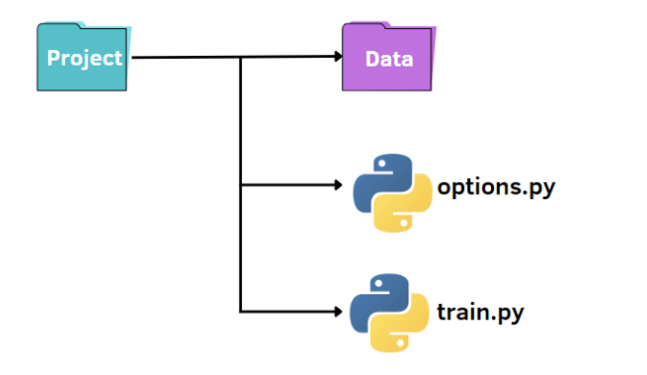
就像上图所示,我们有一个标准的结构来组织我们的小项目:
- 包含我们数据集的名为 data 的文件夹
- train.py 文件
- 用于指定超参数的 options.py 文件
首先,我们可以创建一个文件 train.py,在其中我们有导入数据、在训练数据上训练模型并在测试集上对其进行评估的基本程序:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('data\hour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)
在代码中,我们还导入了包含在 options.py 文件中的 train_options 函数。后一个文件是一个 Python 文件,我们可以从中更改 train.py 中考虑的超参数:
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return opt
在这个例子中,我们使用了 argparse 库,它在解析命令行参数时非常流行。首先,我们初始化解析器,然后,我们可以添加我们想要访问的参数。
这是运行代码的示例:
python train.py

要更改超参数的默认值,有两种方法。第一个选项是在 options.py 文件中设置不同的默认值。另一种选择是从命令行传递超参数值:
python train.py --n_estimators 200
我们需要指定要更改的超参数的名称和相应的值。
python train.py --n_estimators 200 --max_depth 7
使用 JSON 文件
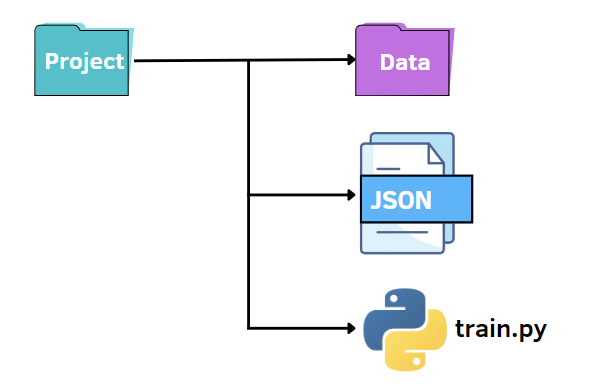
和前面一样,我们可以保持类似的文件结构。在这种情况下,我们将 options.py 文件替换为 JSON 文件。换句话说,我们想在 JSON 文件中指定超参数的值并将它们传递给 train.py 文件。与 argparse 库相比,JSON 文件可以是一种快速且直观的替代方案,它利用键值对来存储数据。下面我们创建一个 options.json 文件,其中包含我们稍后需要传递给其他代码的数据。
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}
如上所见,它与 Python 字典非常相似。但是与字典不同的是,它包含文本/字符串格式的数据。此外,还有一些语法略有不同的常见数据类型。例如,布尔值是 false/true,而 Python 识别 False/True。JSON 中其他可能的值是数组,它们用方括号表示为 Python 列表。
在 Python 中使用 JSON 数据的美妙之处在于,它可以通过 load 方法转换成 Python 字典:
f = open("options.json", "rb")
parameters = json.load(f)
要访问特定项目,我们只需要在方括号内引用它的键名:
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
使用 YAML 文件
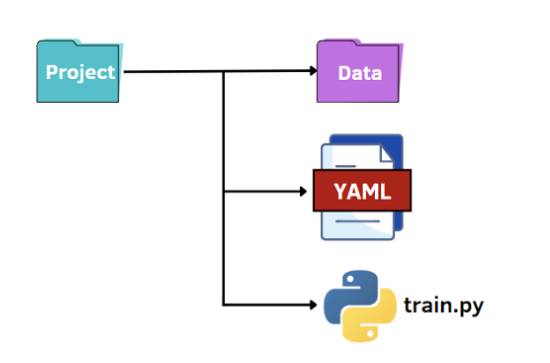
最后一种选择是利用 YAML 的潜力。与 JSON 文件一样,我们将 Python 代码中的 YAML 文件作为字典读取,以访问超参数的值。YAML 是一种人类可读的数据表示语言,其中层次结构使用双空格字符表示,而不是像 JSON 文件中的括号。下面我们展示 options.yaml 文件将包含的内容:
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
在 train.py 中,我们打开 options.yaml 文件,该文件将始终使用 load 方法转换为 Python 字典,这一次是从 yaml 库中导入的:
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)
和前面一样,我们可以使用字典所需的语法访问超参数的值。
最后的想法
配置文件的编译速度非常快,而 argparse 则需要为我们要添加的每个参数编写一行代码。
所以我们应该根据自己的不同情况来选择最为合适的方式
例如,如果我们需要为参数添加注释,JSON 是不合适的,因为它不允许注释,而 YAML 和 argparse 可能非常适合。
到此这篇关于Python实现解析参数的三种方法详解的文章就介绍到这了,更多相关Python解析参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Selenium参数配置方法解析
这篇文章主要介绍了Python Selenium参数配置方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 selenium.获取浏览器大小.设置浏览器位置.最大化浏览器 get_window_size() 获取浏览器大小 # 将窗口大小实例化 size_Dict = driver.get_window_size() # 打印浏览器的宽和高 print("当前浏览器的宽:", size_Dict['width']) print(&
-
python函数不定长参数使用方法解析
这篇文章主要介绍了python函数不定长参数使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 pathon中的函数可以使用不定长参数,可以用参数*args接收单个出现的参数,接收后存成一个元组:用**kwargs接收以键值对形式出现的参数,接收后存丰一个字典.下面的小程序能说明这个问题 代码如下: def print_info(*args,**kwargs): for i in args: print(i) for i in kwar
-
Python -m参数原理及使用方法解析
python -m xxx.py 作用是:把xxx.py文件当做模块启动 但是我一直不明白当做模块启动到底有什么用.python xxx.py和python -m xxx.py有什么区别! 自问自答: python xxx.py python -m xxx.py 这是两种加载py文件的方式: 1叫做直接运行 2把模块当作脚本来启动(注意:但是__name__的值为'main' ) 不同的加载py文件的方式,主要是影响--sys.path 这个属性.sys.path 就相当于liunx中的PATH
-

python解析命令行参数的三种方法详解
这篇文章主要介绍了python解析命令行参数的三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python解析命令行参数主要有三种方法:sys.argv.argparse解析.getopt解析 方法一:sys.argv -- 命令行执行:python test_命令行传参.py 1,2,3 1000 # test_命令行传参.py import sys def para_input(): print(len(sys.argv)) #
-
python默认参数调用方法解析
这篇文章主要介绍了python默认参数调用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 最常见的一种形式是的是为一个或者多个参数指定默认值,这会创建一个可以使用比定义时允许的参数更少的参数调用的函数, def ask_ok(prompt, retries=4, reminder='Please try again!'): while True: ok = input(prompt) if ok in ('y', 'ye', 'yes'
-
Python解析命令行读取参数--argparse模块使用方法
在多个文件或者不同语言协同的项目中,python脚本经常需要从命令行直接读取参数.万能的python就自带了argprase包使得这一工作变得简单而规范.PS:optparse包是类似的功能,只不过写起来更麻烦一些. 如果脚本很简单或临时使用,没有多个复杂的参数选项,可以直接利用sys.argv将脚本后的参数依次读取(读进来的默认是字符串格式).比如如下名为test.py的脚本: import sys print "Input argument is %s" %(sys.argv[0]
-
Python实现解析参数的三种方法详解
目录 先决条件 使用 argparse 使用 JSON 文件 使用 YAML 文件 最后的想法 今天我们分享的主要目的就是通过在 Python 中使用命令行和配置文件来提高代码的效率 Let's go! 我们以机器学习当中的调参过程来进行实践,有三种方式可供选择.第一个选项是使用 argparse,它是一个流行的 Python 模块,专门用于命令行解析:另一种方法是读取 JSON 文件,我们可以在其中放置所有超参数:第三种也是鲜为人知的方法是使用 YAML 文件!好奇吗,让我们开始吧! 先决条件
-
Python实现重建二叉树的三种方法详解
本文实例讲述了Python实现重建二叉树的三种方法.分享给大家供大家参考,具体如下: 学习算法中,探寻重建二叉树的方法: 用input 前序遍历顺序输入字符重建 前序遍历顺序字符串递归解析重建 前序遍历顺序字符串堆栈解析重建 如果懒得去看后面的内容,可以直接点击此处本站下载完整实例代码. 思路 学习算法中,python 算法方面的资料相对较少,二叉树解析重建更少,只能摸着石头过河. 通过不同方式遍历二叉树,可以得出不同节点的排序.那么,在已知节点排序的前提下,通过某种遍历方式,可以将排序进行解析
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
Python图片存储和访问的三种方式详解
目录 前言 数据准备 一个可以玩的数据集 图像存储的设置 LMDB HDF5 单一图像的存储 存储到 磁盘 存储到 LMDB 存储 HDF5 存储方式对比 多个图像的存储 多图像调整代码 准备数据集对比 单一图像的读取 从 磁盘 读取 从 LMDB 读取 从 HDF5 读取 读取方式对比 多个图像的读取 多图像调整代码 准备数据集对比 读写操作综合比较 数据对比 并行操作 前言 ImageNet 是一个著名的公共图像数据库,用于训练对象分类.检测和分割等任务的模型,它包含超过 1400 万张图像
-
SpringMVC统一异常处理三种方法详解
这篇文章主要介绍了SpringMVC-统一异常处理三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在 Spring MVC 应用的开发中,不管是对底层数据库操作,还是业务层或控制层操作,都会不可避免地遇到各种可预知的.不可预知的异常需要处理. 如果每个过程都单独处理异常,那么系统的代码耦合度高,工作量大且不好统一,以后维护的工作量也很大. 如果能将所有类型的异常处理从各层中解耦出来,这样既保证了相关处理过程的功能单一,又实现了异常信
-
Mybatis 逆向工程的三种方法详解
Mybatis 逆向工程 逆向工程通常包括由数据库的表生成 Java 代码 和 通过 Java 代码生成数据库表.而Mybatis 逆向工程是指由数据库表生成 Java 代码. Mybaits 需要程序员自己编写 SQL 语句,但是 Mybatis 官方提供逆向工程可以针对单表自动生成 Mybaits 执行所需要的代码,包括 POJO.Mapper.java.Mapper.xml -. 一.通过 Eclipse 插件完成 Mybatis 逆向工程 1. 在线安装 Eclipse 插件
-
Python Process创建进程的2种方法详解
前面介绍了使用 os.fork() 函数实现多进程编程,该方法最明显的缺陷就是不适用于 Windows 系统.本节将介绍一种支持 Python 在 Windows 平台上创建新进程的方法. Python multiprocessing 模块提供了 Process 类,该类可用来在 Windows 平台上创建新进程.和使用 Thread 类创建多线程方法类似,使用 Process 类创建多进程也有以下 2 种方式: 直接创建 Process 类的实例对象,由此就可以创建一个新的进程: 通过继承 P
-
Python写入MySQL数据库的三种方式详解
目录 场景一:数据不需要频繁的写入mysql 场景二:数据是增量的,需要自动化并频繁写入mysql 方式一 方式二 总结 大家好,Python 读取数据自动写入 MySQL 数据库,这个需求在工作中是非常普遍的,主要涉及到 python 操作数据库,读写更新等,数据库可能是 mongodb. es,他们的处理思路都是相似的,只需要将操作数据库的语法更换即可. 本篇文章会给大家分享数据如何写入到 mysql,分为两个场景,三种方式. 场景一:数据不需要频繁的写入mysql 使用 navicat 工
-
python修改文件内容的3种方法详解
这篇文章主要介绍了python修改文件内容的3种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.修改原文件方式 def alter(file,old_str,new_str): """ 替换文件中的字符串 :param file:文件名 :param old_str:就字符串 :param new_str:新字符串 :return: """ file_data = "&qu