Python 处理表格进行成绩排序的操作代码
一、需求分析
我们首先有一个成绩表单,但是学生的成绩是按照学号进行排序的,现在,我们希望清晰明了的知道每一个学生的名次,并且需要将学生按照成绩的高低重新进行排序。
也就是说,我们将学生从按照学号排序转变为按照成绩从高到低进行排序。
二、代码呈现
这个需求其实比较简单,于是,我们直接呈现代码,主要问题是Excel表格的读写操作,这个解决以后就十分简单了。
Excel读:xlrd模块
Excel写:xlwt模块
代码以及解释如下:
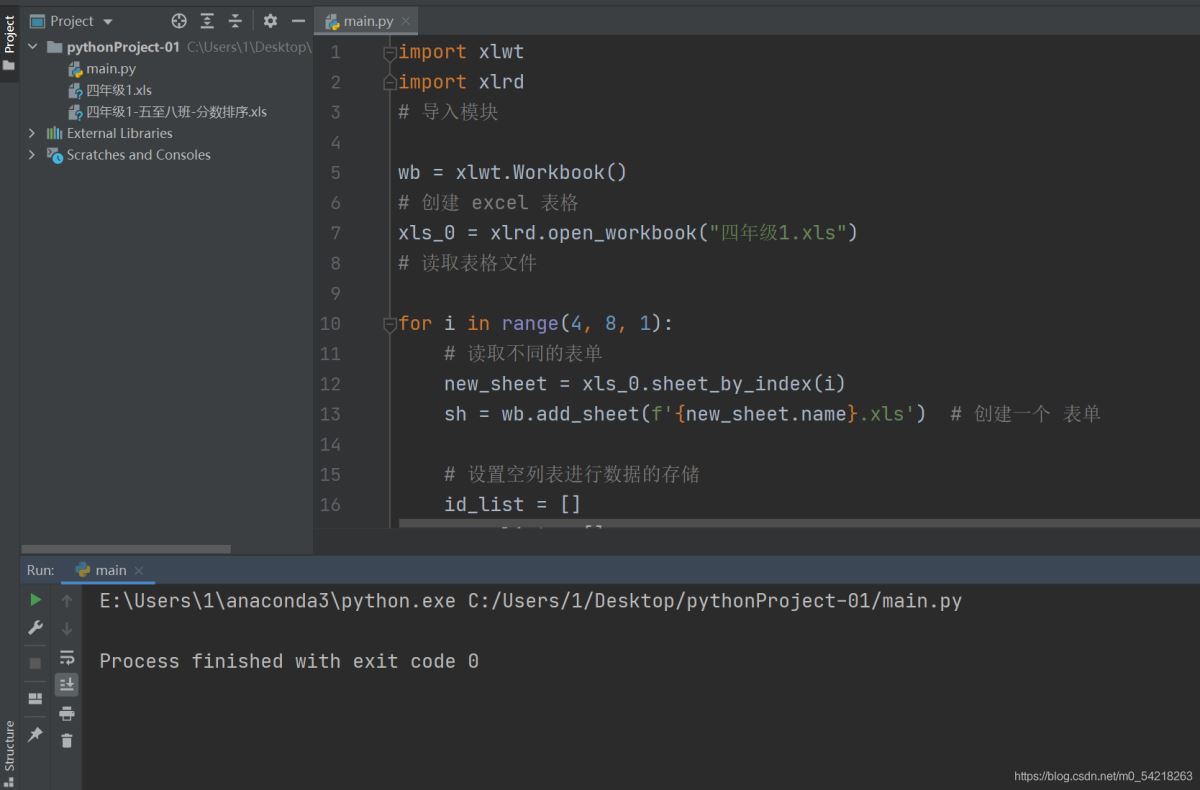
import xlwt
import xlrd
# 导入模块
wb = xlwt.Workbook()
# 创建 excel 表格
xls_0 = xlrd.open_workbook("四年级1.xls")
# 读取表格文件
for i in range(4, 8, 1):
# 读取不同的表单
new_sheet = xls_0.sheet_by_index(i)
sh = wb.add_sheet(f'{new_sheet.name}.xls') # 创建一个 表单
# 设置空列表进行数据的存储
id_list = []
name_list = []
score_list = []
# 读取表格的数据
for o in range(3): # 3 列
for t in range(20): # 20 行
# 获取学号、姓名、成绩等信息
id_list.append(new_sheet.cell(t + 3, 3 * o).value)
name_list.append(new_sheet.cell(t + 3, 3 * o + 1).value)
score_list.append(new_sheet.cell(t + 3, 3 * o + 2).value)
# 获取数据
# 进行一定的预处理,去除不存在的人
# 意思是说:有些位置是空的,这些位置需要去除掉
for number in range(len(id_list)):
# 由于进行的是删除操作,所以可能会出现下标越界的情况,为了防止这种情况的出现,我们进行异常处理
try:
if name_list[number] == '' or score_list[number] == '' or score_list[number] == '请假':
# 这个实际上是去除空值
id_list.pop(number)
name_list.pop(number)
score_list.pop(number)
except:
continue
# 去除不存在的人
# 进行排序的操作
for h in range(len(id_list)):
# len(id_list) 次循环
for s in range(len(id_list) - 1):
# 这里是进行 len(id_list) - 1 次循环
try:
if score_list[s] >= score_list[s + 1]:
pass
else:
score_list[s], score_list[s + 1] = score_list[s + 1], score_list[s]
name_list[s], name_list[s + 1] = name_list[s + 1], name_list[s]
id_list[s], id_list[s + 1] = id_list[s + 1], id_list[s]
except:
continue
# 冒泡排序
# 将数据写入文件
position = 0
for h in range(len(id_list)):
# 写入文件
sh.write(position, 0, id_list[h])
sh.write(position, 1, name_list[h])
sh.write(position, 2, score_list[h])
position += 1
# 写入文件中去
# 保存文件
wb.save(f'四年级1-五至八班-分数排序.xls')
# 保存
在这里,我们使用了冒泡排序,当然,如果想要运行的更快一些,可以考虑希尔排序,堆排序,快速排序等排序方式,但是要注意,学号、姓名、分数一定要同时进行排序,就是说这三个量应该捆绑在一起移动,而移动的原则就是分数高低。
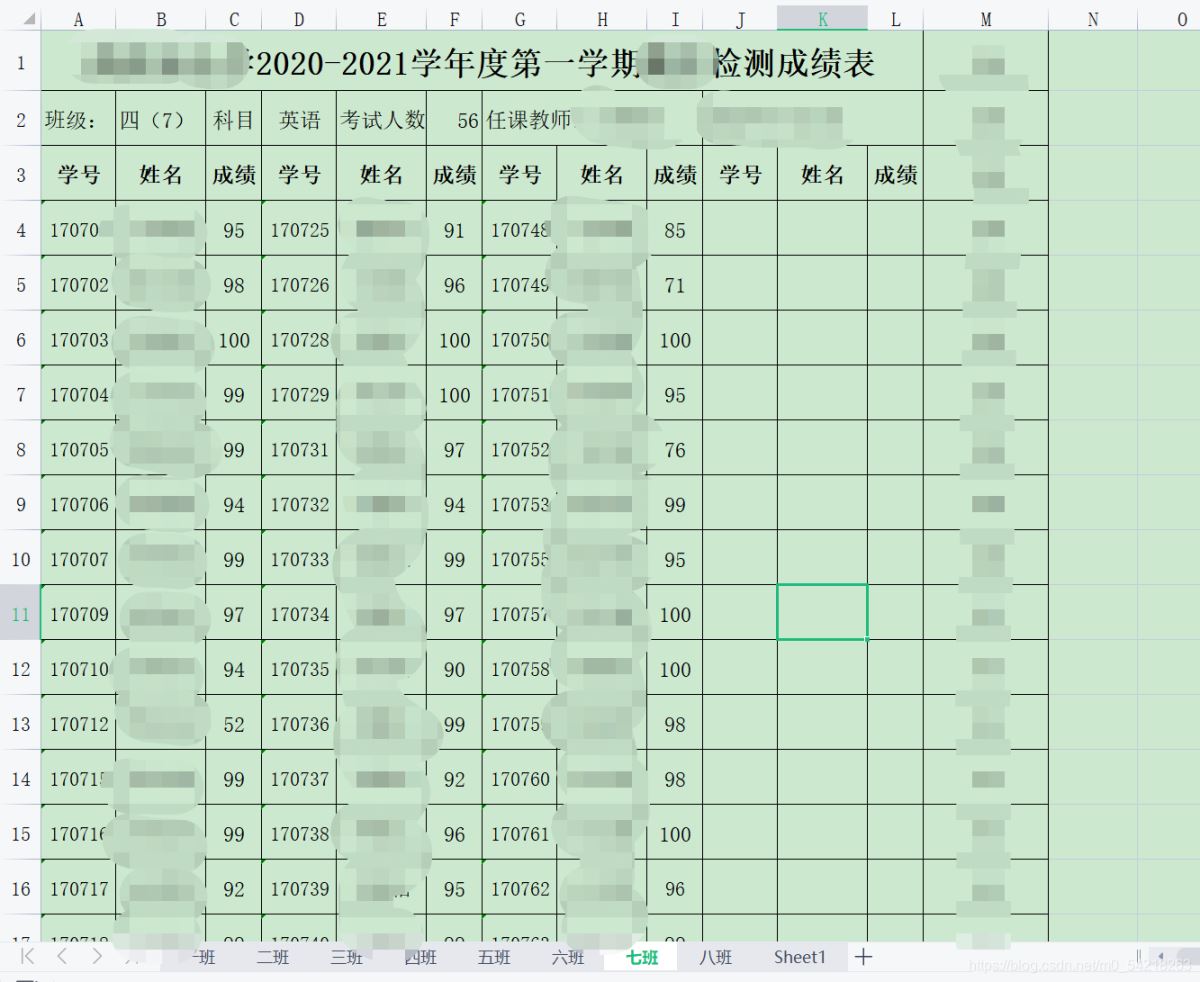
三、成果展示
图片1、
图片2、
图片3、
图片4、

到此这篇关于Python 处理表格进行成绩排序的操作代码的文章就介绍到这了,更多相关Python成绩排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现EXCEL表格的排序功能示例
EXCEL的数值排序功能还是挺强大的,升序.降序,尤其自定义排序,能够对多个字段进行排序工作. 那么,在Python大法中,有没有这样强大的排序功能呢?答案是有的,而且本人觉得Python的排序功能,一点不比EXCEL的差. 同样,我们依然用到的是强大的pandas这个三方库.我们先将numpy和pandas导入进来: 接着构造一个今天要用到的DataFrame,我们用字典的形式来构造. 都是随意构造的,内容别较真.我们先来个简单点的热热身,按照身高的降序来排列一下. 我们用到的是df.sort
-
Python CategoricalDtype自定义排序实现原理解析
CategoricalDtype自定义排序 当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序.排序有很多种方法.例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了. 对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了.默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求.所以通过CategoricalDtye可以把数据类型转成Category类型 然后通过指定参数列表的顺序来自定义那个元素先那个元
-
用python给csv里的数据排序的具体代码
1.使用argparse组件,获取命令行参数:使用re组件,获取需要查找的字符串所在行 2.使用pandas组件,对文件进行排序. 3.命令行执行数据获取及排序,写入文件: 以下是完整代码: #coding:utf-8 import re import argparse import pandas as pd parser = argparse.ArgumentParser(description='manual to this script') parser.add_argument('--i
-
python文件排序的方法总结
在python环境中提供两种排序方案:用库函数sorted()对字符串排序,它的对象是字符:用函数sort()对数字排序,它的对象是数字,如果读取文件的话,需要进行处理(把文件后缀名'屏蔽'). (1)首先:我测试的文件夹是/img/,里面的文件都是图片,如下图所示: (2)测试库函数sorted(),直接贴出代码: import numpy as np import os img_path='./img/' img_list=sorted(os.listdir(img_path))#文
-

Python 处理表格进行成绩排序的操作代码
一.需求分析 我们首先有一个成绩表单,但是学生的成绩是按照学号进行排序的,现在,我们希望清晰明了的知道每一个学生的名次,并且需要将学生按照成绩的高低重新进行排序. 也就是说,我们将学生从按照学号排序转变为按照成绩从高到低进行排序. 二.代码呈现 这个需求其实比较简单,于是,我们直接呈现代码,主要问题是Excel表格的读写操作,这个解决以后就十分简单了. Excel读:xlrd模块 Excel写:xlwt模块 代码以及解释如下: import xlwt import xlrd # 导入模块 wb
-
design vue 表格开启列排序的操作
开启排序 1.本地数据排序 column数据设置,需要开启的列设置sorter: (a, b) => a.address.length - b.address.length, 自定义排序方法 2.服务端排序sorter设置true 点击排序,表格触发change方法,接受参数 change (pagination, filters, sorter, { currentDataSource }) 第三个参数就是排序信息 {field, order} <a-table :columns="
-
Python中join()函数多种操作代码实例
这篇文章主要介绍了Python中join()函数多种操作代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python中有.join()和os.path.join()两个函数,具体作用如下: . join(): 连接字符串数组.将字符串.元组.列表中的元素以指定的字符(分隔符)连接生成一个新的字符串 os.path.join(): 将多个路径组合后返回 对序列进行操作(分别使用' ' .' - '与':'作为分隔符) a=['1aa','
-
python 装饰器(Decorators)原理说明及操作代码
目录 1 必要的2个核心操作 1.1 核心操作1, 函数内部可以定义函数 1.2 核心操作2 函数可以作为对象被输入输出 1.2.1 核心操作2的前置条件,函数是对象 1.2.2函数作为输入 1.2.3 函数作为输出 2 尝试构造装饰器 3装饰器定义的简写 本文目的是由浅入深地介绍python装饰器原理 装饰器(Decorators)是 Python 的一个重要部分 其功能是,在不修改原函数(类)定义代码的情况下,增加新的功能 为了理解和实现装饰器,我们先引入2个核心操作: 1 必要的2个核心操
-
Python压缩包处理模块zipfile和py7zr操作代码
目录 一:zipfile的常用操作 1,压缩文件 2,解压缩文件 3,列出压缩包里的所有文件 4,其他常用的方法 二:py7zr的常用操作 1,压缩文件 2,解压缩文件 目前对文件的压缩和解压缩比较常用的格式就是zip格式和7z格式,今天就以一篇文章来融会贯通会该两个压缩文件格式的操作. 一:zipfile的常用操作 1,压缩文件 zipfile.ZipFile(file[, mode[, compression[, allowZip64]]]) 参数file表示文件的路径:参数mode指示打开
-
python算法学习之计数排序实例
python算法学习之计数排序实例 复制代码 代码如下: # -*- coding: utf-8 -*- def _counting_sort(A, B, k): """计数排序,伪码如下: COUNTING-SORT(A, B, k) 1 for i ← 0 to k // 初始化存储区的值 2 do C[i] ← 0 3 for j ← 1 to length[A] // 为各值计数 4 do C[A[j]] ← C[A
-
jquery实现表格行拖动排序
本文实例为大家分享了jquery实现表格行拖动排序的具体代码,供大家参考,具体内容如下 引入JS <script src="jquery.min.js"></script> <script src="jquery-ui.min.js"></script> html代码 <!doctype html> <html> <head> <meta charset="U
-
Python如何利用xlrd和xlwt模块操作Excel表格
目录 简介: 安装: 初始数据: xlrd使用: xlwt使用: xlwt使用示例2: 总结 简介: xlrd和xlwt是python的第三方库,xlrd模块实现对excel文件内容读取,xlwt模块实现对excel文件的写入. 安装: pip install xlrd pip install xlwt 初始数据: excelLearn.xls 个人信息表: 姓名 年龄 地址 Tom 26 CN Jo 27 UK Lily 28 US Kim 29 JP 班级成绩表: 考试日期 班级 分数 20
-
javascript实现对表格元素进行排序操作
我们在上网中都能看到很多能够排序的,如大小.时间.价格等 现在我们也试一下排序功能: 排序的函数代码:里面含有点击之后排序--还原,和排升序和降序. function sortAge(){ //对年龄进行排序,要先进行获得每一行对象,然后对象对象中的第一个(从0 开始)的大小进行排序 var tabNode = document.getElementById("tabid"); var rows0 = tabNode.rows; var rows1 = []; //现将元素拷贝一份出来
-
python 删除excel表格重复行,数据预处理操作
使用python删除excel表格重复行. # 导入pandas包并重命名为pd import pandas as pd # 读取Excel中Sheet1中的数据 data = pd.DataFrame(pd.read_excel('test.xls', 'Sheet1')) # 查看读取数据内容 print(data) # 查看是否有重复行 re_row = data.duplicated() print(re_row) # 查看去除重复行的数据 no_re_row = data.drop_d