SQL Server删除表中的重复数据
添加示例数据
create table Student(
ID varchar(10) not null,
Name varchar(10) not null,
);
insert into Student values('1', 'zhangs');
insert into Student values('2', 'zhangs');
insert into Student values('3', 'lisi');
insert into Student values('4', 'lisi');
insert into Student values('5', 'wangwu');
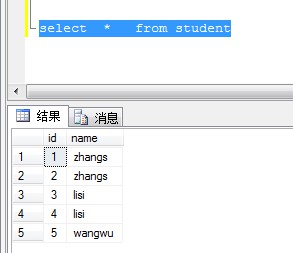
删除Name重复多余的行,每个Name仅保留1行数据
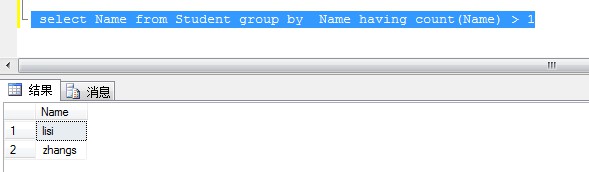
1、查询表中Name 重复的数据
select Name from Student group by Name having count(Name) > 1
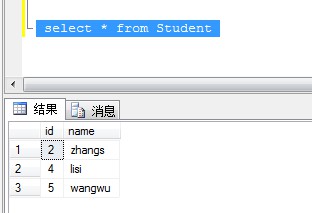
2、有唯一列,通过唯一列最大或最小方式删除重复记录
检查表中是否有主键或者唯一值的列,当前可以数据看到ID是唯一的,可以通过Name分组排除掉ID最大或最小的行
delete from Student where Name in( select Name from Student group by Name having count(Name) > 1) and ID not in(select max(ID) from Student group by Name having count(Name) > 1 )
执行删除脚本后查询
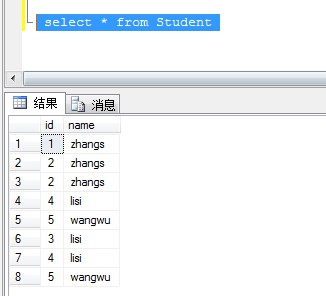
3、无唯一列使用ROW_NUMBER()函数删除重复记录
如果表中没有唯一值的列,可以通过row_number 来删除重复数据
重复执行插入脚本,查看表数据,表中没有唯一列值
Delete T From (Select Row_Number() Over(Partition By [Name] order By [ID]) As RowNumber,* From Student)T Where T.RowNumber > 1
小知识点
语法:ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
表示根据COLUMN分组,在分组内部根据 COLUMN排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
函数“Row_Number”必须有 OVER 子句。OVER 子句必须有包含 ORDER BY
Row_Number() Over(Partition By [Name] order By [ID]) 表示已name列分组,在每组内以ID列进行升序排序,每组内返回一个唯一的序号
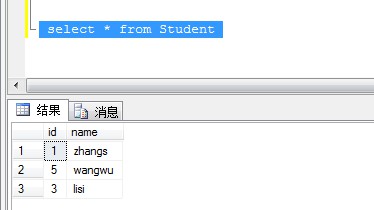
执行删除脚本后查询表数据
到此这篇关于SQL Server删除表中重复数据的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
分享SQL Server删除重复行的6个方法
1.如果有ID字段,就是具有唯一性的字段 复制代码 代码如下: delect table where id not in ( select max(id) from table group by col1,col2,col3... ) group by 子句后跟的字段就是你用来判断重复的条件,如只有col1,那么只要col1字段内容相同即表示记录相同. 2. 如果是判断所有字段也可以这样 复制代码 代码如下: select * into #aa from table group by id1,i
-

SQL Server2008中删除重复记录的方法分享
现在让我们来看在SQL SERVER 2008中如何删除这些记录, 首先,可以模拟造一些简单重复记录: 复制代码 代码如下: Create Table dbo.Employee ( [Id] int Primary KEY , [Name] varchar(50), [Age] int, [Sex] bit default 1 ) Insert Into Employee ([Id] , [Name] , [Age] , [Sex] ) Values(1,'James',25,default)
-
Sql Server里删除数据表中重复记录的例子
[项目] 数据库中users表,包含u_name,u_pwd两个字段,其中u_name存在重复项,现在要实现把重复的项删除! [分析] 1.生成一张临时表new_users,表结构与users表一样: 2.对users表按id做一个循环,每从users表中读出一个条记录,判断new_users中是否存在有相同的u_name,如果没有,则把它插入新表:如果已经有了相同的项,则忽略此条记录: 3.把users表改为其它的名称,把new_users表改名为users,实现我们的需要. [程序] 复制代
-
SqlServer 2005中使用row_number()在一个查询中删除重复记录
下面我们来看下,如何利用它来删除一个表中重复记录: 复制代码 代码如下: If Exists(Select * From tempdb.Information_Schema.Tables Where Table_Name Like '#Temp%') Drop Table #temp Create Table #temp ([Id] int, [Name] varchar(50), [Age] int, [Sex] bit default 1) Go Insert Into #temp ([Id
-
SQL Server中删除重复数据的几个方法
方法一 复制代码 代码如下: declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) > 1 open cur_rows fetch cur_rows into @id,@max while @@fetch_status=0 begin select @max = @max -1 set rowcount
-
sqlserver 删除重复记录处理(转)
注:此处"重复"非完全重复,意为某字段数据重复 HZT表结构 ID int Title nvarchar(50) AddDate datetime 数据 一. 查找重复记录 1. 查找全部重复记录 Select * From 表 Where 重复字段 In (Select 重复字段 From 表 Group By 重复字段 Having Count(*)>1) 2. 过滤重复记录(只显示一条) Select * From HZT Where ID In (Select Max(I
-
SQL Server数据库删除数据集中重复数据实例讲解
SQL Server数据库操作中,有时对于表中的结果集,满足一定规则我们则认为是重复数据,而这些重复数据需要删除.如何删除呢?本文我们通过一个例子来加以说明. 例子如下: 如下只要companyName,invoiceNumber,customerNumber三者都相同,我们则认为是重复数据,下面的例子演示了如何删除. declare @InvoiceListMaster table ( ID int identity primary key , companyName Nchar(20), i
-
SQL SERVER 删除重复内容行
对于重复行删除的问题,网上很难找到合适的答案,问问题的不少,但在搜索引擎中草草地看了一下前面的记录都没有解决方案. 其实这个问题可以很华丽的解决. 1.如果这张表没有主键(或者相同的行并没有不相同的内容列),则需要新建一个自增列,用来区分不同列.例如 复制代码 代码如下: alter table [tablename] add [TID] int IDENTITY(1,1) 就是增加一个自增量的临时列TID. 为啥要用SQL语句?如果超过几十万行的话用SQL SERVER企业管理器的设计界面修改
-
教你几种在SQLServer中删除重复数据方法
方法一 复制代码 代码如下: declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) > 1 open cur_rows fetch cur_rows into @id,@max while @@fetch_status=0 begin select @max = @max -1 set rowcount
-
SqlServer2005中使用row_number()在一个查询中删除重复记录的方法
下面我们来看下,如何利用它来删除一个表中重复记录: 复制代码 代码如下: If Exists(Select * From tempdb.Information_Schema.Tables Where Table_Name Like '#Temp%') Drop Table #temp Create Table #temp ([Id] int, [Name] varchar(50), [Age] int, [Sex] bit default 1) Go Insert Into #temp ([Id