C++高级数据结构之二叉查找树
目录
- 高级数据结构(Ⅳ)二叉查找树
- 基础概念
- 基本实现
- 数据表示
- 查找
- 插入
- 有序性相关的方法
- 最小键和最大键
- 向上取整和向下取整
- 选择操作
- 排名
- 范围查找
- 与删除相关的方法
- 删除最小键
- 删除最大键
- 删除操作
- 性能分析
- 完整代码和测试
- 完整代码
- 测试
前言:
- 文章目录
- 基础概念
- 基本实现
- 有序性相关的方法
- 与删除相关的方法
- 性能分析
- 完整代码和测试
高级数据结构(Ⅳ)二叉查找树
基础概念
此数据结构由结点组成,结点包含的链接可以为空(null)或者指向其他结点。在二叉树中,每个结点只能有一个父结点(只有一个例外,也就是根结点,它没有父结点),而且每个结点都只有左右两个链接,分别指向自己的左子结点和右子结点。每个结点的两个链接都指向了一棵独立的子二叉树或空链接。在二叉查找树中,每个结点还包含了一个键和一个值,键之间也有顺序之分以支持高校的查找。
定义:一棵二叉查找树(BST)是一棵二叉树,
其中每个结点都含有一个Comparable的键(以及相关联的值)
且每个结点的键都大于其左子树中的任意结点的键而小于右子树的任意结点的键。
以int类型为键,string类型为值的二叉查找树的API如下:
class BST<Key extends Comparable<Key>, Value>
-------------------------------------------------------------------------------------
Node root; 根结点
int size(Node x); 返回以结点x为根节点的子树大小
Value get(Key key) 返回键key对应的值
void put(Key key, Value val) 插入键值对{key : val}
Key min() 返回最小键
Key max() 返回最大键
Key floor(Key key) 向下取整(返回小于等于key的最大值)
Key ceiling(Key key) 向上取整(返回大于等于key的最小值)
Key select(int k) 返回排名为k的键
int rank(Key key) 返回键key的排名
Iterable<Key> keys(Key lo, Key hi) 返回查找(返回指定范围内的所有键值)
void deleteMin() 删除最小键
void deleteMax() 删除最大键
void delete (Key key) 删除键key
基本实现
数据表示
我们嵌套定义一个私有类来表示二叉查找树上的一个结点。每个结点都含有一个键、一个值、一条左链接、一条右链接和一个结点计数器。左链接指向一棵由小于该结点的所有键组成的二叉查找树,右链接指向一棵由大于该结点的所有键组成的二叉查找树。变量N给出了以该结点为根的子树的结点总数。
实现:
class BST<Key extends Comparable<Key>, Value> {
private Node root; //二叉查找树的根节点
private class Node{
private Key key; //键
private Value val; //值
private Node left, right; //指向子树的链接
private int N; //以该结点为根的子树中的结点总数
public Node(Key key, Value val, int N) {
this.key = key;
this.val = val;
this.N = N;
}
}
public int size() {
return size(root);
}
private int size(Node x) {
if (x == null) {
return 0;
} else {
return x.N;
}
}
}
一棵二叉查找树代表了一组键(及其相应的值)的集合,而同一个集合可以用多棵不同的二叉查找树表示。如果我们将一棵二叉查找树的所有键投影到一条直线上,保证一个结点的左子树中的键出现在它的左边,右子树中的键出现在它的右边,那么我们一定可以得到一条有序的键列。
查找
一般来说,在符号表中查找一个键可能得到两种结果。如果含有该键的结点存在于表中,我们的查找就命中了,然后返回相应的值。否则查找未命中(并返回null)。根据数据表示的递归结构我们马上就能得到,在二叉查找树中查找一个键的递归算法:如果树是空的,则查找未命中;如果被查找的键和根结点的键相等,查找命中,否则我们就(递归地)在适当的子树中继续查找。如果被查找的键较小就选择左子树,较大则选择右子树。
/*** 查找 ***/
public Value get(Key key) {
return get(root, key);
}
private Value get(Node x, Key key) {
//在以x为根节点的子树中查找并返回key所对应的值
//如果找不到则返回null
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
return get(x.left, key);
} else if (cmp > 0) {
return get(x.right, key);
} else {
return x.val;
}
}
插入
二叉查找树插入的实现难度和查找差不多。如果树是空的,就返回一个含有该键值对的新结点;如果被查找的键小于根结点的键,继续在左子树中搜索插入该键,否则在右子树中插入该键。
/*** 插入 ***/
public void put(Key key, Value val) {
//查找key,找到则更新它的值,否则为它创建一个新的结点
root = put(root, key, val);
}
private Node put(Node x, Key key, Value val) {
//如果key存在于以x为根结点的子树中则更新它的值;
//否则将以key和val为键值对的新结点插入到该子树中
if (x == null) {
return new Node(key, val, 1);
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
x.left = put(x.left, key, val);
} else if (cmp > 0) {
x.right = put(x.right, key, val);
} else {
x.val = val;
}
x.N = size(x.left) + size(x.right) + 1;
return x;
}
有序性相关的方法
二叉查找树得以广泛应用的一个重要原因就是它能够保持键的有序性,因此它可以作为实现有序符号表API中的众多方法的基础。这使得符号表的用例不仅能够通过键还能通过键的相对顺序来访问键值对。
最小键和最大键
如果根节点的左链接为空,那么一棵二叉查找树中最小的键就是根结点;如果左链接非空,那么树中的最小键就是左子树中的最小键,显示可以由递归操作实现。
找出最大键的方法也是类似的,只不过是变为查找右子树而已。
最小键
/*** 最小键 ***/
public Key min() {
if (root == null) {
return null;
}
return min(root).key;
}
private Node min(Node x) {
if (x.left == null) {
return x;
}
return min(x.left);
}
最大键
/*** 最大键 ***/
public Key max() {
if (root == null) {
return null;
}
return max(root).key;
}
private Node max(Node x) {
if (x.right == null) {
return x;
}
return max(x.right);
}
向上取整和向下取整
如果给定的键key小于二叉查找树的根结点的键,那么小于等于key的最大键floor(key)一定在根结点的左子树中;如果给定的键key大于二叉查找树的根结点,那么只有当根结点右子树中存在小于等于key的结点时,小于等于key的最大键才会出现在右子树中,否则根结点就是小于等于key的最大键。这段描述说明了floor()方法的递归实现,同时也递推地证明了它能够计算出预期的结果。将“左”变为“右”(同时将小于变为大于)就能够得到ceiling()的算法。
向下取整
/*** 向下取整 ***/
public Key floor(Key key) {
Node x = floor(root, key);
if (x == null) {
return null;
}
return x.key;
}
private Node floor(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp == 0) {
return x;
}
if (cmp < 0) {
return floor(x.left, key);
}
Node t = floor(x.right, key);
if (t != null) {
return t;
} else {
return x;
}
}
向上取整
/**** 向上取整 **/
public Key ceiling(Key key) {
Node x = ceiling(root, key);
if (x == null) {
return null;
}
return x.key;
}
private Node ceiling(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp == 0) {
return x;
}
if (cmp > 0) {
return ceiling(x.right, key);
}
Node t = ceiling(x.left, key);
if (t != null) {
return t;
} else {
return x;
}
}
选择操作
/*** 选择操作(返回排名为k的键) ***/
public Key select(int k) {
if (root == null) {
return null;
}
return select(root, k).key;
}
private Node select(Node x, int k) {
//返回排名为k结点
if (x == null) {
return null;
}
//注:书中此处为int t = size(x.left);
//个人觉得此处应该加上当前结点,即+1(若有建议欢迎指正)
int t = size(x.left) + 1;
if (t > k) {
return select(x.left, k);
} else if (t < k) {
return select(x.right, k - t - 1);
} else {
return x;
}
}
二叉查找树的选择操作和基于切分的数组选择操作类似。我们在二叉查找树中的每个结点中维护的子树结点计数器变量N就是用来支持此操作的。
排名
/*** 返回给定键key的排名 ***/
public int rank(Key key) {
if (root == null) {
return 0;
}
return rank(root, key);
}
private int rank(Node x, Key key) {
//返回以x为根结点的子树中小于x.key的键的数量
if (x == null) {
return 0;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
return rank(x.left, key);
} else if (cmp > 0) {
return 1 + size(x.left) + rank(x.right, key);
} else {
//若返回给定键的排名,我认为这里要+1,不然可以在上面调用后的return语句后+1
//书中此处为return size(x.left)(若有建议欢迎指正);
return size(x.left) + 1;
}
}
rank()方法是select()方法的逆方法,它会返回给定键的排名。它的实现和select()类似:如果给定的键和根结点的键相等,我们返回左子树中的结点总数t;如果给定的键小于根结点,我们会返回该键在左子树中的排名(递归计算);如果给定的键大于根结点,我们会返回t+1(根结点)加上它在右子树中的排名(递归计算)。
范围查找
/*** 范围查找(返回给定范围内的所有键值) ***/
public Iterable<Key> keys() {
return keys(min(), max());
}
public Iterable<Key> keys(Key lo, Key hi) {
Queue<Key> queue = new LinkedList<Key>();
keys(root, queue, lo, hi);
return queue;
}
private void keys(Node x, Queue<Key> queue, Key lo, Key hi) {
if (x == null) {
return;
}
int cmplo = lo.compareTo(x.key);
int cmphi = hi.compareTo(x.key);
if (cmplo < 0) {
keys(x.left, queue, lo, hi);
}
if (cmplo <= 0 && cmphi >= 0) {
queue.offer(x.key);
}
if (cmphi > 0) {
keys(x.right, queue, lo, hi);
}
}
要实现能够返回给定范围键的keys()方法,我们首先需要一个遍历二叉查找树的基本方法,为中序遍历。要说明这个方法,我们先看看如何能够将二叉查找树中的所有键按照顺序打印出来。要做到这一点,我们应该先打印出根结点的 左子树中的所有键(根据二叉查找树的定义它们应该都小于根结点的键),然后打印出根结点的键,最后打印出根结点的右子树中的所有键(根据二叉查找树的定义它们应该都大于根结点的键)。
与删除相关的方法
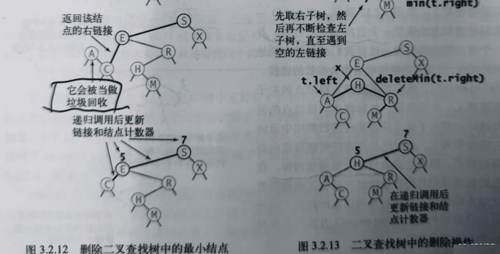
删除最小键
二叉查找树中最难实现的方法就是delete()方法,即从符号表中删除一个键值对。在此之前,我们先考虑deleteMin()方法(删除最小键所对应的键值对)。对于deleteMin(),我们要不断深入根节点的左子树直至遇见一个空链接,然后将指向该结点的右子树(只需要在递归调用中返回它的右链接即可)。此时它会被垃圾收集器清理掉。我们给出的标准递归代码在删除结点后会正确地设置它的父结点的链接并更新它到根结点的路径上的所有结点的计数器的值。
/*** 删除最小键 ***/
public void deleteMin() {
if (root == null) {
return;
}
deleteMin(root);
}
private Node deleteMin(Node x) {
if (x.left == null) {
return x.right;
}
x.left = deleteMin(x.left);
x.N = size(x.left) + size(x.right) + 1;
return x;
}
删除最大键
deletemax()方法的实现和deletemin()完全类似,相应地,只需删除右子树最右端结点,然后返回其最右端结点的左子树即可。
/*** 删除最大键 ***/
public void deleteMax() {
if (root == null) {
return;
}
deleteMax(root);
}
private Node deleteMax(Node x) {
if (x.right == null) {
return x.left;
}
x.right = deleteMax(x.right);
x.N = size(x.left) + size(x.right) + 1;
return x;
}
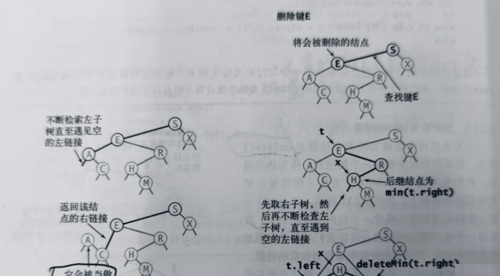
删除操作
- 将指向即将被删除的结点的链接保存为t;
- 将x指向它的后继结点min(t.right);
- 将x的右链接(原本指向一棵所有结点都大于x.key的二叉查找树)指向deleteMin(t.right),也就是在删除后所有结点仍然都大于x.key的子二叉查找树;
- 将x的左链接(本为空)设为t.left(其下所有的键都小于被删除的结点和它的后继结点)。
实现:
/*** 删除操作 ***/
public void delete (Key key) {
root = delete(root, key);
}
private Node delete(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
x.left = delete(x.left, key);
} else if(cmp > 0) {
x.right = delete(x.right, key);
} else {
if (x.right == null) {
return x.left;
}
if (x.left == null) {
return x.right;
}
Node t = x;
x = min(t.right);
x.right = deleteMin(t.right);
x.left = t.left;
}
x.N = size(x.left) + size(x.right) + 1;
return x;
}
性能分析
我见过二叉查找树,但它的实现没有使用递归。这两种方式各有哪些优缺点?
答:一般来说,递归的实现更容易验证其正确性,而非递归的实现效率更高。
完整代码和测试
完整代码
class BST<Key extends Comparable<Key>, Value> {
private Node root; //二叉查找树的根节点
private class Node{
private Key key; //键
private Value val; //值
private Node left, right; //指向子树的链接
private int N; //以该结点为根的子树中的结点总数
public Node(Key key, Value val, int N) {
this.key = key;
this.val = val;
this.N = N;
}
}
public int size() {
return size(root);
}
private int size(Node x) {
if (x == null) {
return 0;
} else {
return x.N;
}
}
/*** 查找 ***/
public Value get(Key key) {
return get(root, key);
}
private Value get(Node x, Key key) {
//在以x为根节点的子树中查找并返回key所对应的值
//如果找不到则返回null
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
return get(x.left, key);
} else if (cmp > 0) {
return get(x.right, key);
} else {
return x.val;
}
}
/*** 插入 ***/
public void put(Key key, Value val) {
//查找key,找到则更新它的值,否则为它创建一个新的结点
root = put(root, key, val);
}
private Node put(Node x, Key key, Value val) {
//如果key存在于以x为根结点的子树中则更新它的值;
//否则将以key和val为键值对的新结点插入到该子树中
if (x == null) {
return new Node(key, val, 1);
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
x.left = put(x.left, key, val);
} else if (cmp > 0) {
x.right = put(x.right, key, val);
} else {
x.val = val;
}
x.N = size(x.left) + size(x.right) + 1;
return x;
}
/*** 最小键 ***/
public Key min() {
if (root == null) {
return null;
}
return min(root).key;
}
private Node min(Node x) {
if (x.left == null) {
return x;
}
return min(x.left);
}
/*** 最大键 ***/
public Key max() {
if (root == null) {
return null;
}
return max(root).key;
}
private Node max(Node x) {
if (x.right == null) {
return x;
}
return max(x.right);
}
/*** 向下取整 ***/
public Key floor(Key key) {
Node x = floor(root, key);
if (x == null) {
return null;
}
return x.key;
}
private Node floor(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp == 0) {
return x;
}
if (cmp < 0) {
return floor(x.left, key);
}
Node t = floor(x.right, key);
if (t != null) {
return t;
} else {
return x;
}
}
/**** 向上取整 **/
public Key ceiling(Key key) {
Node x = ceiling(root, key);
if (x == null) {
return null;
}
return x.key;
}
private Node ceiling(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp == 0) {
return x;
}
if (cmp > 0) {
return ceiling(x.right, key);
}
Node t = ceiling(x.left, key);
if (t != null) {
return t;
} else {
return x;
}
}
/*** 选择操作(返回排名为k的键) ***/
public Key select(int k) {
if (root == null) {
return null;
}
return select(root, k).key;
}
private Node select(Node x, int k) {
//返回排名为k结点
if (x == null) {
return null;
}
int t = size(x.left) + 1;
if (t > k) {
return select(x.left, k);
} else if (t < k) {
return select(x.right, k - t - 1);
} else {
return x;
}
}
/*** 返回给定键key的排名 ***/
public int rank(Key key) {
if (root == null) {
return 0;
}
return rank(root, key);
}
private int rank(Node x, Key key) {
//返回以x为根结点的子树中小于x.key的键的数量
if (x == null) {
return 0;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
return rank(x.left, key);
} else if (cmp > 0) {
return 1 + size(x.left) + rank(x.right, key);
} else {
return size(x.left) + 1;
}
}
/*** 范围查找(返回给定范围内的所有键值) ***/
public Iterable<Key> keys() {
return keys(min(), max());
}
public Iterable<Key> keys(Key lo, Key hi) {
Queue<Key> queue = new LinkedList<Key>();
keys(root, queue, lo, hi);
return queue;
}
private void keys(Node x, Queue<Key> queue, Key lo, Key hi) {
if (x == null) {
return;
}
int cmplo = lo.compareTo(x.key);
int cmphi = hi.compareTo(x.key);
if (cmplo < 0) {
keys(x.left, queue, lo, hi);
}
if (cmplo <= 0 && cmphi >= 0) {
queue.offer(x.key);
}
if (cmphi > 0) {
keys(x.right, queue, lo, hi);
}
}
/*** 删除最小键 ***/
public void deleteMin() {
if (root == null) {
return;
}
deleteMin(root);
}
private Node deleteMin(Node x) {
if (x.left == null) {
return x.right;
}
x.left = deleteMin(x.left);
x.N = size(x.left) + size(x.right) + 1;
return x;
}
/*** 删除最大键 ***/
public void deleteMax() {
if (root == null) {
return;
}
deleteMax(root);
}
private Node deleteMax(Node x) {
if (x.right == null) {
return x.left;
}
x.right = deleteMax(x.right);
x.N = size(x.left) + size(x.right) + 1;
return x;
}
/*** 删除操作 ***/
public void delete (Key key) {
root = delete(root, key);
}
private Node delete(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
x.left = delete(x.left, key);
} else if(cmp > 0) {
x.right = delete(x.right, key);
} else {
if (x.right == null) {
return x.left;
}
if (x.left == null) {
return x.right;
}
Node t = x;
x = min(t.right);
x.right = deleteMin(t.right);
x.left = t.left;
}
x.N = size(x.left) + size(x.right) + 1;
return x;
}
}
测试
int[] keys = {6, 5, 1, 3, 2, 4, 9, 7, 8, 10};
String[] values = {"F", "E", "A", "C", "B", "D", "I", "G", "H", "J"};

public class BSTTest {
public static void main(String[] args) {
int[] keys = {6, 5, 1, 3, 2, 4, 9, 7, 8, 10};
String[] values = {"F", "E", "A", "C", "B", "D", "I", "G", "H", "J"};
BST<Integer, String> bst = new BST<Integer, String>();
//构建树
for (int i = 0; i < keys.length; i++) {
bst.put(keys[i], values[i]);
}
System.out.println("创建树的键为:");
LinkedList<Integer> queue = (LinkedList<Integer>) bst.keys();
while (!queue.isEmpty()) {
System.out.print(queue.poll() + " ");
}
System.out.println("\n创建树的大小为:" + bst.size());
System.out.println("键3所对应的值为:" + bst.get(3));
System.out.println("最小键为:" + bst.min());
System.out.println("最大键为: " + bst.max());
System.out.println("小于等于11的最大键是:" + bst.floor(11));
System.out.println("大于等于0的最小键是: " + bst.ceiling(0));
System.out.println("排名为5的键是:" + bst.select(5));
System.out.println("键7的排名是:" + bst.rank(7));
System.out.println("\n键值在3-8之间的键有:");
LinkedList<Integer> queue1 = (LinkedList<Integer>) bst.keys(3, 8);
while (!queue1.isEmpty()) {
System.out.print(queue1.poll() + " ");
}
System.out.println("\n删除最小键和最大键后的键值为:");
bst.deleteMin();
bst.deleteMax();
LinkedList<Integer> queue2 = (LinkedList<Integer>) bst.keys();
while (!queue2.isEmpty()) {
System.out.print(queue2.poll() + " ");
}
System.out.println("\n删除键4后的键值为: ");
bst.delete(4);
LinkedList<Integer> queue3 = (LinkedList<Integer>) bst.keys();
while (!queue3.isEmpty()) {
System.out.print(queue3.poll() + " ");
}
}
}
创建树的键为:
1 2 3 4 5 6 7 8 9 10
创建树的大小为:10
键3所对应的值为:C
最小键为:1
最大键为: 10
小于等于11的最大键是:10
大于等于0的最小键是: 1
排名为5的键是:5
键7的排名是:7
键值在3-8之间的键有:
3 4 5 6 7 8
删除最小键和最大键后的键值为:
2 3 4 5 6 7 8 9
删除键4后的键值为:
2 3 5 6 7 8 9
Process finished with exit code 0
到此这篇关于C++高级数据结构之二叉查找树的文章就介绍到这了,更多相关C++二叉查找树内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
c++实现二叉查找树示例
复制代码 代码如下: /** 实现二叉查找树的基本功能*/ #include <iostream>#include <cstring>#include <algorithm>#include <cstdio>#include <string> using namespace std; const int M = 10000; //定义数据节点class dNode{public: string name; int age; bool sex; d
-

C++高级数据结构之二叉查找树
目录 高级数据结构(Ⅳ)二叉查找树 基础概念 基本实现 数据表示 查找 插入 有序性相关的方法 最小键和最大键 向上取整和向下取整 选择操作 排名 范围查找 与删除相关的方法 删除最小键 删除最大键 删除操作 性能分析 完整代码和测试 完整代码 测试 前言: 文章目录 基础概念 基本实现 有序性相关的方法 与删除相关的方法 性能分析 完整代码和测试 高级数据结构(Ⅳ)二叉查找树 基础概念 此数据结构由结点组成,结点包含的链接可以为空(null)或者指向其他结点.在二叉树中,每个结点只能有一个父结
-
JavaScript数据结构之二叉查找树的定义与表示方法
本文实例讲述了JavaScript数据结构之二叉查找树的定义与表示方法.分享给大家供大家参考,具体如下: 树是一种非线性的数据结构,以分层的方式存储数据.树被用来存储具有层级关系的数据,比如文件系统中的文件:树还被用来存储有序列表.这里将研究一种特殊的树:二叉树.选择树而不是那些基本的数据结构,是因为在二叉树上进行查找非常快(而在链表上查找则不是这样),为二叉树添加或删除元素也非常快(而对数组执行添加或删除操作则不是这样). 树是n个结点的有限集.最上面的为根,下面为根的子树.树的节点包含一个数
-
Python中的高级数据结构详解
数据结构 数据结构的概念很好理解,就是用来将数据组织在一起的结构.换句话说,数据结构是用来存储一系列关联数据的东西.在Python中有四种内建的数据结构,分别是List.Tuple.Dictionary以及Set.大部分的应用程序不需要其他类型的数据结构,但若是真需要也有很多高级数据结构可供选择,例如Collection.Array.Heapq.Bisect.Weakref.Copy以及Pprint.本文将介绍这些数据结构的用法,看看它们是如何帮助我们的应用程序的. 关于四种内建数据结构的使用方
-
JS中的算法与数据结构之二叉查找树(Binary Sort Tree)实例详解
本文实例讲述了JS中的算法与数据结构之二叉查找树(Binary Sort Tree).分享给大家供大家参考,具体如下: 二叉查找树(Binary Sort Tree) 我们之前所学到的列表,栈等都是一种线性的数据结构,今天我们将学习计算机中经常用到的一种非线性的数据结构--树(Tree),由于其存储的所有元素之间具有明显的层次特性,因此常被用来存储具有层级关系的数据,比如文件系统中的文件:也会被用来存储有序列表等. 在树结构中,每一个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的
-
Java数据结构之二叉查找树的实现
目录 定义 节点结构 查找算法 插入算法 删除算法 完整代码 定义 二叉查找树(亦称二叉搜索树.二叉排序树)是一棵二叉树,且各结点关键词互异,其中根序列按其关键词递增排列. 等价描述:二叉查找树中任一结点 P,其左子树中结点的关键词都小于 P 的关键词,右子树中结点的关键词都大于 P 的关键词,且结点 P 的左右子树也都是二叉查找树 节点结构 :one: key:关键字的值 :two: value:关键字的存储信息 :three: left:左节点的引用 :four: right:右节点的引用
-
C++高级数据结构之优先队列
目录 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 实现 堆的定义 二叉堆表示法 堆的算法 插入元素 删除最大元素 基于堆的优先队列 堆排序 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 堆的定义 二叉堆表示法 堆的算法 基于堆的优先队列 堆排序 高级数据结构(Ⅱ)优先队列(Priority Queue) 许多应用程序都需要处理有序的元素,但不一定要求它们全部有序,或是不一定要一次就将它们排序.很多情况下我们会收集一些元素,处理当前键值最大
-
C++高级数据结构之并查集
目录 1.动态连通性 2.union-find算法API 3.quick-find算法 4.quick-union算法 5.加权quick-union算法 6.使用路径压缩的加权quick-union算法 7.算法比较 前言: 高级数据结构(Ⅰ)并查集(union-find) 动态连通性 union-find算法API quick-find算法 quick-union算法 加权quick-union算法 使用路径压缩的加权quick-union算法 算法比较 并查集 > 左神版 高级数据结构(Ⅰ
-
C++高级数据结构之线段树
目录 前言: 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 树的创建 单点修改 区间查找 完整代码及测试 前言: 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 树的创建 单点修改 区间查找 完整代码及测试 高级数据结构(Ⅲ)线段树(Segment Tree) 线段树的原理 线段树是一种二叉搜索树 , 对于线段树中的每一个非叶子结点[a,b],它的左儿子表示的区间为[a, (a+b)/2],右儿子表示的区间为[(a+b)/2+1, b].因此线段树是平衡
-
高级数据结构及应用之使用bitmap进行字符串去重的方法实例
bitmap 即为由单个元素为 boolean(0/1, 0 表示未出现,1 表示已经出现过)的数组. 如果C/C++ 没有原生的 boolean 类型,可以用 int 或 char 来作为 bitmap 使用,如果我们要判断某字符(char)是否出现过 使用 int 作为 bitmap 的底层数据结构,bitmap 即为 int 数组,一个 int 长度为 32 个 bit 位, c / 32 ⇒ bitmap 中的第几个 int c % 32 ⇒ bitmap 中的某 int 中的第几个 b
-
Python数据结构之哈夫曼树定义与使用方法示例
本文实例讲述了Python数据结构之哈夫曼树定义与使用方法.分享给大家供大家参考,具体如下: HaffMan.py #coding=utf-8 #考虑权值的haff曼树查找效率并非最高,但可以用于编码等使用场景下 class TreeNode: def __init__(self,data): self.data=data self.left=None self.right=None self.parent=None class HaffTree: def __init__(self): sel