解析JavaScript中 querySelector 与 getElementById 方法的区别
目录
- 1. 概述
- 1.1 querySelector() 和 querySelectorAll() 的用法
- 1.2 getElement(s)Byxxxx 的用法
- 2. 区别
- 2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合
- 2.2 接收的参数不同
- 2.3 浏览器兼容不同
- 2.4 querySelector 属于 W3C 中的 Selectors API 规范 ,而 getElementsBy 系列属于 W3C 的 DOM 规范
1. 概述
在看代码的时候发现基本上都是用 querySelector() 和 querySelectorAll() 来获取元素,疑惑为什么不用 getElementById()。
可能因为自己没用过那两个,所以并不清楚原因所在。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义: querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素;
注意: querySelector() 方法仅返回匹配指定选择器的第一个元素。如果你需要返回所有的元素,请用 querySelectorAll() 方法替代;
语法: document.querySelector(CSS selectors);
参数值: String 必须。指定一个或多个匹配元素的 CSS 选择器。使用它们的 id, 类, 类型, 属性, 属性值等来选取元素。
对于多个选择器,使用逗号隔开,返回一个匹配的元素。
返回值: 匹配指定 CSS 选择器的第一个元素。 如果没有找到,返回 null。如果指定了非法选择器则 抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义: querySelectorAll() 方法返回文档中匹配指定 CSS 选择器的所有元素,返回 NodeList 对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从 0 开始;
提示: 可使用 NodeList 对象的 length 属性来获取匹配选择器的元素属性,然后遍历所有元素,从而获取想要的信息;
语法: elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型的对象;
selectors 是一个由逗号连接的包含一个或多个 CSS 选择器的字符串;
参数值: String 必须。指定一个或多个匹配 CSS 选择器的元素。可以通过 id, class, 类型, 属性, 属性值等作为选择器来获取元素。
多个选择器使用逗号(,)分隔。
返回值: 一个 NodeList 对象,表示文档中匹配指定 CSS 选择器的所有元素。
NodeList 是一个静态的 NodeList 类型的对象。如果指定的选择器不合法,则抛出一个 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx 的用法
getElementById() 方法
定义: getElementById() 方法可返回对拥有指定 ID 的第一个对象的引用。
如果没有指定 ID 的元素返回 null;
如果存在多个指定 ID 的元素则返回第一个;
如果需要查找到那些没有 ID 的元素,你可以考虑通过CSS选择器使用 querySelector();
语法: document.getElementById(elementID);
参数值: String 必须。元素ID属性值。
返回值: 元素对象 指定ID的元素
getElementsByTagName() 方法
定义: getElementsByTagName() 方法可返回带有指定标签名的对象的集合;
提示: 参数值 "*" 返回文档的所有元素;
语法: document.getElementsByTagName(tagname)
参数: String 必须 要获取元素的标签名;
返回值: NodeList 对象 指定标签名的元素集合
getElementsByClassName() 方法
定义: getElementsByClassName() 方法返回文档中所有指定类名的元素集合,作为 NodeList 对象。
NodeList 对象代表一个有顺序的节点列表。NodeList 对象 可通过节点列表中的节点索引号来访问表中的节点(索引号由0开始)。
提示: 可使用 NodeList 对象的 length 属性来确定指定类名的元素个数,并循环各个元素来获取需要的那个元素。
语法: document.getElementsByClassName(classname)
参数: String 必须 需要获取的元素类名。 多个类名使用空格分隔,如 "test demo";
返回值: NodeList 对象,表示指定类名的元素集合。元素在集合中的顺序以其在代码中的出现次序排序。
2. 区别
2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合
动态就是选出的元素会随文档改变,静态的不会 取出来之后就和文档的改变无关了。
示例1:
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
</script>
上述代码会陷入死循环,i < list.length 这个循环条件。
因为在第一次获取到里面的 3 个 li 后,每当往 ul 里添加了新元素后,list便会更新其值,重新获取ul里的所有li。
也就是 getElement(s)Byxxxx 获取的是动态集合,它总会随着 dom 结构的变化而变化。
也就是每一次调用 list 都会重新对文档进行查询,导致无限循环的问题。
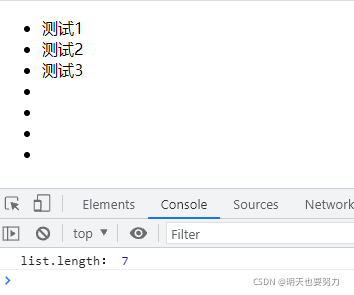
示例1 修改:
将 for 循环条件修改为 i < 4,结果 在 ul 里新添加了4个元素,所有现在插入的 li 标签数量是7。
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);
</script>
示例2:
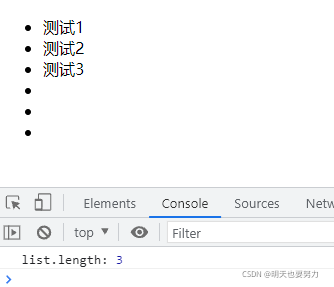
下述代码静态集合体现在 .querySelectorAll(‘li') 获取到 ul 里所有 li 后,不管后续再动态添加了多少 li,都是不会对其参数影响。
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6
</script>
为什么要这样设计呢?
在 W3C 规范中对 querySelectorAll 方法有明确规定:
The NodeList object returned by the querySelectorAll() method must be static ([DOM], section 8).
我们再看看在 Chrome 上面是个什么样的情况:
document.querySelectorAll('a').toString(); // return "[object NodeList]"
document.getElementsByTagName('a').toString(); // return "[object HTMLCollection]"
HTMLCollection 在 W3C 的定义如下:
An HTMLCollection is a list of nodes. An individual node may be accessed by either ordinal index or the node's name or id attributes.Note: Collections in the HTML DOM are assumed to be live meaning that they are automatically updated when the underlying document is changed.
实际上,HTMLCollection 和 NodeList 十分相似,都是一个动态的元素集合,每次访问都需要重新对文档进行查询。
区别:HTMLCollection 属于 Document Object Model HTML 规范,而 NodeList 属于 Document Object Model Core 规范。
这样说有点难理解,看看下面的例子会比较好理解:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象会包含文档中的所有节点,如 Element、Text 和 Comment 等;
HTMLCollection 对象只会包含文档中的 Element 节点;
另外,HTMLCollection 对象比 NodeList 对象 多提供了一个 namedItem 方法;
因此在浏览器中,querySelectorAll 的返回值是一个静态的 NodeList 对象,而 getElementsBy 系列的返回值实际上是一个 HTMLCollection 对象 。
2.2 接收的参数不同
querySelectorAll 方法接收的参数是一个 CSS 选择符;
getElementsBy 系列接收的参数只能是单一的 className、tagName 和 name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll 所接收的参数是必须严格符合 CSS 选择符规范的
下面这种写法,将会抛出异常(CSS 选择器中的元素名,类和 ID 均不能以数字为开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持 ;
getElementsBy 系列,以最迟添加规范中的 getElementsByClassName 为例,IE 9+、FF 3 +、Safari 3.1+、Chrome 和 Opera 9+ 都已经支持;
2.4 querySelector 属于 W3C 中的 Selectors API 规范 ,而 getElementsBy 系列属于 W3C 的 DOM 规范
参考文章(侵删)
到此这篇关于JavaScript中 querySelector 与 getElementById 方法的区别的文章就介绍到这了,更多相关js中 querySelector 与 getElementById 方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
javascript typeof id==='string'?document.getElementById(id):id解释 原创
一般来说想要理解这段代码,需要掌握如下两个函数 一个是 typeof一个就是三元运算符 看完了上面的文章再看下面的就比较好理解了 一般来说常用的函数代码 function $(id){ return typeof id==='string'?document.getElementById(id):id;} var GetBy = function (id) { return "string" == typeof id ? document.getElementById(id) : id
-
getElementByIdx_x js自定义getElementById函数
函数代码: 复制代码 代码如下: document.getElementByIdx_x=function(id){ if(typeof id =='string') return document.getElementById(id); else throw new error('please pass a string as a id!') } 实例代码: 复制代码 代码如下: <div id='box'>9</div> <script> document.getEl
-
javascript之querySelector和querySelectorAll使用介绍
一开始很多人都会拿jquery的选择器来跟这两个api做对比(我也是),比较异同本来没事,但却使一些同学对这两个api在浏览器中的实现产生了误解,特别是再dom element上调用此api时. 下面是我的jsFiddle示例,我就以此展开说明: js代码: (function(global) { global.doc = document; global.body = doc.getElementsByTagName('body')[0]; global.$ = function(id) {
-
javascript getElementById 使用方法及用法
document.getElementById("link").href; document.getElementById("link").target; document.getElementById("img").src; document.getElementById("img").width; document.getElementById("img").height; document.getEl
-
js querySelector和getElementById通过id获取元素的区别
这是sina同事xiaoniu发现的,如下 <!DOCTYPE html> <html> <head> <meta charset="utf-8"/> </head> <body> <div id="02E503E2A1C011CFC85B7B701A0677EC0900000000000001"></div> <script> var str = '02E5
-

js querySelector() 使用方法
querySelector 定义和用法 querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素. 注意: querySelector() 方法仅仅返回匹配指定选择器的第一个元素.如果你需要返回所有的元素,请使用 querySelectorAll() 方法替代. 浏览器支持 表格中的数字表示支持该方法的第一个浏览器的版本号. 语法 document.querySelector(CSS selectors) 参数值 参数 类型 描述 CSS 选择器 String 必须.指定
-
原生js操作checkbox用document.getElementById实现
jquery与checkbox的checked属性的问题,讲的是控件<input type="checkbox"></input> 1.页面加载成功后,点击选中或取消选中该checkbox,checkbox属性里的checked属性不会根据该checkbox是否选中而变化 2.checkbox里的onchange或onclick方法里用jquery的attr方法获取checked是看得到的checked属性的值与它是否给钩上没有关系 3.使用document.g
-
JS中 querySelector 与 getElementById 方法区别
目录 1. 概述 1.1 querySelector() 和 querySelectorAll() 的用法 1.2 getElement(s)Byxxxx 的用法 2. 区别 2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合 2.2 接收的参数不同 2.3 浏览器兼容不同 1. 概述 在看代码的时候发现基本上都是用 querySelector() 和 querySelectorAll() 来获取元素,疑惑为什么不用 getElemen
-
解析JavaScript中 querySelector 与 getElementById 方法的区别
目录 1. 概述 1.1 querySelector() 和 querySelectorAll() 的用法 1.2 getElement(s)Byxxxx 的用法 2. 区别 2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合 2.2 接收的参数不同 2.3 浏览器兼容不同 2.4 querySelector 属于 W3C 中的 Selectors API 规范 ,而 getElementsBy 系列属于 W3C 的 DOM 规范 1.
-
JavaScript中递归实现的方法及其区别
递归函数:递归函数是在通过名字调用自身的情况下构成的. 递归实现阶乘函数: 方法一:通过使用函数的名字 function factorial(num){ if(num<=1){ return 1; }else{ return num*factorial(num-1); } } console.log(factorial(4)); 结果为:24: 但是这种方法实现递归有一个问题,观察以下代码: function factorial(num){ if(num<=1){ return 1; }els
-
深入理解关于javascript中apply()和call()方法的区别
如果没接触过动态语言,以编译型语言的思维方式去理解javaScript将会有种神奇而怪异的感觉,因为意识上往往不可能的事偏偏就发生了,甚至觉得不可理喻.如果在学JavaScript这自由而变幻无穷的语言过程中遇到这种感觉,那么就从现在形始,请放下的您的"偏见",因为这对您来说绝对是一片新大陆,让JavaScrip慢慢融化以前一套凝固的编程意识,注入新的生机! 好,言归正传,先理解JavaScrtipt动态变换运行时上下文特性,这种特性主要就体现在apply, call两个方法的运用上.
-
JavaScript中call和apply方法的区别实例分析
本文实例分析了JavaScript中call和apply方法的区别.分享给大家供大家参考,具体如下: 这两个方法不经常用,但是在某些特殊场合中是非常有用的,下面主要说下它们的区别: 1.首先,JavaScript是一门面向对象的语言,也就是说它有this的概念.而且JavaScript是一门动态类型语言,为什么说它是动态类型语言呢?因为JavaScript在编译时没有类型检查的过程,不会去检查创建的对象类型,也不会去检查传递的参数类型,所以它的变量类型在运行期间是可以改变的. 2.要知道call
-
JavaScript中find()和 filter()方法的区别小结
目录 前言 JavaScript find() 方法 JavaScript filter() 方法 find() 和 filter() 的区别与共点 直接上代码 总结 前言 JavaScript 在 ES6 上有很多数组方法,每种方法都有独特的用途和好处. 在开发应用程序时,大多使用数组方法来获取特定的值列表并获取单个或多个匹配项. 在列出这两种方法的区别之前,我们先来一一了解这些方法. JavaScript find() 方法 ES6 find() 方法返回通过测试函数的第一个元素的值.如果没
-
关于JavaScript中事件绑定的方法总结
最近收集了一些关于JavaScript绑定事件的方法,汇总了一下,不全面,但是,希望便于以后自己查看. JavaScript中绑定事件的方法主要有三种: 1 在DOM元素中直接绑定 2 JavaScript代码中直接绑定 3 绑定事件监听函数 一.在DOM元素中直接绑定 也就是直接在html标签中通过 onXXX="" 来绑定.举个例子: <input type="button" value="点我呦" onclick="aler
-
JavaScript中输出信息的方法(信息确认框-提示输入框-文档流输出)
js中输出信息的方法内容如下所示: 1.文档流输出 document.write('hello'); 2.输出信息提示框 模态对话框 window.alert('要输出显示的内容'); 或 alert('要输出显示的内容'); alert(n); 3.信息确认框 var f = window.confirm('是否要进入新浪网'); confirm(""); if(f){ location.href = 'http://www.sina.com.cn'; } 4.提示输入框 windo
-
JavaScript中Object.prototype.toString方法的原理
在JavaScript中,想要判断某个对象值属于哪种内置类型,最靠谱的做法就是通过Object.prototype.toString方法. var arr = []; console.log(Object.prototype.toString.call(arr)) //"[object Array]" 本文要讲的就是,toString方法是如何做到这一点的,原理是什么. ECMAScript 3 在ES3中,Object.prototype.toString方法的规范如下: 15.2.
-
JavaScript中setter和getter方法介绍
javascript中的setter.getter是平时接触比较少的方法,其本身也并不是标准方法,只在非ie浏览器里支持(ie内核也许有其他方法可以做到呢?暂时不知其解),但是加以利用可以做许多事情,比如: 1.对数据的访问限制: a.value是对value变量的getter方法调用,如果在getter方法实现中抛出异常,可以阻止对value变量的访问 2.对dom变量进行监听: window.name是一个跨域非常好用的dom属性(大名鼎鼎,详见百度),如果覆盖window.name的set