Java读取PDF中的表格的方法示例
目录
- 一、概述
- 二、环境配置
- 1. 手动导入
- 2. Maven仓库下载导入
- 三、读取PDF中的表格
一、概述
本文以Java示例展示读取PDF中的表格的方法。这里导入Spire.PDF for Javah中的jar包,并使用其提供的相关及方法来实现获取表格中的文本内容。下表中整理了本次代码使用到的主要类、方法及解释,供参考:
| 类型 | 描述 |
| PdfDocument Class | Represents a pdf document model. |
| PdfDocument. loadFromFile (string filename) Method | Loads a PDF document. |
| PdfTableExtractor Class | Represents the PDF table extractor. |
| PdfTable Class | Defines a PDF table. |
| PdfTableExtractor. extractTable (int pageIndex) Method | Extracts table from page. |
| PdfTable.getText(int rowIndex,int columnIndex) Method | Gets Text in cell. |
| FileWriter. write() Method | Saves extracted text in table to a .txt file. |
二、环境配置
- IntelliJ IDEA 2018(JDK 1.8.0)
- PDF 测试文档
- PDF Jar包:Spire.PDF for Java Version: 4.10.2
Jar包的两种导入方法:
1. 手动导入
将jar包下载到本地,解压。然后执行如下步骤来手动导入:
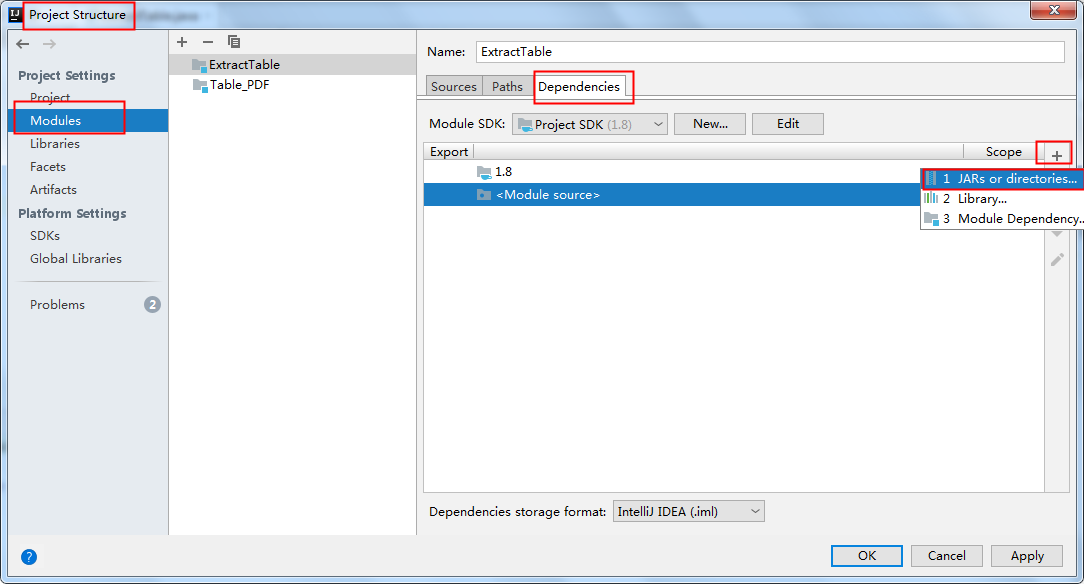
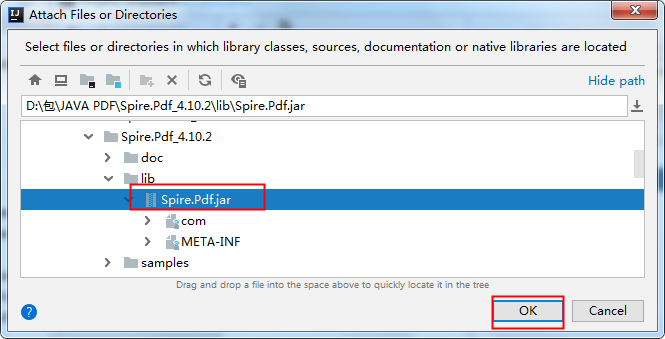
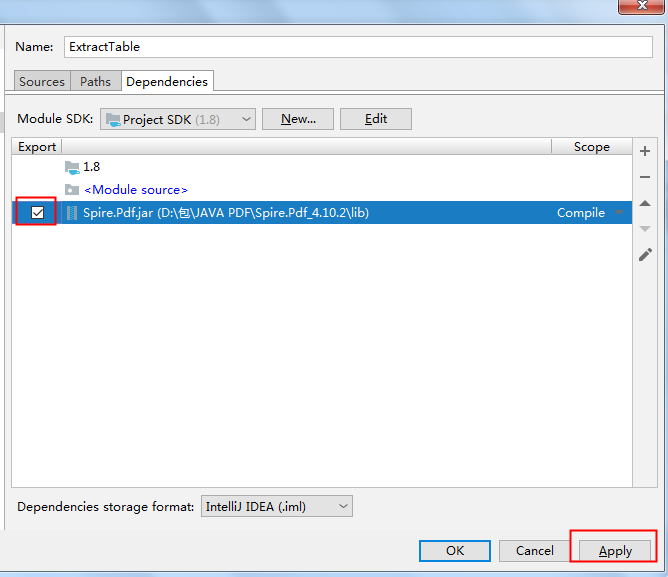
2. Maven仓库下载导入
如果使用maven,需在pom.xml中配置maven路径,指定依赖,如下:
<repositories>
<repository>
<id>com.e-iceblue</id>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>4.10.2</version>
</dependency>
</dependencies>
三、读取PDF中的表格
import com.spire.pdf.*;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTable {
public static void main(String[] args)throws IOException {
//加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//抽取表格
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists ;
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
for (PdfTable table : tableLists)
{
int row = table.getRowCount();
int column = table.getColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
String text = table.getText(i, j);
builder.append(text+" ");
}
builder.append("\r\n");
}
}
}
}
//将提取的表格内容写入txt文档
FileWriter fileWriter = new FileWriter("ExtractedTable.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
表格内容读取结果:
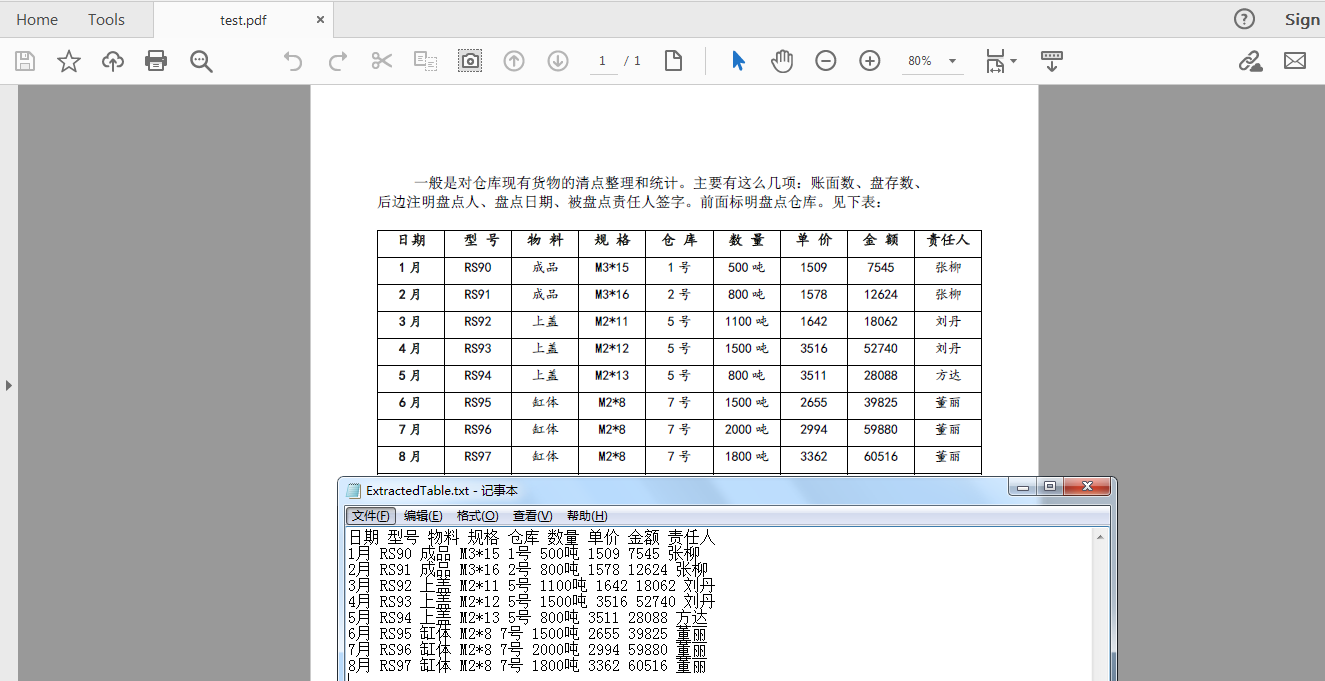
注意事项:
1. 注意使用的PDF Jar包版本为4.10.2,低于此版本的jar包不支持读取表格;
2. 代码中的文件路径为 F:\IDEAProject\Table_PDF\test.pdf 和 F:\IDEAProject\Table_PDF\ExtractedTable.txt , 文件路径可自定义为其他路径。
到此这篇关于Java读取PDF中的表格的方法示例的文章就介绍到这了,更多相关Java读取PDF表格内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java 读取PDF中的文本和图片的方法
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Java(免费版) Jar文件获取导入: 方法1:通过官网下载jar文件包.下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入java程序.导入后如下图: 方法2: 可通过maven仓库安装导入. Java代码示例 import com.spire.pdf.*; import java
-
JAVA读取PDF、WORD文档实例代码
读取PDF文件jar引用 <dependency> <groupid>org.apache.pdfbox</groupid> pdfbox</artifactid> <version>1.8.13</version> </dependency> 读取WORD文件jar引用 <dependency> <groupid>org.apache.poi</groupid> poi-scratch
-

Java读取PDF中的表格的方法示例
目录 一.概述 二.环境配置 1. 手动导入 2. Maven仓库下载导入 三.读取PDF中的表格 一.概述 本文以Java示例展示读取PDF中的表格的方法.这里导入Spire.PDF for Javah中的jar包,并使用其提供的相关及方法来实现获取表格中的文本内容.下表中整理了本次代码使用到的主要类.方法及解释,供参考: 类型 描述 PdfDocument Class Represents a pdf document model. PdfDocument. loadFromFile (s
-
java在pdf中生成表格的方法
1.目标 在pdf中生成一个可变表头的表格,并向其中填充数据.通过泛型动态的生成表头,通过反射动态获取实体类(我这里是User)的get方法动态获得数据,从而达到动态生成表格. 每天生成一个文件夹存储生成的pdf文件(文件夹的命名是年月日时间戳),如:20151110 生成的文件可能在毫秒级别,故文件的命名规则是"到毫秒的时间戳-uuid",如:20151110100245690-ece540e5-7737-4ab7-b2d6-87bc23917c8c.pdf 通过读取properti
-
C#实现从PDF中提取表格的方法详解
目录 程序环境 从PDF中提取表格具体步骤 完整代码 PDF是办公中比较常见的一种文件格式,在工作中应用也越来越普遍.由于PDF文件集成度和安全可靠性都较高,所以在PDF中编辑内容是一件比较复杂且困难的事.但有时因工作需要,要求我们从中提取数据或表格该怎么办呢?别担心,今天为大家介绍一种通过C#/VB.NET代码从PDF中提取表格内容的方法.下面是我整理的思路步骤及代码供大家参考. 程序环境 本次测试时,在程序中引入 Spire.PDF.dll 文件. 方法1: 将 Free Spire.
-
Java在PDF中添加表格过程详解
前言 本文将介绍通过Java编程在PDF文档中添加表格的方法.添加表格时,可设置表格边框.单元格对齐方式.单元格背景色.单元格合并.插入图片.设置行高.列宽.字体.字号等. 使用工具:Free Spire.PDF for Java (免费版) Jar文件获取及导入: 方法1:通过官网下载jar文件包.下载后,解压文件,将lib文件夹下的Spire.Pdf.jar文件导入Java程序. 方法2:通过maven仓库安装导入. Java 代码示例 Java代码 import com.spire.pdf
-
java读取resource目录下文件的方法示例
本文主要介绍的是java读取resource目录下文件的方法,比如这是你的src目录的结构 ├── main │ ├── java │ │ └── com │ │ └── test │ │ └── core │ │ ├── bean │ │ ├── Test.java │ └── resources │ └── test │ ├── test.txt └── test └── java 我们希望在Test.java中读取test.txt文件中的内容,那么我们可以借助Guava库的Resource
-
C# 提取PDF中的表格详情
目录 1.简单介绍 2.环境配置 3.代码示例 1.简单介绍 本文介绍在C#程序中(附VB.NET代码)提取PDF中的表格的方法,调用Spire.PDF for .NET提供的提取表格的 类 以及 方法 等来获取表格单元格中的文本内容:代码内容中涉及到的主要类及方法归纳如下表,供参考: 类型 描述 PdfDocument Class Represents a pdf document model. PdfDocument.LoadFromFile(string filename) Method
-
Java 在PDF中添加条形码的两种方法
条形码,是由宽度不等的多个黑条和空白所组成,用以表达一组信息的图形标识符.通过给文档添加条形码,可以直观,快捷地访问和分享一些重要的信息.本文就将通过使用Java程序来演示如何在PDF文档中添加Codebar.Code128A和Code39条形码.除此之外,还可支持创建Code11.Code128B.Code32.Code39 Extended .Code93和Code93 Extended条形码. 使用工具:Free Spire.PDF for Java(免费版) Jar文件获取及导入: 方法
-
Java 在PDF中绘制形状的两种方法
在我们编辑PDF文档的过程中,有时候需要在文档中添加一些如多边形.矩形.椭圆形之类的图形,而Free Spire PDF for Java 则正好可以帮助我们在Java程序中通过代码在PDF文档中绘制形状,以及设置形状边线颜色和填充色. Jar包导入 方法一:下载Free Spire.PDF for Java包并解压缩,然后将lib文件夹下的Spire.Pdf.jar包作为依赖项导入到Java应用程序中 方法二:直接通过Maven仓库安装JAR包,配置pom.xml文件的代码如下: <repos
-
java不解压直接读取压缩包中文件的实现方法
前言 最近写了个上传压缩包,将压缩包中的图片保存的接口,所以翻了翻网上文件流操作的博客,总结了一个不用解压,直接读取文件的方法 上代码 @RequestMapping(value = "packageUpload") public void packageUpload(HttpServletRequest request, HttpServletResponse response) { File file = null; try { MultipartHttpServletReques