详解pytorch的多GPU训练的两种方式
目录
- 方法一:torch.nn.DataParallel
- 1. 原理
- 2. 常用的配套代码如下
- 3. 优缺点
- 方法二:torch.distributed
- 1. 代码说明
方法一:torch.nn.DataParallel
1. 原理
如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min。

这里的作业就是pytorch中要处理的data。
与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完。最后他再花3min把作业收起来,一共需要66min。
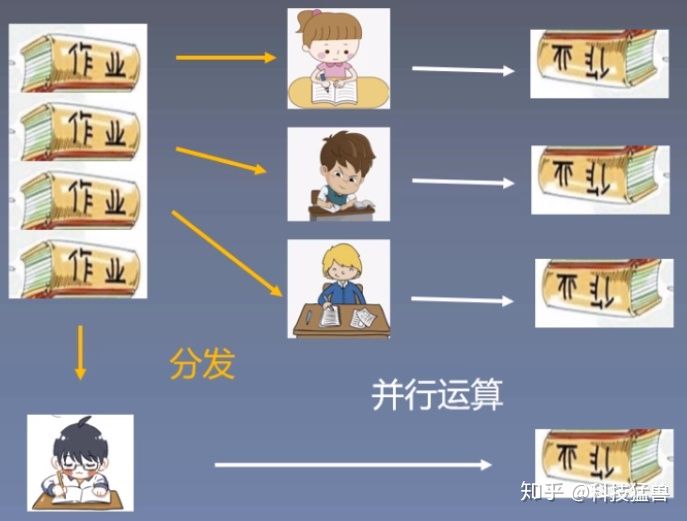
这个小朋友就是主GPU。他的过程是:分发 ->并行运算->结果回收。
这就是pytorch要使用的第一种并行方法:torch.nn.DataParallel
这种方法也称为单进程多GPU训练模式:DP模式,这种并行模式下并行的多卡都是由一个进程进行控制。换句话说,在进行梯度的传播时,是在主GPU上进行的。

采用torch.nn.DataParallel进行多GPU并行训练时,与其搭配的数据读取代码是:torch.utils.data.DataLoader
2. 常用的配套代码如下
train_datasets = customData(train_txt) #创建datasettrain_dataloaders = torch.utils.data.DataLoader(train_datasets,opt.batch_size,num_workers=train_num_workers,shuffle=True) #创建dataloadermodel = efficientnet_b0(num_classes = opt.num_class) #创建modeldevice_list = list(map(int,list(opt.device_id)))print("Using gpu"," ".join([str(v) for v in device_list]))device = device_list[0] #主GPU,也就是分发任务和结果回收的GPU,也是梯度传播更新的GPUmodel = torch.nn.DataParallel(model,device_ids=device_list)model.to(device)for data in train_dataloaders: model.train(True) inputs, labels = data inputs = Variable(inputs.to(device)) #将数据放到主要GPU labels = Variable(labels.to(device)) 3. 优缺点
- 优点:配置起来非常方便
- 缺点:GPU负载不均衡,主GPU的负载很大,而其他GPU的负载很少
方法二:torch.distributed
1. 代码说明
这个方法本来是用于多机器多卡(多节点多卡)训练的,但是也可以用于单机多卡(即将节点数设置为1)训练。
初始化的代码如下,这个一定要写在最前面。
from torch.utils.data.distributed import DistributedSampler torch.distributed.init_process_group(backend="nccl")
这里给出一个简单的demo.py作为说明:
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
from torch.utils.data.distributed import DistributedSampler
# 1) 初始化
torch.distributed.init_process_group(backend="nccl")
input_size = 5
output_size = 2
batch_size = 30
data_size = 90
# 2) 配置每个进程的gpu
local_rank = torch.distributed.get_rank()
print('local_rank',local_rank)
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size).to('cuda')
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
dataset = RandomDataset(input_size, data_size)
# 3)使用DistributedSampler
rand_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
sampler=DistributedSampler(dataset))
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
# 4) 封装之前要把模型移到对应的gpu
model.to(device)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 5) 封装
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
for data in rand_loader:
if torch.cuda.is_available():
input_var = data
else:
input_var = data
output = model(input_var)
print("Outside: input size", input_var.size(), "output_size", output.size())
(1)启动方式:在torch.distributed当中提供了一个用于启动的程序torch.distributed.launch,此帮助程序可用于为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程。
(2)启动命令:
CUDA_VISIBLE_DEVICES=1,2,3,4 python -m torch.distributed.launch --nproc_per_node=2 torch_ddp.py
这里需要说明一下参数:
- CUDA_VISIBLE_DEVICES:设置我们可用的GPU的id
- torch.distributed.launch:用于启动多节点多GPU的训练
- nproc_per_node:表示设置的进程数量,一般情况设置为可用的GPU数量,即有多少个可用的GPU就设置多少个进程。
- local rank:关于这个参数的意义,我们将在后面的情形中进行说明。
(3)一些情形的说明:
情形1:直接运行上述的命令
运行的结果如下:
local_rank 1
local_rank 0
Let's use 4 GPUs!
Let's use 4 GPUs!
In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([15, 5]) output_size torch.Size([15, 2])
In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([15, 5]) output_size torch.Size([15, 2])
可以看到local rank的输出为0和1,其数量与我们设置的nproc_per_node是一样的,与我们设置的可用GPU的数量是无关的。这里就要说明一下local rank的意义。
local rank:表示的是当前的进程在当前节点的编号,因为我们设置了2个进程,因此进程的编号就是0和1
在很多博客中都直接说明local_rank等于进程内的GPU编号,这种说法实际上是不准确的。这个编号并不是GPU的编号!!
在使用启动命令时,torch.distributed.launch工具会默认地根据nproc_per_node传入local_rank参数,之后再通过下面的代码可以得到local_rank.
local_rank = torch.distributed.get_rank()
因为是默认传入参数local_rank,所以还可以这么写,其输出与torch.distributed.get_rank()相同
import argparse
parser = argparse.ArgumentParser()
# 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
print('local_rank',args.local_rank)
情形2:将nproc_per_node设置为4,即将进程数设置为可用的GPU数
运行结果如下:
local_rank 2
local_rank 3
local_rank 1
local_rank 0
Let's use 4 GPUs!
Let's use 4 GPUs!
Let's use 4 GPUs!
Let's use 4 GPUs!
In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2])
Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2])
In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2])
Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2])
In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2])
Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2])
In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2])
Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2])
可以看到,此时的local_rank共有4个,与进程数相同。并且我们设置的可用GPU的id是1,2,3,4,而local_rank的输出为0,1,2,3,可见local_rank并不是GPU的编号。
虽然在代码中模型并行的device_ids设置为local_rank,而local_rank为0,1,2,3,但是实际上还是采用可用的GPU:1,2,3,4。可以通过nvidia-smi来查看,PID为86478,86479,86480,864782。
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
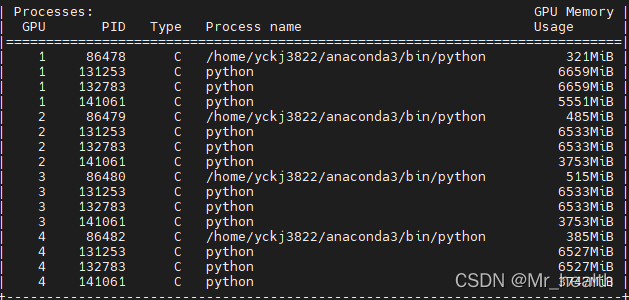
情形3:将nproc_per_node设置为4,但是不设置可用的GPU ID
python -m torch.distributed.launch --nproc_per_node=4 ddp.py
此时我们再使用nvidia-smi来查看GPU的使用情况,如下。可以看到此时使用的GPU就是local rank的id。相比于情形2,我们可以总结:
当没有设置可用的GPU ID时,所采用的GPU id就等于local rank的id。本质上是将进程的编号作为GPU编号使用,因此local_rank等于进程的编号这个定义是不变的。
当设置可用的GPU ID,所采用的GPU id就等于GPU id。
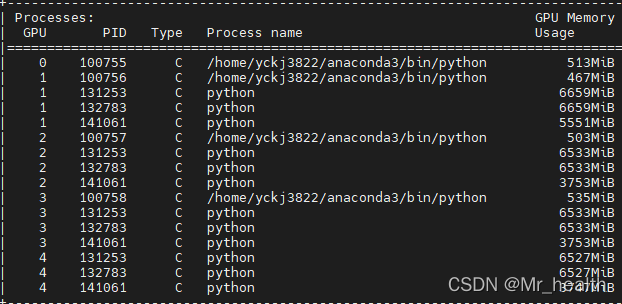
情形4:将nproc_per_node设置为5,即超出了可以用的GPU数
输出结果如下,可以看到是报错的,因为进程数超出了可以用的GPU数量
local_rank 3
local_rank 2
local_rank 4
local_rank 1
local_rank 0
THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal
Traceback (most recent call last):
File "ddp.py", line 18, in <module>
torch.cuda.set_device(local_rank)
File "/home/yckj3822/anaconda3/lib/python3.6/site-packages/torch/cuda/__init__.py", line 281, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: cuda runtime error (101) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:59
到此这篇关于详解pytorch的多GPU训练的两种方式的文章就介绍到这了,更多相关pytorch的多GPU训练内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验. 多GPU训练 cifar10_97.23 使用 run.sh 文件开始训练 cifar10_97.50 使用 run.4GPU.sh 开始训练 在集群中改变GPU调用个数修改 run.sh 文件 nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU & 修改 –gres=gpu:
-
解决pytorch多GPU训练保存的模型,在单GPU环境下加载出错问题
背景 在公司用多卡训练模型,得到权值文件后保存,然后回到实验室,没有多卡的环境,用单卡训练,加载模型时出错,因为单卡机器上,没有使用DataParallel来加载模型,所以会出现加载错误. 原因 DataParallel包装的模型在保存时,权值参数前面会带有module字符,然而自己在单卡环境下,没有用DataParallel包装的模型权值参数不带module.本质上保存的权值文件是一个有序字典. 解决方法 1.在单卡环境下,用DataParallel包装模型. 2.自己重写Load函数,灵活.
-
pytorch使用horovod多gpu训练的实现
pytorch在Horovod上训练步骤分为以下几步: import torch import horovod.torch as hvd # Initialize Horovod 初始化horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) 分配到每个gpu上 torch.cuda.set_device(hvd.local_rank()) # Define dataset... 定义d
-

详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个
-
详解Python修复遥感影像条带的两种方式
GDAL修复Landsat ETM+影像条带 Landsat7 ETM+卫星影像由于卫星传感器故障,导致此后获取的影像出现了条带.如下图所示, 影像中均匀的布满条带. 使用GDAL修复影像条带的代码如下: def gdal_repair(tif_name, out_name, bands): """ tif_name(string): 源影像名 out_name(string): 输出影像名 bands(integer): 影像波段数 """ #
-
详解python连接telnet和ssh的两种方式
目录 Telnet 连接方式 ssh连接方式 Telnet 连接方式 #!/usr/bin/env python # coding=utf-8 import time import telnetlib import logging __author__ = 'Evan' save_log_path = 'result.txt' file_mode = 'a+' format_info = '%(asctime)s - %(filename)s[line:%(lineno)d] - %(level
-
详解JavaScript发送埋点请求的两种方式
目录 一.用法 1.动态创建<img> 2.动态创建<script> 二.区别 区别1 区别2 三.选择哪种方式 四.总结 对于统计页面数据这样的情景(俗称埋点),我们常用的方式就是动态创建<img>或<script>,至于原因,一般有以下几点: 1.埋点一般不用关心请求的结果 2.可以实现跨域请求 3.无需使用ajax就能达到发请求的目的 4.都是原生实现,兼容性好 现就两种方式做一下对比和总结: 一.用法 1.动态创建<img> 方式1:通过
-
详解Spring Boot 中实现定时任务的两种方式
在 Spring + SpringMVC 环境中,一般来说,要实现定时任务,我们有两中方案,一种是使用 Spring 自带的定时任务处理器 @Scheduled 注解,另一种就是使用第三方框架 Quartz ,Spring Boot 源自 Spring+SpringMVC ,因此天然具备这两个 Spring 中的定时任务实现策略,当然也支持 Quartz,本文我们就来看下 Spring Boot 中两种定时任务的实现方式. @Scheduled 使用 @Scheduled 非常容易,直接创建一个
-
详解IntelliJ IDEA创建spark项目的两种方式
Intellij是进行scala开发的一个非常好用的工具,可以非常轻松查看scala源码,当然用它来开发Java也是很爽的,之前一直在用scala ide和eclipse,现在换成intellij简直好用到飞起,但是有些人不知道怎么用intellij去创建一个spark项目,这里介绍两种 1.选择File->new Project->Java->Scala,这里scala版本是2.11.8 2 .之后一路点击next,直到finish,创建完的项目见下图,这时候已经可以创建scala文件
-
详解Android提交数据到服务器的两种方式四种方法
Android应用开发中,会经常要提交数据到服务器和从服务器得到数据,本文主要是给出了利用http协议采用HttpClient方式向服务器提交数据的方法. 代码比较简单,这里不去过多的阐述,直接看代码. /** * @author Dylan * 本类封装了Android中向web服务器提交数据的两种方式四种方法 */ public class SubmitDataByHttpClientAndOrdinaryWay { /** * 使用get请求以普通方式提交数据 * @param map 传
-
详解Centos下YUM安装PHP的两种方式
在Centos下安装PHP时, 先后使用了两种方式进行实现, 现整理出来以作记录. 摘要 一般Centos下安装软件我们采用源码安装或者RPM包安装的方式,有时候更简单我们可以采用YUM源的方式 安装PHP的时候有个特殊的地方,其有两个YUM源可供选择 Webtatic方式安装升级PHP 安装webtatic源 [root@i-bskmtj6q ~]# rpm -Uvh https://mirror.webtatic.com/yum/el6/latest.rpm Retrieving https
-
详解android与服务端交互的两种方式
做Android开发的程序员必须知道android客户端应该如何与服务端进行交互,这里主要介绍的是使用json数据进行交互.服务端从数据库查出数据并以json字符串的格式或者map集合的格式返回到客户端,客户端进行解析并输出到手机屏幕上. 此处介绍两种方式:使用Google原生的Gson解析json数据,使用JSONObject解析json数据 一.使用Google原生的Gson解析json数据: 记得在客户端添加gson.jar. 核心代码: 服务端: package com.mfc.ctrl
-
详解Spring-boot中读取config配置文件的两种方式
了解过spring-Boot这个技术的,应该知道Spring-Boot的核心配置文件application.properties,当然也可以通过注解自定义配置文件的信息. Spring-Boot读取配置文件的方式: 一.读取核心配置文件信息application.properties的内容 核心配置文件是指在resources根目录下的application.properties或application.yml配置文件,读取这两个配置文件的方法有两种,都比较简单. 核心配置文件applicati