Java基于WebMagic爬取某豆瓣电影评论的实现
目的
搭建爬虫平台,爬取某豆瓣电影的评论信息。
准备
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。
下载WebMagic源码,或Maven导入,或Jar包方式导入。 码云地址:https://gitee.com/flashsword20/webmagic
试运行
搭建好后打开项目, 在 us.codecraft.webmagic.processor.example 包下有几个可运行的例子,我们可以直接运行体验(BaiduBaikePageProcessor 百度百科的这个比较稳定)。
爬到结果说明没问题。

自定义爬虫
接下来我们自己编写一个爬取豆瓣评论的爬虫。
爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0

F12进入开发者模式 分析前端页面
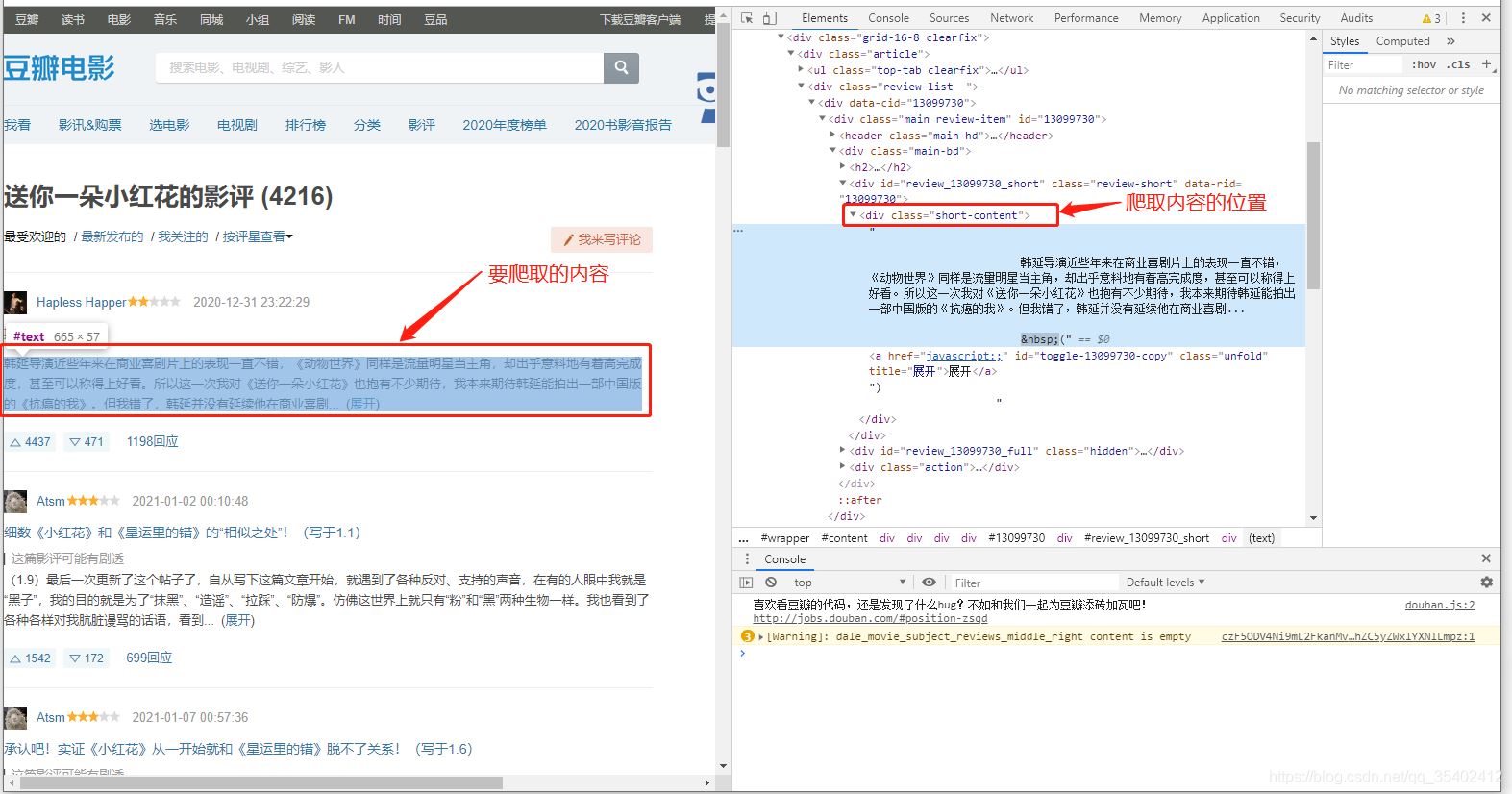
我们发现我们需要爬取的评论信息存放在 class=short-content的div 中。
创建一个豆瓣爬取的类DoubanPageProcessor如下:
package us.codecraft.webmagic.processor.example;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
import java.util.Map;
/**
* A simple PageProcessor.
* 爬取豆瓣某电影的评论 爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0
*
* @author code4crafter@gmail.com <br>
* @since 0.1.0
*/
public class DoubanPageProcessor implements PageProcessor {
private Site site;
public DoubanPageProcessor(String urlPattern) {
this.site = Site.me().setRetryTimes(3).setSleepTime(300); // 设置站点重试次数3 间隔300ms
}
@Override
public void process(Page page) {
page.putField("title", page.getHtml().xpath("//title/text()")); //爬取网页标题
// page.putField("html", page.getHtml().toString()); //爬取整个页面的html
page.putField("titleList", page.getHtml().css("div.short-content", "text").all()); // 我们要爬取的核心信息内容,获取方式与css选择器用法一样
// page.putField("content", page.getHtml().smartContent());
}
@Override
public Site getSite() {
//settings
return site;
}
public static void main(String[] args) {
Spider spider = Spider.create(new DoubanPageProcessor("https://movie\\.douban\\.com\\d+"));
ResultItems resultItems = spider.<ResultItems>get("https://movie.douban.com/subject/35096844/reviews?start=0");// 爬取并获得爬取结果
Map<String, Object> map = resultItems.getAll();
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue()); //打印爬取的所有内容
}
List<String> shortList = (List<String>) map.get("titleList");
System.out.println("=====================分隔线===================\n短评如下:");
for (int i = 0; i < shortList.size(); i++) {
System.out.println(i + "、" + shortList.get(i).trim()); // 打印爬取的评论内容
}
spider.close();
}
}
运行结果如下:

爬取成功。
到此这篇关于Java基于WebMagic爬取某豆瓣电影评论的实现的文章就介绍到这了,更多相关Java WebMagic爬取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java爬取豆瓣电影数据的方法详解
本文实例讲述了Java爬取豆瓣电影数据的方法.分享给大家供大家参考,具体如下: 所用到的技术有Jsoup,HttpClient. Jsoup jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. HttpClient HTTP 协议可能是现在 Internet 上使用得最多.最重要的协议了,越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资
-

java爬取豆瓣电影示例解析
为什么我们要爬取数据 在大数据时代,我们要获取更多数据,就要进行数据的挖掘.分析.筛选,比如当我们做一个项目的时候,需要大量真实的数据的时候,就需要去某些网站进行爬取,有些网站的数据爬取后保存到数据库还不能够直接使用,需要进行清洗.过滤后才能使用,我们知道有些数据是非常真贵的. 分析豆瓣电影网站 我们使用Chrome浏览器去访问豆瓣的网站如 https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=re
-
Java基于WebMagic爬取某豆瓣电影评论的实现
目的 搭建爬虫平台,爬取某豆瓣电影的评论信息. 准备 webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发.webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料. 下载WebMagic源码,或Maven导入,或Jar包方式导入. 码云地址:https://gitee.com/flashsword20/webmagic 试运行 搭建好后打开项目, 在 us.codecraft.webmagic.processor
-
如何基于Python爬取隐秘的角落评论
"一起去爬山吧?" 这句台词火爆了整个朋友圈,没错,就是来自最近热门的<隐秘的角落>,豆瓣评分8.9分,好评不断. 感觉还是蛮不错的.同时,为了想更进一步了解一下小伙伴观剧的情况,永恒君抓取了爱奇艺平台评论数据并进行了分析.下面来做个分享,给大伙参考参考. 1.爬取评论数据 因为该剧是在爱奇艺平台独播的,自然数据源从这里取比较合适.永恒君爬取了<隐秘的角落>12集的从开播日6月16日-6月26日的评论数据. 使用 Chrome 查看源代码模式,在播放页面往下面滑
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
java通过Jsoup爬取网页过程详解
这篇文章主要介绍了java通过Jsoup爬取网页过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,导入依赖 <!--java爬虫--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.3</version> </depe
-
java代理实现爬取代理IP的示例
仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2) 如果用了pom,那么就是以下两个: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.28</version> </depe
-
python基于selenium爬取斗鱼弹幕
针对弹幕的爬取我们如果只需要获取看到的网页里面的而数据,使用selenium就能实现,对于直播平台来说,往往有第三方平台api让你获取数据(可以获取发弹幕,发弹幕者的名字礼物等等,这需要客户端向弹幕服务器发送登录请求,心跳信息的发送等等)只获取弹幕信息储存到txt文件中,上代码,上图片 代码如下: import time from selenium import webdriver chrome_options = webdriver.ChromeOptions() # 使用headless无界
-
c# 爬取优酷电影信息(2)
上一章节中我们实现了对优酷单页面的爬取,简单进行回顾一下,使用HtmlAgilityPack库,对爬虫的爬取一共分为三步 爬虫步骤 加载页面 解析数据 保存数据 继第一篇文档后的爬虫进阶,本文章主要是对上一篇的进阶.实现的功能主要为: 1.爬取电影类别列表 2.循环每个类别的电影信息,对每个类别的信息分页爬取 3.爬取的数据保存到数据库中 一.爬取电影类别列表 使用Chrome浏览器,F12,找到当前位置,得到当前位置的Xpath.我们需要的数据是电影的类别编码和电影类别名称. 规则分析: XP
-
c# 爬取优酷电影信息(1)
爬虫的制作主要分为三个方面 1.加载网页结构 2.解析网页结构,转变为符合需求的数据实体 3.保存数据实体(数据库,文本等) 在实际的编码过程中,找到了一个好的类库"HtmlAgilityPack". 介绍: 官网:http://html-agility-pack.net/?z=codeplex Html Agility Pack源码中的类大概有28个左右,其实不算一个很复杂的类库,但它的功能确不弱,为解析DOM已经提供了足够强大的功能支持,可以跟jQuery操作DOM媲美) 使用说明
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
c# 基于Titanium爬取微信公众号历史文章列表
github:https://github.com/justcoding121/Titanium-Web-Proxy 什么是Titanium 基于C#的跨平台异步HTTP(S)代理服务器 类似的还有: https://github.com/http-party/node-http-proxy 原理简述 对于HTTP 顾名思义,其实代理就是一个「中间人」角色,对于连接到它的客户端来说,它是服务端:对于要连接的服务端来说,它是客户端.它就负责在两端之间来回传送 HTTP 报文. 对于HTTPS 由于