Python-docx 实现整体修改或者部分修改文字的大小和字体类型
Python中可以用docx来生成word文档,docx中可以自定义文字的大小和字体等。
其中要整体修改文字的字体大小和字体,可以用以下方法:
newfile = docx.Document()
newfile.styles['Normal'].font.name = 'Times New Roman'
newfile.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
设置字体的两句一定要一起用才能起作用,其中
newfile.styles['Normal'].font.name = 'Times New Roman' 是用来设置当文字是西文时的字体,
newfile.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') 是用来设置当文字是中文时的字体。
有点类似Word中的
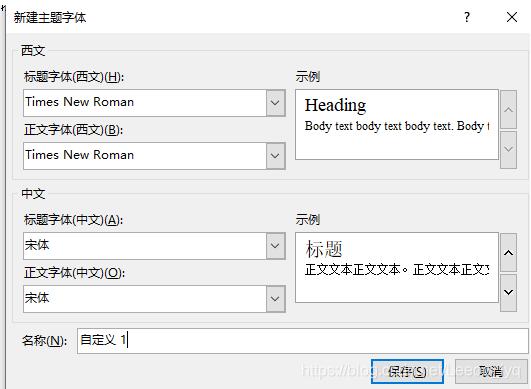
当只要设置一部分文字的字体,即不要整个文档的字体都一样时,可以用以下方法:
import docx
from docx.oxml.ns import qn
from docx.shared import Pt
newfile = docx.Document()
p1 = newfile.add_paragraph()
text1 = p1.add_run("第一段文字是中文;The first paragraph is in English")
p2 = newfile.add_paragraph()
text2 = p2.add_run("第二段文字是中文;The second paragraph is in English")
# 分别控制每个段落的字体
text1.font.size = Pt(15) # 字体大小
text1.bold = True # 字体是否加粗
text1.font.name = 'Times New Roman' # 控制是西文时的字体
text1.element.rPr.rFonts.set(qn('w:eastAsia'), '宋体') # 控制是中文时的字体
text2.font.size = Pt(10)
text2.bold = False # 字体是否加粗
text2.font.name = 'Times New Roman'
text2.element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
newfile.save("newdocx.docx")
上面代码是向文档写入了两段文字,第一段中的中文是“宋体”的,而第二段中的中文是“黑体”的。
补充:python 使用 python-docx 调整 Word 文档样式
修改文字字体样式
from docx import Document
from docx.shared import Pt #设置像素、缩进等
from docx.shared import RGBColor #设置字体颜色
from docx.oxml.ns import qn
doc = Document(r"../wordDemo/表彰大会通知.docx")
for paragraph in doc.paragraphs:
for run in paragraph.runs:
run.font.bold = True
run.font.italic = True
run.font.underline = True
run.font.strike = True
run.font.shadow = True
run.font.size = Pt(18)
run.font.color.rgb = RGBColor(255,0,255)
run.font.name = "黑体"
# 设置像黑体这样的中文字体,必须添加下面 2 行代码
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"),"黑体")
doc.save(r"../wordDemo/表彰大会通知.docx")
效果展示

修改段落样式
对齐样式
from docx import Document from docx.enum.text import WD_ALIGN_PARAGRAPH #设置对象居中、对齐等。 doc = Document(r"../wordDemo/表彰大会通知.docx") print(doc.paragraphs[1].text) doc.paragraphs[1].alignment = WD_ALIGN_PARAGRAPH.CENTER # 这里设置的是居中对齐 doc.save(r"../wordDemo/表彰大会通知.docx")
效果展示

行间距调整
from docx import Document from docx.enum.text import WD_ALIGN_PARAGRAPH doc = Document(r"../wordDemo/表彰大会通知.docx") for paragraph in doc.paragraphs: paragraph.paragraph_format.line_spacing = 5.0 doc.save(r"../wordDemo/表彰大会通知.docx")
效果展示

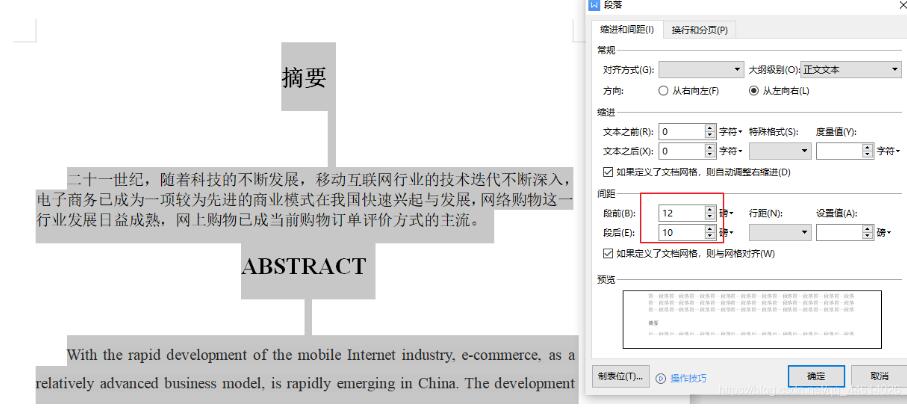
段前与段后间距
from docx import Document from docx.enum.text import WD_ALIGN_PARAGRAPH from docx.shared import Pt doc = Document(r"../wordDemo/test.docx") for paragraph in doc.paragraphs: paragraph.paragraph_format.space_before = Pt(12) # 段前 paragraph.paragraph_format.space_after = Pt(10) # 段后 # Pt(12) 表示12磅 doc.save(r"../wordDemo/test.docx")
效果展示
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

详解用 python-docx 创建浮动图片
相信大家对python-docx这个常用的操作docx文档的库都不陌生,它支持以内联形状(Inline Shape)的形式插入图片,即图片和文本之间没有重叠,遵循流动版式(flow layout).但是,截至最新的0.8.10版本,python-docx尚不支持插入浮动图片(floating picture).这显然不能满足丰富多彩的文档样式的需要,因此本文探究基于python-docx插入浮动图片--剖析xml.追踪源码,最后得到完整代码. 问题提出 作者在尝试实现PDF文档转docx(pdf
-
Python 实现向word(docx)中输出
安装python-docx pip install python-docx 如果python2安装后不能使用(找不到包),建议直接使用python3,安装代码如下 pip3 install python-docx from docx import Document from docx.shared import Pt # 简单的打开word,输入数据,关闭word document = Document() # 向word里增加段落 document.add_paragraph('hello')
-
python-docx文件定位读取过程(尝试替换)
以上是开头,安装完后需要导入转载的代码读取所有docx文件中的内容发现没有读取到表格数据: from docx import Document def readDocx(docName): fullText = [] doc = docx.Document(docName) paras = doc.paragraphs for p in paras: fullText.append(p.text) return '\n'.join(fullText) 尝试精确定位第一个表格中第一个单元格的数据(
-
python docx的超链接网址和链接文本操作
我就废话不多说了,大家还是直接看代码吧~ from docx import Document from docx import RT import re d=Document("./liu2.docx") for p in d.paragraphs: rels = d.part.rels for rel in rels: if rels[rel].reltype == RT.HYPERLINK: print("\n 超链接文本为", rels[rel], "
-
基于Python获取docx/doc文件内容代码解析
这篇文章主要介绍了基于Python获取docx/doc文件内容代码解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 整体思路: 下载文件并修改后缀为zip文件,解压zip文件,所要获取的内容在固定的文件夹下:work/temp/word/document.xml 所用包,全部是python自带,不需要额外下载安装. # encoding:utf-8 import os import re import requests import zipf
-
Python中docx2txt库的使用说明
docx2txt的Github地址 docx2txt是基于python的从docx文件中提取文本和图片的库. 代码是从python-docx中获取的.它也可以从页眉,页脚和超链接中提取文本.它现在也可以提取图像. 安装 pip install docx2txt 运行 1.命令行运行 # extract text docx2txt file.docx # extract text and images docx2txt -i /tmp/img_dir file.docx 2.在python中调用
-
python使用docx模块读写docx文件的方法与docx模块常用方法详解
一,docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的.也就是说python-docx模块会把word文档,文档中的段落.文本.字体等都看做对象,对对象进行处理就是对word文档的内容处理. 二,相关概念 如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念. 1,Document对象,表示一个word文档. 2,Paragraph对象,表示word文档中的一个段落
-
使用Python docx修改word关键词颜色的操作
需求: 在刷word题库的时候,答案就在题目下方,干扰复习效果,将答案字体变成白色,查看答案的时候只需要将答案背景刷黑 转换需求: 在word中找到关键字"答案"将其后面的信息改变颜色为白色 由于第一次使用 import docx,最初想按照如上思想实现比较麻烦,后整理思路,将题库保存为txt,逐条读取转存入word,利用分割函数对关键字进行分割,关键字后面的信息即为答案改变颜色,效果和需求一致,只是新建了文件 实现代码: import os import re import docx
-
Python-docx 实现整体修改或者部分修改文字的大小和字体类型
Python中可以用docx来生成word文档,docx中可以自定义文字的大小和字体等. 其中要整体修改文字的字体大小和字体,可以用以下方法: newfile = docx.Document() newfile.styles['Normal'].font.name = 'Times New Roman' newfile.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') 设置字体的两句一定要一起用才能起作用,其中 n
-
python 设置xlabel,ylabel 坐标轴字体大小,字体类型
本文介绍了python 设置xlabel,ylabel 坐标轴字体大小,字体类型,分享给大家,具体如下: #--coding:utf-8-- import matplotlib.pyplot as plt #数据设置 x1 =[0,5000,10000, 15000, 20000, 25000, 30000, 35000, 40000, 45000, 50000, 55000]; y1=[0, 223, 488, 673, 870, 1027, 1193, 1407, 1609, 1791, 2
-
Python docx库代码演示
目录 Python docx库代码演示 主业务代码 测试代码(设置字体) 总结 Python docx库代码演示 安装 需要lxml pip install python-docx 主业务代码 from openpyxl import Workbook from openpyxl import load_workbook from docx import Document from docx.oxml.ns import qn from docx.shared import Pt,RGBColo
-
python 设置xlabel,ylabel 坐标轴字体大小,字体类型
本文介绍了python 设置xlabel,ylabel 坐标轴字体大小,字体类型,分享给大家,具体如下: #--coding:utf-8-- import matplotlib.pyplot as plt #数据设置 x1 =[0,5000,10000, 15000, 20000, 25000, 30000, 35000, 40000, 45000, 50000, 55000]; y1=[0, 223, 488, 673, 870, 1027, 1193, 1407, 1609, 1791, 2
-
python调用java模块SmartXLS和jpype修改excel文件的方法
本文实例讲述了python调用java模块SmartXLS和jpype修改excel文件的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf8 -*- """ 使用java的模块SmartXLS和jpype修改excel 和xlrd,xlwt不同的是它可以生成和保持图表 """ from __future__ import print_function, division import os import jpyp
-
对python中词典的values值的修改或新增KEY详解
在python中,对词典的值,可以新增,或者修改,如下: 以上这篇对python中词典的values值的修改或新增KEY详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python matplotlib绘图,修改坐标轴刻度为文字的实例
工作中偶尔需要做客流分析,用pyplot 库绘图.一般情况下, x 轴刻度默认显示为数字. 例如: 我希望x 轴刻度显示为星期日期. 查询pyplot 文档, 发现了 xtick() 函数可以修改刻度. 代码如下: import matplotlib.pyplot as plt import numpy as np #val_ls = [np.random.randint(100) + i*20 for i in range(7)] scale_ls = range(7) index_ls =
-
python pands实现execl转csv 并修改csv指定列的方法
如下所示: # -*- coding: utf-8 -*- import os import pandas as pd import numpy as np #from os import sys def appendStr(strs): return "BOQ" + strs def addBOQ(dirs, csv_file): data = pd.read_csv(os.path.join(dirs, csv_file), encoding="gbk") da
-
python实现逐个读取txt字符并修改
最近写毕业设计遇到一个问题,就是我从一个txt文件中逐个读取字符,并修改其中的内容后存到另一个txt文件中,如下图: 字符替换规则是把所有的0转化为1,把所有的255转化为0.当然程序里面需要遍历好多次,算法复杂度相当差,但还是实现了初衷,源码如下: import os with open((os.path.join('test.txt')), 'r') as f: data=f.readlines() for line in data: odom=line.split() num=map(in
-
用python对excel进行操作(读,写,修改)
一.对excel的写操作实例: 将一个列表的数据写入excel, 第一行是标题,下面行数具体的数据 import xlwt #只能写不能读 stus = [['姓名', '年龄', '性别', '分数'], ['mary', 20, '女', 89.9], ['mary', 20, '女', 89.9], ['mary', 20, '女', 89.9], ['mary', 20, '女', 89.9] ] book = xlwt.Workbook()#新建一个excel sheet = book