python如何保存文本文件
python保存文本文件的方法:
使用python内置的open()类可以打开文本文件,向文件里面写入数据可以用write()函数,写完之后,使用close()函数就可以关闭并保存文本文件了
示例代码如下:

执行结果如下:
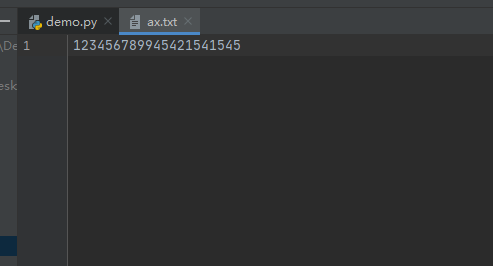
内容扩展:
Python3将数据保存为txt文件的方法,具体内容如下所示:
f = open("data/model_Weight.txt",'a') #若文件不存在,系统自动创建。'a'表示可连续写入到文件,保留原内容,在原
#内容之后写入。可修改该模式('w+','w','wb'等)
f.write("hello,sha") #将字符串写入文件中
f.write("\n") #换行
if __name__=='__main__':
fw = open("/exercise1/data/query_deal.txt", 'w') #将要输出保存的文件地址
for line in open("/exercise1/data/query.txt"): #读取的文件
fw.write("\"poiName\":\"" + line.rstrip("\n") + "\"") # 将字符串写入文件中
# line.rstrip("\n")为去除行尾换行符
fw.write("\n") # 换行
到此这篇关于python如何保存文本文件的文章就介绍到这了,更多相关python保存文本文件的方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现搜索文本文件内容脚本
本文介绍用python实现的搜索本地文本文件内容的小程序.从而学习Python I/O方面的知识.代码如下: import os #根据文件扩展名判断文件类型 def endWith(s,*endstring): array = map(s.endswith,endstring) if True in array: return True else: return False #将全部已搜索到的关键字列表中的内容保存到result.log文件中 def writeResultLog(allExi
-
Python文本文件的合并操作方法代码实例
我们有时候,看到几k的日志文件,一大堆,一个一个打开又很麻烦,少看几个,又担心遗漏,这个时候,如果有一个可以合并所有文本文件的工具就好了. 下面这个代码就可以实现,它不局限于.txt格式,基本上字符型的文本文档,包括.py格式,.c格式都可以,生成的文件与原来的文件在同一个文件夹下,'joined xxxx-xx-xx.(扩展名)'就是最终的名字. 上代码: import os import datetime # 新的文件名中以日期结尾,以下获取系统日期 date = str(datetime.
-
Python 文本文件内容批量抽取实例
Python新手编写脚本处理数据,各种心酸各种语法查找,以此留念! 原始数据格式如下图所示: 这里是一个人脸测试数据,其中每行第一个为测试图片编号,后面为Top 7图片编号及其对应的评分,即与测试图片的相似度度量结果.我们这里的目的是将每行Top 7对应的评分数据抽取出来,并且将评分第二的数值与一个阈值(这里是0.7)进行比较,超过阈值表示此次测试成功,结果为正样本,记为1,否则置0.并最终将其保存至另一个文本文件用于作为机器学习模型的训练样本数据. Python脚本处理后的文件格式如下所示:
-
python检索特定内容的文本文件实例
windows环境下python2.7 脚本指定一个参数作为要检索的字符串 例如: >find.py ./ hello # coding=utf-8 import os import sys # 找到当前目录下的所有文本文件 def findFile(path): f = [] d = [] l = os.listdir(path) for x in l: if os.path.isfile(os.path.join(os.getcwd() + "\\", x)): f.appe
-
python实现大文本文件分割
本文实例为大家分享了python实现大文本文件分割的具体代码,供大家参考,具体内容如下 开发环境 Python 2 实现效果 通过文件拖拽或文件路径输入,实现自定义大文本文件分割. 代码实现 #coding:gbk import os,sys,shutil is_file_exits=False while not is_file_exits: files_list=[] if(len(sys.argv)==1): print('请输入要切割的文件完整路径:') files_path=raw_i
-
python如何保存文本文件
python保存文本文件的方法: 使用python内置的open()类可以打开文本文件,向文件里面写入数据可以用write()函数,写完之后,使用close()函数就可以关闭并保存文本文件了 示例代码如下: 执行结果如下: 内容扩展: Python3将数据保存为txt文件的方法,具体内容如下所示: f = open("data/model_Weight.txt",'a') #若文件不存在,系统自动创建.'a'表示可连续写入到文件,保留原内容,在原 #内容之后写入.可修改该模式('w+'
-
Python实现统计文本文件字数的方法
本文实例讲述了Python实现统计文本文件字数的方法.分享给大家供大家参考,具体如下: 统计文本文件的字数,从当前目录下的file.txt取文件 # -*- coding: GBK -*- import string import sys reload(sys) def compareItems((w1,c1), (w2,c2)): if c1 > c2: return - 1 elif c1 == c2: return cmp(w1, w2) else: return 1 def main()
-
Python批量修改文本文件内容的方法
Python批量替换文件内容,支持嵌套文件夹 import os path="./" for root,dirs,files in os.walk(path): for name in files: #print name if name.endswith(".html"): #print root,dirs,name filename=root+"/"+name f=open(filename,"r") fileconten
-
Java使用utf8格式保存文本文件的方法
本文实例讲述了Java使用utf8格式保存文本文件的方法.分享给大家供大家参考,具体如下: FileOutputStream fos = null; OutputStreamWriter writer = null; try { File file = new File(filepath); fos = new FileOutputStream(file); writer = new OutputStreamWriter(fos,"utf-8"); writer.write(makeL
-
Python统计纯文本文件中英文单词出现个数的方法总结【测试可用】
本文实例讲述了Python统计纯文本文件中英文单词出现个数的方法.分享给大家供大家参考,具体如下: 第一版: 效率低 # -*- coding:utf-8 -*- #!python3 path = 'test.txt' with open(path,encoding='utf-8',newline='') as f: word = [] words_dict= {} for letter in f.read(): if letter.isalnum(): word.append(letter)
-
python自动保存百度盘资源到百度盘中的实例代码
本实例的实现逻辑是,应用selenium UI自动化登录百度盘,读取存储百度分享地址和提取码的txt文档,打开百度盘分享地址,填入提取码,然后保存到指定的目录中 全部代码如下: # -*-coding:utf8-*- # encoding:utf-8 import time from selenium import webdriver browser = webdriver.Chrome() def loginphont(): browser.get("https://pan.baidu.com
-
使用JavaScript保存文本文件到本地的两种方法
一段使用javascript保存文件的代码.这里方法可以保存指定id元素下的所有html内容:不过这个方法只支持IE浏览器. function createHtml() { try { save_record("index1", $("#yhtcprediv").html()); } catch (e) { alert(e); } } function save_record(filename, content) { //打开新窗口保存 var winRecord
-
用Python实现大文本文件切割的方法
在实际工作中,有些场景下,因为产品既有功能限制,不支持特大文件的直接处理,需要把大文件进行切割处理. 当然可以通过UltraEdit编辑工具,或者从网上下载一些文件切割器之类的.但这些要么手工操作太麻烦,要么不能满足自定义需求. 而且,对程序员来说,DIY一个轮子还是有必要的. Python作为快速开发工具,其代码表达力强,开发效率高,因此用Python快速写一个,还是可行的. 需求描述: 输入:给定一个带列头的csv文件,或者txt文件,或者其他文本文件. 输出:指定单文件内部行数的一系列可区
-
python 实现保存最新的三份文件,其余的都删掉
我就废话不多说了,直接上代码吧! """ 对于每天存储文件,文件数量过多,占用空间 采用保存最新的三个文件 """ from airflow import DAG from airflow.operators.python_operator import PythonOperator from airflow.models import Variable from sctetl.airflow.utils import dateutils fro
随机推荐
- AngularJS路由删除#符号解决的办法
- 比较典型的代理软件全介绍
- Git发现git push origin master 报错的解决方法
- Python中asyncore的用法实例
- javascript禁止访客复制网页内容的实现代码
- JavaScript 闭包深入理解(closure)
- ASP.NET 窗体间传值的方法
- smarty中post用法实例
- PHP利用func_get_args和func_num_args函数实现函数重载实例
- 使用url_helper简化Python中Django框架的url配置教程
- JS实现DIV高度自适应窗口示例
- 初始Nodejs
- jquery限定文本框只能输入数字(整数和小数)
- 更换电脑浏览器的两种方法
- 杰奇登录后的东西都是在session里面的
- 排序算法模板实现示例分享
- Android画图之抗锯齿paint和Canvas两种方式实例
- Python中几个比较常见的名词解释
- asp.net点选验证码实现思路分享 (附demo)
- vue 移动端注入骨架屏的配置方法