30行Python代码打造一款简单的人工语音对话
@Author:Runsen
1876年,亚历山大·格雷厄姆·贝尔(Alexander Graham Bell)发明了一种电报机,可以通过电线传输音频。托马斯·爱迪生(Thomas Edison)于1877年发明了留声机,这是第一台记录声音并播放声音的机器。
最早的语音识别软件之一是由Bells Labs在1952年编写的,只能识别数字。1985年,IBM发布了使用“隐马尔可夫模型”的软件,该软件可识别1000多个单词。
几年前,一个replace("?","")代码价值一个亿
如今,在Python中Tensorflow,Keras,Librosa,Kaldi和语音转文本API等多种工具使语音计算变得更加容易。
今天,我使用gtts和speech_recognition,教大家如何通过三十行代码,打造一款简单的人工语音对话。思路就是将语音变成文本,然后文本变成语音。
gtts
gtts是将文字转化为语音,但是需要在VPN下使用。这个因为要接谷歌服务器。
具体gtts的官方文档:
下面,让我们看一段简单的的代码
from gtts import gTTS
def speak(audioString):
print(audioString)
tts = gTTS(text=audioString, lang='en')
tts.save("audio.mp3")
os.system("audio.mp3")
speak("Hi Runsen, what can I do for you?")
执行上面的代码,就可以生成一个mp3文件,播放就可以听到了Hi Runsen, what can I do for you?。这个MP3会自动弹出来的。
speech_recognition
speech_recognition用于执行语音识别的库,支持在线和离线的多个引擎和API。
speech_recognition具体官方文档
安装speech_recognition可以会出现错误,对此解决的方法是通过该网址安装对应的whl包
在官方文档中提供了具体的识别来自麦克风的语音输入的代码
下面就是 speech_recognition 用麦克风记录下你的话,这里我使用的是
recognize_google,speech_recognition 提供了很多的类似的接口。
import time
import speech_recognition as sr
# 录下来你讲的话
def recordAudio():
# 用麦克风记录下你的话
print("开始麦克风记录下你的话")
r = sr.Recognizer()
with sr.Microphone() as source:
audio = r.listen(source)
data = ""
try:
data = r.recognize_google(audio)
print("You said: " + data)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
return data
if __name__ == '__main__':
time.sleep(2)
while True:
data = recordAudio()
print(data)
下面是我乱说的英语

对话
上面,我们实现了用麦克风记录下你的话,并且得到了对应的文本,那么下一步就是字符串的文本操作了,比如说how are you,那回答"I am fine”,然后将"I am fine”通过gtts是将文字转化为语音
# @Author:Runsen
# -*- coding: UTF-8 -*-
import speech_recognition as sr
from time import ctime
import time
import os
from gtts import gTTS
# 讲出来AI的话
def speak(audioString):
print(audioString)
tts = gTTS(text=audioString, lang='en')
tts.save("audio.mp3")
os.system("audio.mp3")
# 录下来你讲的话
def recordAudio():
# 用麦克风记录下你的话
r = sr.Recognizer()
with sr.Microphone() as source:
audio = r.listen(source)
data = ""
try:
data = r.recognize_google(audio)
print("You said: " + data)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
return data
# 自带的对话技能(逻辑代码:rules)
def jarvis():
while True:
data = recordAudio()
print(data)
if "how are you" in data:
speak("I am fine")
if "time" in data:
speak(ctime())
if "where is" in data:
data = data.split(" ")
location = data[2]
speak("Hold on Runsen, I will show you where " + location + " is.")
# 打开谷歌地址
os.system("open -a Safari https://www.google.com/maps/place/" + location + "/&")
if "bye" in data:
speak("bye bye")
break
if __name__ == '__main__':
# 初始化
time.sleep(2)
speak("Hi Runsen, what can I do for you?")
# 跑起
jarvis()
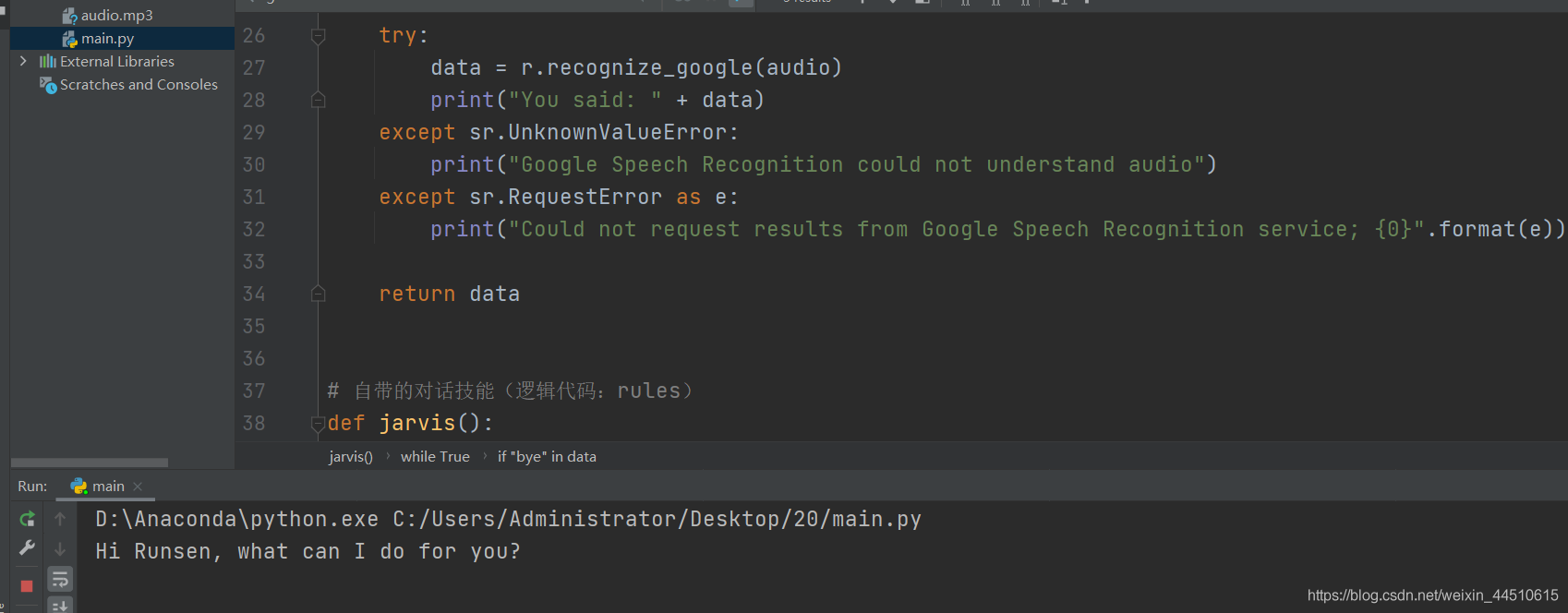
当我说how are you?会弹出I am fine的mp3
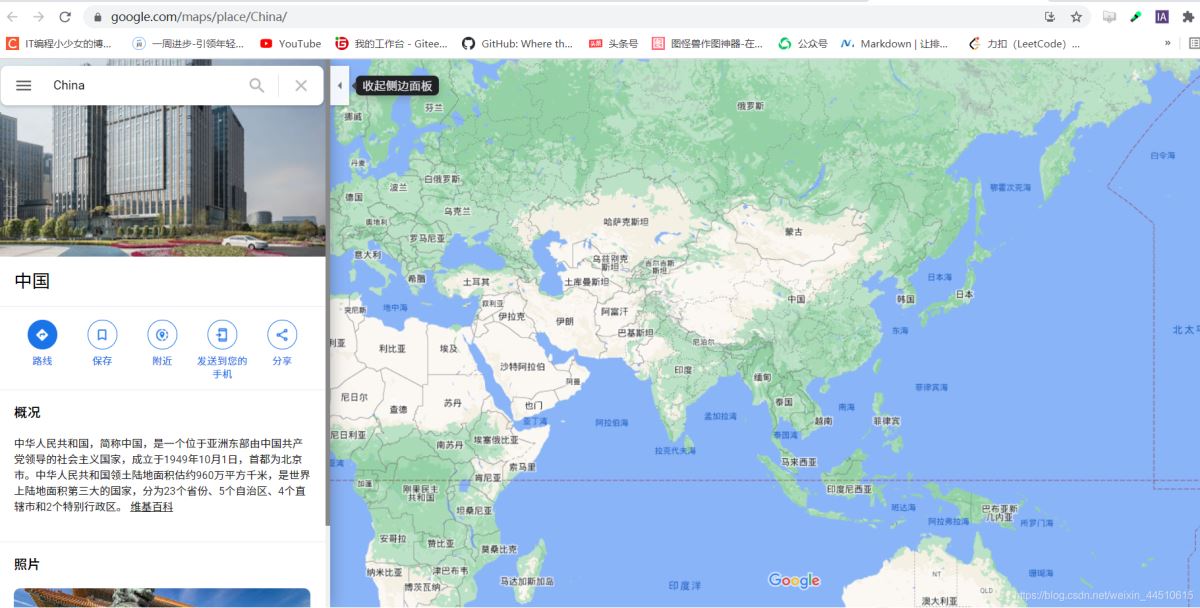
当我说where is Chiana?会弹出Hold on Runsen, I will show you where China is.的MP3

同样也会弹出China的谷歌地图
本项目对应的Github
以上就是30行Python代码打造一款简单的人工语音对话的详细内容,更多关于Python人工语音对话的资料请关注我们其它相关文章!
相关推荐
-
Python3从零开始搭建一个语音对话机器人的实现
01-初心缘由 最近在研究语音识别方向,看了很多的语音识别的资料和文章,了解了一下语音识别的前世今生,其中包含了很多算法的演变,目前来说最流行的语音识别算法主要是依赖于深度学习的神经网络算法,其中RNN扮演了非常重要的作用,深度学习的应用真正让语音识别达到了商用级别.然后我想动手自己做一个语音识别系统,从GitHub上下载了两个流行的开源项目MASR和ASRT来进行复现,发现语音识别的效果没有写的那么好,其中如果要从零来训练自己的语言模型势必会非常耗时. 因此,就有了一个新的想法,借助一些开源的
-

30行Python代码打造一款简单的人工语音对话
@Author:Runsen 1876年,亚历山大·格雷厄姆·贝尔(Alexander Graham Bell)发明了一种电报机,可以通过电线传输音频.托马斯·爱迪生(Thomas Edison)于1877年发明了留声机,这是第一台记录声音并播放声音的机器. 最早的语音识别软件之一是由Bells Labs在1952年编写的,只能识别数字.1985年,IBM发布了使用"隐马尔可夫模型"的软件,该软件可识别1000多个单词. 几年前,一个replace("?",&quo
-
20行Python代码实现一款永久免费PDF编辑工具的实现
PDF(Portable Document Format),中文名称便携文档格式是我们经常会接触到的一种文件格式,文献.文档...很多都是PDF格式.它以格式稳定的优势,使得我们在打印.分享.传输过程中能够最优的保持原有色彩和格式. PDF是以PostScript语言图像模型为基础的一种文档格式,它在格式的稳定性方面虽然具有很大优势.但是,在可编辑性方面却为使用者引入了另外一个困扰. 例如,在文档的分割.合并.剪切.转换.编辑等方面PDF就有些捉襟见肘了. Adobe Reader.福昕阅读器.
-
20行Python代码实现一款永久免费PDF编辑工具
目录 PyPDF2 删除PDF页 合并PDF 旋转 添加水印 加密 pdfminer PDF转TxT 总结 PDF是我们经常会接触到的一种文件格式,文献.文档...很多都是PDF格式.它以格式稳定的优势,使得我们在打印.分享.传输过程中能够最优的保持原有色彩和格式. PDF是以PostScript语言图像模型为基础的一种文档格式,它在格式的稳定性方面虽然具有很大优势.但是,在可编辑性方面却为使用者引入了另外一个困扰. 例如,在文档的分割.合并.剪切.转换.编辑等方面PDF就有些捉襟见肘了. Ad
-
500行Python代码打造刷脸考勤系统
需求分析 "员工刷脸考勤"系统,采用Python语言开发,可以通过摄像头添加员工面部信息,这里就涉及到两个具体的个问题,一个是应该以什么样的数据来标识每一个员工的面部信息,二是持久化地保存这些信息到数据库中去.更细地,还涉及表的设计;另一个基本要求是通过摄像头识别员工面部信息来完成考勤,这个问题基本可以通过遍历数据库里的员工面部数据与当前摄像头里的员工面部数据的比对来实现,但有一个问题就是假如摄像头里有多张人脸改怎么处理.扩展要求是导出每日的考勤表,可以拆分为两个部分,一个是存储考勤信
-
30行Python代码实现高分辨率图像导航的方法
在项目开发的过程中,经常会遇到要查看图像细节的问题,这时候我们通常会,滚动滑轮将图像放大,或者使用电脑内置的放大器功能进行查看,如下图所示,是我使用Altium Designer软件的高清晰图像导航功能查看PCB细节的效果: 那么作为一位程序员,是否可以做到这点呢? 当然可以,Python在手,天下我有~ 1.导入图像功能 导入图像功能是基于Windows命令窗口实现的,用户在命令窗口调用Python文件即可导入图像信息,输入指令及效果如下所示: 实现代码如下所示: if len(sys.arg
-
仅利用30行Python代码来展示X算法
假如你对数独解法感兴趣,你可能听说过精确覆盖问题.给定全集 X 和 X 的子集的集合 Y ,存在一个 Y 的子集 Y*,使得 Y* 构成 X 的一种分割. 这儿有个Python写的例子. X = {1, 2, 3, 4, 5, 6, 7} Y = { 'A': [1, 4, 7], 'B': [1, 4], 'C': [4, 5, 7], 'D': [3, 5, 6], 'E': [2, 3, 6, 7], 'F': [2, 7]} 这个例子的唯一解是['B', 'D', 'F']. 精确覆盖问
-
200行python代码实现2048游戏
Python实战系列用于记录实战项目中的思路,代码实现,出现的问题与解决方案以及可行的改进方向 本文为第2篇–200行Python代码实现2048 一.分析与函数设计 1.1 游戏玩法 2048这款游戏的玩法很简单,每次可以选择上下左右滑动,每滑动一次,所有的数字方块都会往滑动的方向靠拢,系统也会在空白的地方乱数出现一个数字方块,相同数字的方块在靠拢.相撞时会相加.(介绍来自百度百科) 1.2 函数设计 _init _() 初始化4*4游戏地图,分数等游戏基本数据 is_gameover() 判
-
利用ImageAI库只需几行python代码实现目标检测
什么是目标检测 目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition).相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示). 通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所
-
150行Python代码实现带界面的数独游戏
今天闲着没事干,以前做过html+js版的数独,这次做个python版本的,界面由pygame完成,数独生成由递归算法实现,由shuffle保证每次游戏都是不一样的情况,have fun: 功能列表: 图形化的数独游戏: python实现,依赖pygame库: 随机生成游戏,每次运行都不一样: 数字填入后的正确性判断以及颜色提示: 显示剩余需填入的空格,已经操作的次数: 难度可选,通过修改需要填入的空的数量: 游戏界面 初始界面 过程中界面 运行方式 python main.py 15 这里的
-
小 200 行 Python 代码制作一个换脸程序
简介 在这篇文章中我将介绍如何写一个简短(200行)的 Python 脚本,来自动地将一幅图片的脸替换为另一幅图片的脸. 这个过程分四步: 检测脸部标记. 旋转.缩放.平移和第二张图片,以配合第一步. 调整第二张图片的色彩平衡,以适配第一张图片. 把第二张图像的特性混合在第一张图像中. 1.使用 dlib 提取面部标记 该脚本使用 dlib 的 Python 绑定来提取面部标记: Dlib 实现了 Vahid Kazemi 和 Josephine Sullivan 的<使用回归树一毫秒脸部对准>