Python实现层次分析法及自调节层次分析法的示例
假设我们遇到如下问题:
①对于M个方案,每个方案有N个属性,在已知各个方案每个属性值&&任意两个属性的重要程度的前提下,如何选择最优的方案?
②对于一个层级结构,在已知各底层指标相互之间的重要程度下,如何确定各底层指标对最高级指标的权值?
… …
此时,便可用层次分析法将我们的主观想法——“谁比谁重要”转换为客观度量——“权值”
层次分析法
层次分析法的基本思想是将复杂问题分为若干层次和若干因素,在同一层次的各要素之间简单地进行比较判断和计算,并评估每层评价指标对上一层评价指标的重要程度,确定因素权重,从而为选择最优方案提出依据。步骤如下:
(1)根据自己体系中的关联及隶属关系构建有层次的结构模型,一般分为三层,分别为最高层、中间层和最低层。
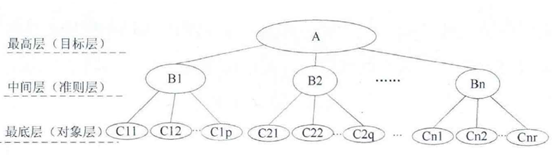
(2)构造判断矩阵
假设该层有n个评价指标u1, u2, …, un,设cij为ui相对于uj的重要程度,根据公式列出的1-9标度法,判断两两评价指标之间的重要性。

根据比较得出判断矩阵:
C=(cij)n*n其属性为cij>0, cji=1/cij,cii=1
(3)层次单排序:从下往上,对于每一层的每个判断矩阵,计算权向量和一致性检验。
计算矩阵C的最大特征根λmax及对应的特征向量(P1,P2,…, Pn)
一致性指标定义为: 
CI(Consistency Ratio)称为一致性比例。CI=0时,具有完全一致性;CI接近于0,具有满意的一致性;CI越大,不一致性越严重。
一致性比率定义为: 
其中RI称为随机性指标,参照表如下:

只有当CR<0.1,则认为该判断矩阵通过了一致性检验,即该矩阵自相矛盾产生的误差可忽略。将矩阵C最大特征根对应的特征向量元素作归一化处理,即可得到对应的权重集(C1,C2,…,Cn)。
(4)层次总排序
从上往下,依次计算每一层各指标对最上层指标的权值,以及每一层的综合一致性比率CR。
自调节层次分析法——赵中奇
由于层次分析法选用1-9标度构建判断矩阵,而大部分时候我们自己也不能很好度量重要性的程度,故赵中奇提出用-1,0,1三标度来构建判断矩阵。同时,自动调整判断矩阵,消除前后时刻主观比较重要性时的矛盾现象,即让矩阵变为一致性矩阵(CR=0)。构建并调整判断矩阵以及算权值向量的步骤如下:
(1)初始化m=1
a、确定比较矩阵C=(cij)n*n的第m行元素
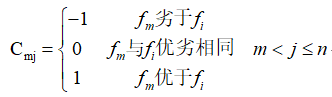
b、划分指标集合Dm={j|j=m+1,…,n}为
Hm={j|cmj=-1,j∈Dm}、Mm ={j|cmj=0,j∈Dm}与Lm={j|cmj=1,j∈Dm}
并构造集合为,其中×表示集合的笛卡尔积
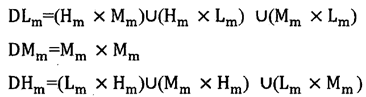
c、若DLm、DMm、DHm全为空集,转d,否则令:
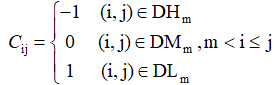
d、若m=n-1,转第二步,否则令m=m+1,转回a
(2)求比较矩阵C
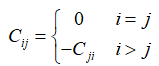
(3)求B=(bij)n*n,其中
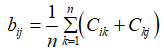
(4)求A=(aij)n*n的特征向量,作为各评价指标的相对权重值,其中:
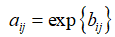
实例分析
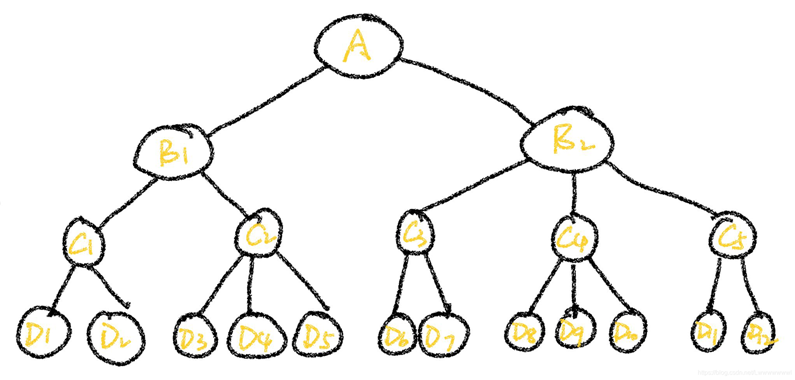
由于网上找到的代码大多只能算三层的体系,而且没有赵中奇论文中的自调节层次分析法代码。因此,自己写了一个可以计算超过3层的层次分析法和自调节层次分析法代码!
构建如下4层体系
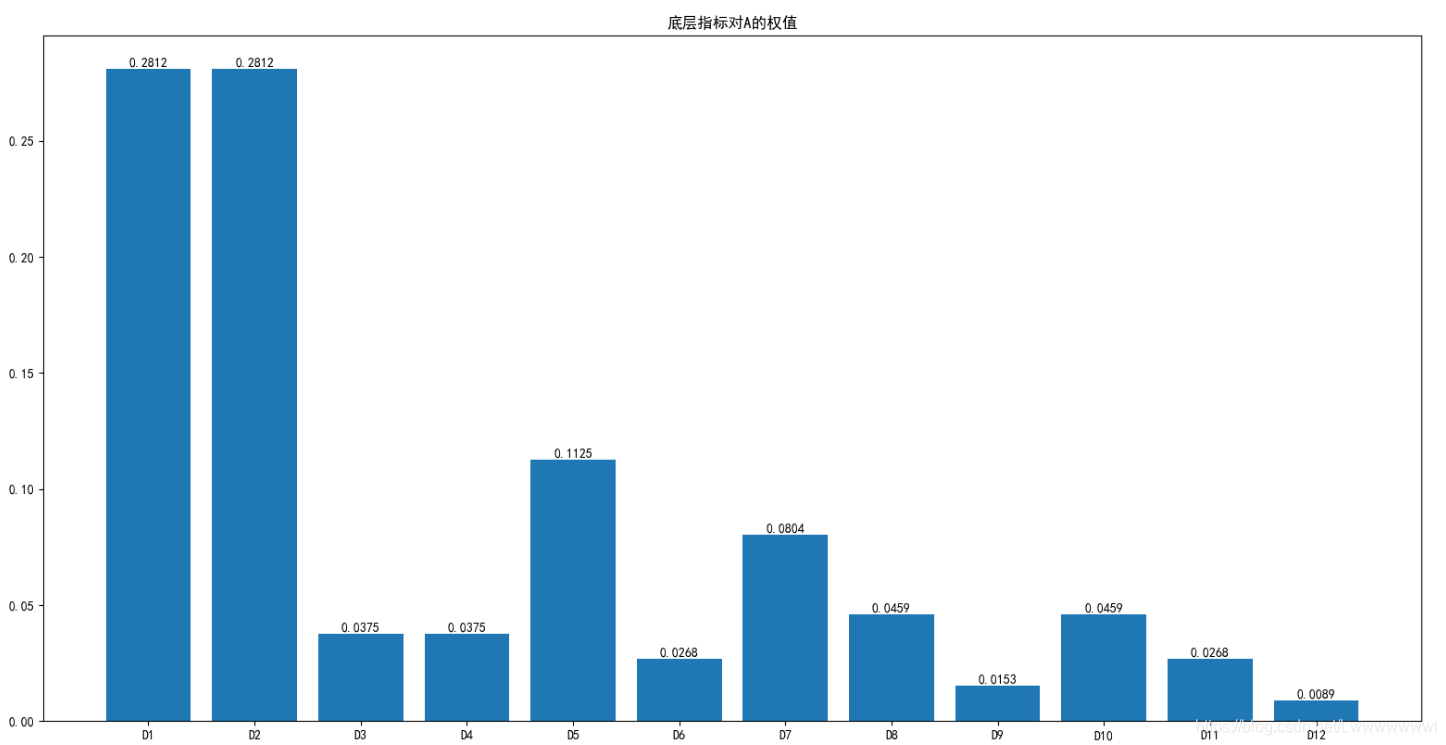
层次分析法得到的权值
判断矩阵就不列出来了了,可以在代码里找到,得到第四层对A的权值条形图如下:
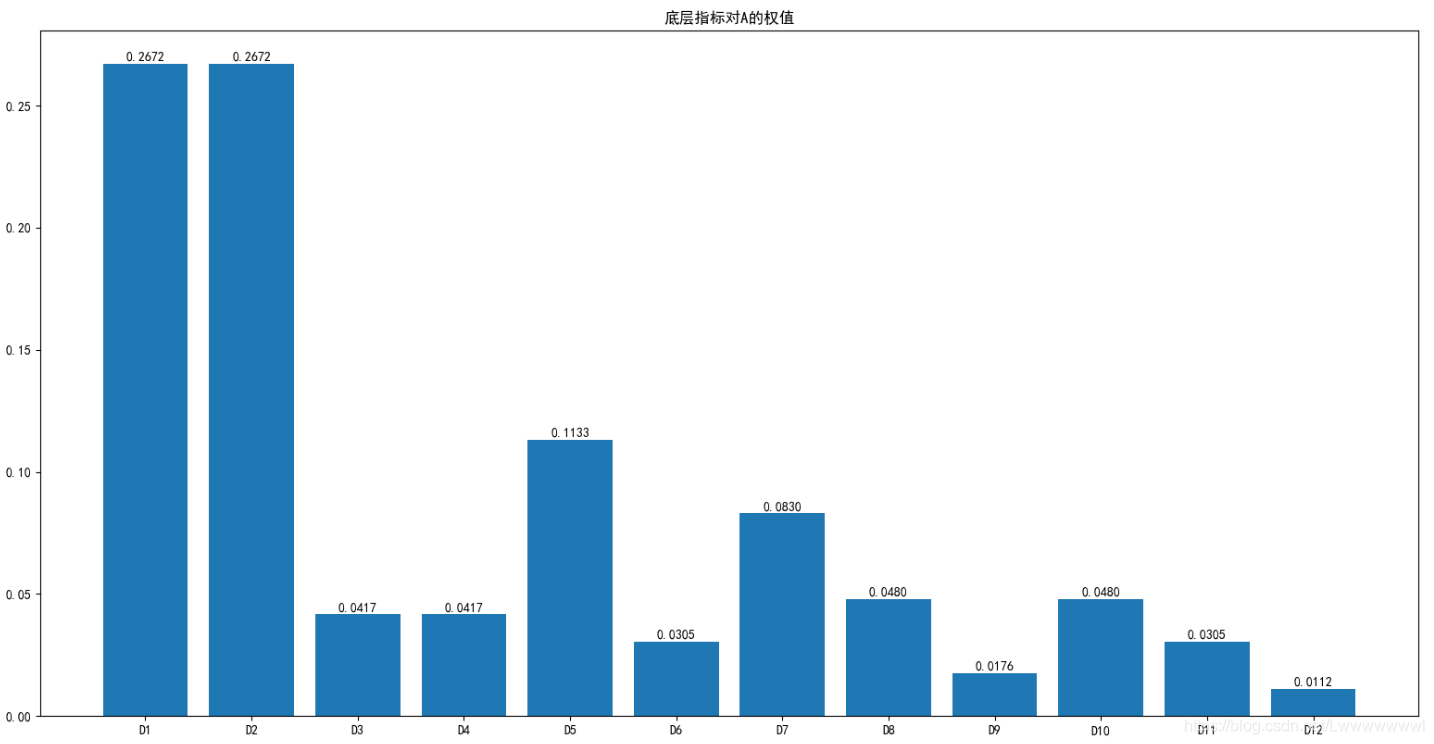
自调节层次分析法得到的权值
自调节层次分析法对高阶判断矩阵更有优势,而算低阶判断矩阵时的结果和层次分析法差不多。
代码
代码包括了层次分析法与自调节层次分析法的实例,运行的时候注释掉其中一个就行!
"""
Created on Tue Jan 26 10:12:30 2021
自适应层数的层次分析法求权值
@author: lw
"""
import numpy as np
import itertools
import matplotlib.pyplot as plt
#自适应层数的层次分析法
class AHP():
'''
注意:python中list与array运算不一样,严格按照格式输入!
本层次分析法每个判断矩阵不得超过9阶,各判断矩阵必须是正互反矩阵
FA_mx:下一层对上一层的判断矩阵集(包含多个三维数组,默认从目标层向方案层依次输入判断矩阵。同层的判断矩阵按顺序排列,且上层指标不共用下层指标)
string:默认为'norm'(经典的层次分析法,需输入9标度判断矩阵),若为'auto'(自调节层次分析法,需输入3标度判断矩阵)
'''
#初始化函数
def __init__(self,FA_mx,string='norm'):
self.RI=np.array([0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49]) #平均随机一致性指标
if string=='norm':
self.FA_mx=FA_mx #所有层级的判断矩阵
elif string=='auto':
self.FA_mx=[]
for i in range(len(FA_mx)):
temp=[]
for j in range(len(FA_mx[i])):
temp.append(self.preprocess(FA_mx[i][j]))
self.FA_mx.append(temp) #自调节层次分析法预处理后的所有层级的判断矩阵
self.layer_num=len(FA_mx) #层级数目
self.w=[] #所有层级的权值向量
self.CR=[] #所有层级的单排序一致性比例
self.CI=[] #所有层级下每个矩阵的一致性指标
self.RI_all=[] #所有层级下每个矩阵的平均随机一致性指标
self.CR_all=[] #所有层级的总排序一致性比例
self.w_all=[] #所有层级指标对目标的权值
#输入单个矩阵算权值并一致性检验(特征根法精确求解)
def count_w(self,mx):
n=mx.shape[0]
eig_value, eigen_vectors=np.linalg.eig(mx)
maxeig=np.max(eig_value) #最大特征值
maxindex=np.argmax(eig_value) #最大特征值对应的特征向量
eig_w=eigen_vectors[:,maxindex]/sum(eigen_vectors[:,maxindex]) #权值向量
CI=(maxeig-n)/(n-1)
RI=self.RI[n-1]
if(n<=2 and CI==0):
CR=0.0
else:
CR=CI/RI
if(CR<0.1):
return CI,RI,CR,list(eig_w.T)
else:
print('该%d阶矩阵一致性检验不通过,CR为%.3f'%(n,CR))
return -1.0,-1.0,-1.0,-1.0
#计算单层的所有权值与CR
def onelayer_up(self,onelayer_mx,index):
num=len(onelayer_mx) #该层矩阵个数
CI_temp=[]
RI_temp=[]
CR_temp=[]
w_temp=[]
for i in range(num):
CI,RI,CR,eig_w=self.count_w(onelayer_mx[i])
if(CR>0.1):
print('第%d层的第%d个矩阵未通过一致性检验'%(index,i+1))
return
CI_temp.append(CI)
RI_temp.append(RI)
CR_temp.append(CR)
w_temp.append(eig_w)
self.CI.append(CI_temp)
self.RI_all.append(RI_temp)
self.CR.append(CR_temp)
self.w.append(w_temp)
#计算单层的总排序及该层总的一致性比例
def alllayer_down(self):
self.CR_all.append(self.CR[self.layer_num-1])
self.w_all.append(self.w[self.layer_num-1])
for i in range(self.layer_num-2,-1,-1):
if(i==self.layer_num-2):
temp=sum(self.w[self.layer_num-1],[]) #列表降维,扁平化处理,取上一层的权值向量
CR_temp=[]
w_temp=[]
CR=sum(np.array(self.CI[i])*np.array(temp))/sum(np.array(self.RI_all[i])*np.array(temp))
if(CR>0.1):
print('第%d层的总排序未通过一致性检验'%(self.layer_num-i))
return
for j in range(len(self.w[i])):
shu=temp[j]
w_temp.append(list(shu*np.array(self.w[i][j])))
temp=sum(w_temp,[]) #列表降维,扁平化处理,取上一层的总排序权值向量
CR_temp.append(CR)
self.CR_all.append(CR_temp)
self.w_all.append(w_temp)
return
#计算所有层的权值与CR,层次总排序
def run(self):
for i in range(self.layer_num,0,-1):
self.onelayer_up(self.FA_mx[i-1],i)
self.alllayer_down()
return
#自调节层次分析法的矩阵预处理过程
def preprocess(self,mx):
temp=np.array(mx)
n=temp.shape[0]
for i in range(n-1):
H=[j for j,x in enumerate(temp[i]) if j>i and x==-1]
M=[j for j,x in enumerate(temp[i]) if j>i and x==0]
L=[j for j,x in enumerate(temp[i]) if j>i and x==1]
DL=sum([[i for i in itertools.product(H,M)],[i for i in itertools.product(H,L)],[i for i in itertools.product(M,L)]],[])
DM=[i for i in itertools.product(M,M)]
DH=sum([[i for i in itertools.product(L,H)],[i for i in itertools.product(M,H)],[i for i in itertools.product(L,M)]],[])
if DL:
for j in DL:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=1
if DM:
for j in DM:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=0
if DH:
for j in DH:
if(j[0]<j[1] and i<j[0]):
temp[int(j[0])][int(j[1])]=-1
for i in range(n):
for j in range(i+1,n):
temp[j][i]=-temp[i][j]
A=[]
for i in range(n):
atemp=[]
for j in range(n):
a0=0
for k in range(n):
a0+=temp[i][k]+temp[k][j]
atemp.append(np.exp(a0/n))
A.append(atemp)
return np.array(A)
#%%测试函数
if __name__=='__main__' :
'''
# 层次分析法的经典9标度矩阵
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[1, 3],
[1/3 ,1]]))
criteria1 = np.array([[1, 3],
[1/3,1]])
criteria2=np.array([[1, 1,3],
[1,1,3],
[1/3,1/3,1]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[1, 1], [1, 1]])
sample2 = np.array([[1,1,1/3], [1,1,1/3],[3,3,1]])
sample3 = np.array([[1, 1/3], [3, 1]])
sample4 = np.array([[1,3,1], [1 / 3, 1, 1/3], [1,3, 1]])
sample5=np.array([[1,3],[1/3 ,1]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx) #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[]) #底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
'''
#自调节层次分析法的3标度矩阵(求在线体系的权值)
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[0, 1],
[-1,0]]))
criteria1 = np.array([[0, 1],
[-1,0]])
criteria2=np.array([[0, 0,1],
[0,0,1],
[-1,-1,0]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[0, 0], [0, 0]])
sample2 = np.array([[0,0,-1], [0,0,-1],[1,1,0]])
sample3 = np.array([[0, -1], [1, 0]])
sample4 = np.array([[0,1,0], [-1, 0,-1], [0,1,0]])
sample5=np.array([[0,1],[-1 ,0]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx,'auto') #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[]) #底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
到此这篇关于Python实现层次分析法及自调节层次分析法的示例的文章就介绍到这了,更多相关Python 层次分析法及自调节层次分析法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现AHP算法的方法实例(层次分析法)
一.层次分析法原理 层次分析法(Analytic Hierarchy Process,AHP)由美国运筹学家托马斯·塞蒂(T. L. Saaty)于20世纪70年代中期提出,用于确定评价模型中各评价因子/准则的权重,进一步选择最优方案.该方法仍具有较强的主观性,判断/比较矩阵的构造在一定程度上是拍脑门决定的,一致性检验只是检验拍脑门有没有自相矛盾得太离谱. 相关的理论参考可见:wiki百科 二.代码实现 需要借助Python的numpy矩阵运算包,代码最后用了一个b1矩阵进行了调试,相关代码如下
-

Python实现层次分析法及自调节层次分析法的示例
假设我们遇到如下问题: ①对于M个方案,每个方案有N个属性,在已知各个方案每个属性值&&任意两个属性的重要程度的前提下,如何选择最优的方案? ②对于一个层级结构,在已知各底层指标相互之间的重要程度下,如何确定各底层指标对最高级指标的权值? - - 此时,便可用层次分析法将我们的主观想法--"谁比谁重要"转换为客观度量--"权值" 层次分析法 层次分析法的基本思想是将复杂问题分为若干层次和若干因素,在同一层次的各要素之间简单地进行比较判断和计算,并评估
-
Python自动化运维_文件内容差异对比分析
模块:difflib 安装:Python版本大于等于2.3系统自带 功能:对比文本之间的差异,而且支持输出可读性比较强的HTML文档,与Linux中的diff命令比较相似. 两个字符串的差异对比: #import difflib #text1=''' #hello world. #how are you. #nice to meet you. #''' #text1_lines=text1.splitlines() # 以行进行分割,便于进行对比 #text2=''' #Hello World.
-
Python获取基金网站网页内容、使用BeautifulSoup库分析html操作示例
本文实例讲述了Python获取基金网站网页内容.使用BeautifulSoup库分析html操作.分享给大家供大家参考,具体如下: 利用 urllib包 获取网页内容 #引入包 from urllib.request import urlopen response = urlopen("http://fund.eastmoney.com/fund.html") html = response.read(); #这个网页编码是gb2312 #print(html.decode("
-
Python利用PyExecJS库执行JS函数的案例分析
在Web渗透流程的暴力登录场景和爬虫抓取场景中,经常会遇到一些登录表单用DES之类的加密方式来加密参数,也就是说,你不搞定这些前端加密,你的编写的脚本是不可能Login成功的.针对这个问题,现在有三种解决方式: ①看懂前端的加密流程,然后用脚本编写这些方法(或者找开源的源码),模拟这个加密的流程.缺点是:不懂JS的话,看懂的成本就比较高了: ②selenium + Chrome Headless.缺点是:因为是模拟点击,所以效率相对①.③低一些: ③使用语言调用JS引擎来执行JS函数.缺点是
-
python字典和json.dumps()的遇到的坑分析
最近项目中需要与管易云erp做对接,看了他的接口文档,php的示例代码,于是用python仿写. 其中传的参数data中前面几个json数据是固定的,最后需要加一个签名,该签名是对前面的json数据字符串化后,首尾拼接上screct字符串,再做md5处理(32位大写),再将该签名添加到之前的json中作为post参数传递过去. 问题就出在组装json字符串和签名中,因为python内置的字典是无序的,导致我组装好的json数据作为参数传递给自己编写的签名函数时,字典内部的顺序是变化的,所以签名前
-
python爬取晋江文学城小说评论(情绪分析)
1. 收集数据 1.1 爬取晋江文学城收藏排行榜前50页的小说信息 获取收藏榜前50页的小说列表,第一页网址为 'http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&pa
-
python树莓派通过队列实现进程交互的程序分析
写在前面 现在购物车有一任务需求,那就是需要进行图像识别和运动控制,因此需要初始化2个进程,从而分别完成相应的动作.因为运动控制需要图像识别的结果,因此现在就涉及到了python语法实现2个进程之间的协同合作,这篇博客就结合实际的python程序通过队列实现进程交互通过队列实现进程交互. 程序分析 首先介绍一下我们的需要的库函数: import time from multiprocessing import Process, Queue from multiprocessing import
-
Python利用Charles 实现全部自动答题思路流程分析
利用Charles 达成"我是达人"答题类爆破思路 最近公司需要使用"我是答题"小程序,对武汉疫情进行知识问题:榜单靠前的也有一定的学分奖励:虽然平时总不屑于公司组织的此类活动,但是看了这次活动形式,还是决定直接"爆破 0x01 思路18年大火的直播答题中,对某答题app也进行了类似爆破,并薅了不少羊毛,到了后期已经做到了全自动化的答题,并且是100%正确正常情况下小程序和服务端通信流程 使用charles对请求进行串改流程 因为我的主力电脑就是MacOS
-
python http服务flask架构实用代码详解分析
依赖库 flask安装,使用豆瓣源加速. pip install flask -i https://pypi.douban.com/simple gevent安装,使用豆瓣源加速. pip install gevent -i https://pypi.douban.com/simple 代码 #!/user/bin/env python # coding=utf-8 """ @project : TestDemo @author : huyi @file : app.py @
-
python调用DLL与EXE文件截屏对比分析
目录 一.对比如下 二.综合选择 三.其它说明 想弄个截屏工具,整理一下学生错题什么的,原来用的方法是:先运行QQ,再监听键盘热键("ctrl+alt+a").后来发现有些问题:需要先上QQ,不能单独实现:监听时挂起, 查看增加了多个线程:键盘鼠标同时监听有难度,时间进度不好把握.现附加一个DLL文件,实现随时调用.网上查了一把,找到了几个可用文件. 一.对比如下 1.txgymailcamera.dll,文件大小:256K,界面友好,无放大镜. 2.cameradll.dll,文件大