python 爬取马蜂窝景点翻页文字评论的实现
使用Chrome、python3.7、requests库和VSCode进行爬取马蜂窝黄鹤楼的文字评论(http://www.mafengwo.cn/poi/5426285.html)。
首先,我们复制一段评论,查看网页源代码,按Ctrl+F查找,发现没有找到评论,说明评论内容不在http://www.mafengwo.cn/poi/5426285.html页面。

回到页面,划到评论列表,右键检查,选择Network,然后点击后一页翻页,观察Network里的变化,我们要爬的文件就在下面的某个文件里(主要找XHR和JS两个模块)。选择Preview可以更好的让我们寻找我们想要的文件,然后选择Headers找到我们要爬的url。
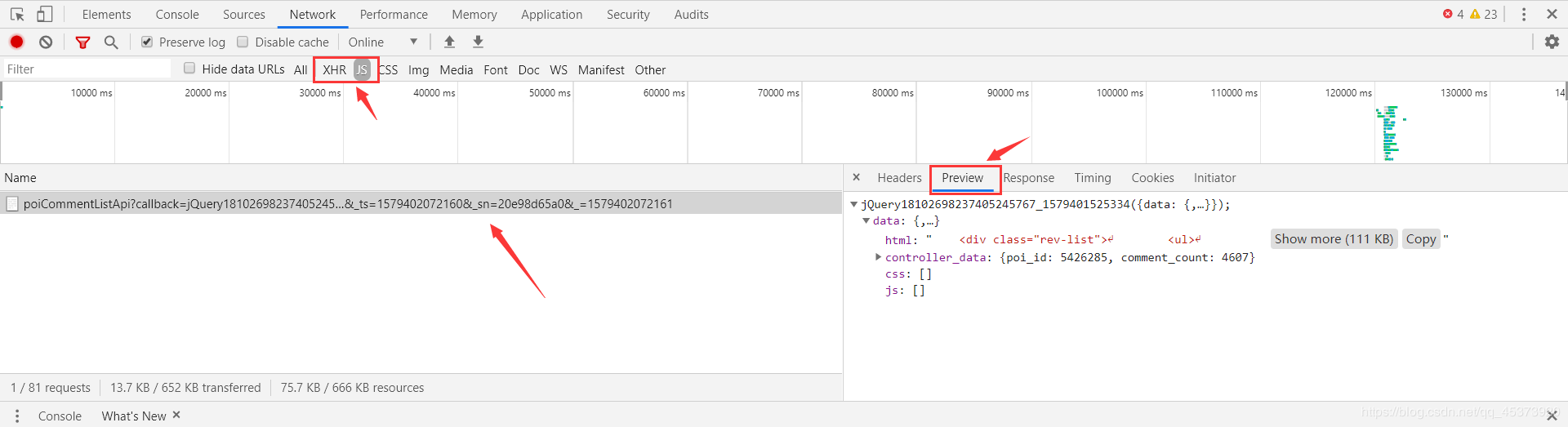
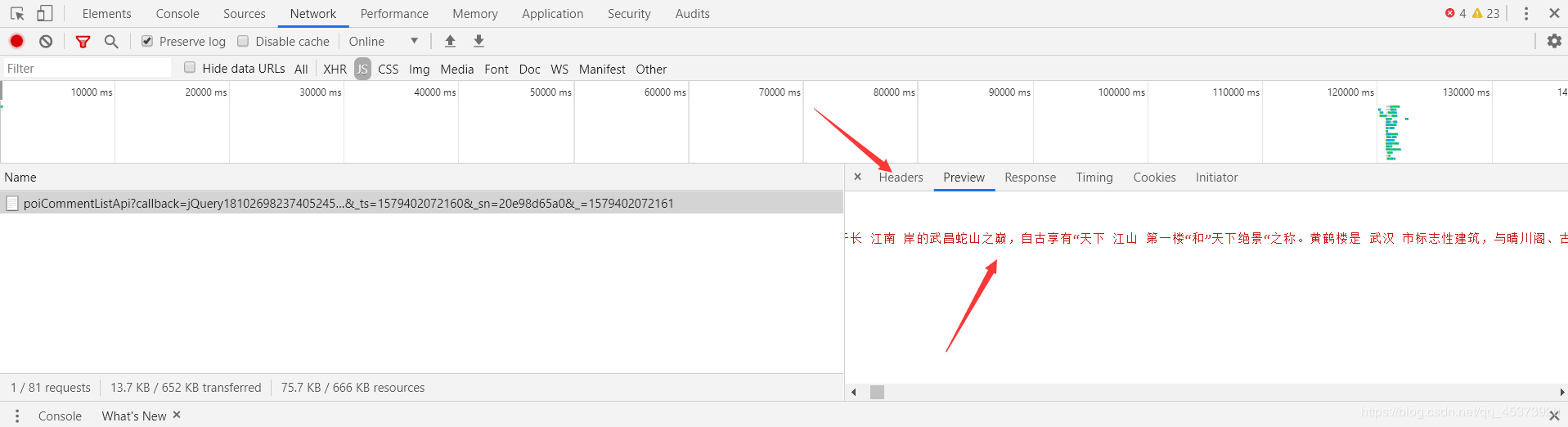
经过分析我们找到要爬取的url是http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?callback=jQuery18102698237405245767_1579401525334¶ms=%7B%22poi_id%22%3A%225426285%22%2C%22page%22%3A2%2C%22just_comment%22%3A1%7D&_ts=1579402072160&sn=20e98d65a0&=1579402072161
然而点进去是这样的

这个时候对比一下这两个页面的Request Headers,发现原页面多了个Refer参数
原页面


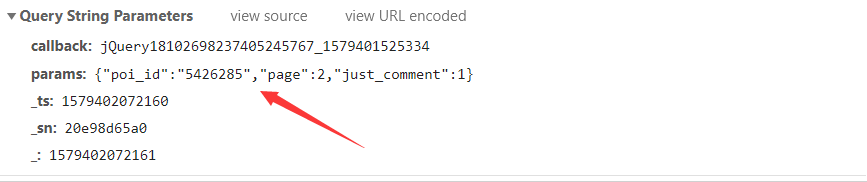
然后看一下请求get请求需要的参数Query String Parameters,其中poi_id是景点id,page是评论页面(翻页只用改变page的值就行)。
import re
import time
import requests
#评论内容所在的url,?后面是get请求需要的参数内容
comment_url='http://pagelet.mafengwo.cn/poi/pagelet/poiCommentListApi?'
requests_headers={
'Referer': 'http://www.mafengwo.cn/poi/5426285.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}#请求头
for num in range(1,6):
requests_data={
'params': '{"poi_id":"5426285","page":"%d","just_comment":1}' % (num) #经过测试只需要用params参数就能爬取内容
}
response =requests.get(url=comment_url,headers=requests_headers,params=requests_data)
if 200==response.status_code:
page = response.content.decode('unicode-escape', 'ignore').encode('utf-8', 'ignore').decode('utf-8')#爬取页面并且解码
page = page.replace('\\/', '/')#将\/转换成/
#日期列表
date_pattern = r'<a class="btn-comment _j_comment" title="添加评论">评论</a>.*?\n.*?<span class="time">(.*?)</span>'
date_list = re.compile(date_pattern).findall(page)
#星级列表
star_pattern = r'<span class="s-star s-star(\d)"></span>'
star_list = re.compile(star_pattern).findall(page)
#评论列表
comment_pattern = r'<p class="rev-txt">([\s\S]*?)</p>'
comment_list = re.compile(comment_pattern).findall(page)
for num in range(0, len(date_list)):
#日期
date = date_list[num]
#星级评分
star = star_list[num]
#评论内容,处理一些标签和符号
comment = comment_list[num]
comment = str(comment).replace(' ', '')
comment = comment.replace('<br>', '')
comment = comment.replace('<br />', '')
print(date+"\t"+star+"\t"+comment)
else:
print("爬取失败")
结果

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python爬取网易云音乐热门评论
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧.获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据.但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据.那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据.利用计算机的高效,我们可以轻松快速地获取数据. 那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,py
-
详解用python写网络爬虫-爬取新浪微博评论
新浪微博需要登录才能爬取,这里使用m.weibo.cn这个移动端网站即可实现简化操作,用这个访问可以直接得到的微博id. 分析新浪微博的评论获取方式得知,其采用动态加载.所以使用json模块解析json代码 单独编写了字符优化函数,解决微博评论中的嘈杂干扰字符 本函数是用python写网络爬虫的终极目的,所以采用函数化方式编写,方便后期优化和添加各种功能 # -*- coding:gbk -*- import re import requests import json from lxml im
-
用Python爬取QQ音乐评论并制成词云图的实例
环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例. 第一步:获取评论 我们先打开QQ音乐,搜索周杰伦的<等你下课>,直接拉到底部,发现有5000多页的评论. 这时候我们要研究的就是怎样获取每页的评论,这时候我们可以先按下F12,选择NetWork,我们可以先点击小红点清空数据,然后再点击一次,开始监控,然后点击下一页,看每次获取评论的时候访问获取的是哪几条数据.最后我们就能看到下图
-
Python爬取腾讯视频评论的思路详解
一.前提条件 安装了Fiddler了(用于抓包分析) 谷歌或火狐浏览器 如果是谷歌浏览器,还需要给谷歌浏览器安装一个SwitchyOmega插件,用于代理服务器 有Python的编译环境,一般选择Python3.0及以上 声明:本次爬取腾讯视频里 <最美公里>纪录片的评论.本次爬取使用的浏览器是谷歌浏览器 二.分析思路 1.分析评论页面 根据上图,我们可以知道:评论使用了Ajax异步刷新技术.这样就不能使用以前分析当前页面找出规律的手段了.因为展示的页面只有部分评论,还有大量的评论没有被刷新出
-
python爬虫 2019中国好声音评论爬取过程解析
2019中国好声音火热开播,作为一名"假粉丝",这一季每一期都刷过了,尤其刚播出的第六期开始正式的battle.视频视频看完了,那看下大家都是怎样评论的. 1.网页分析部分 本文爬取的是腾讯视频评论,第六期的评论地址是:http://coral.qq.com/4093121984 每页有10条评论,点击"查看更多评论",可将新的评论加载进来,通过多次加载,可以发现我们要找的评论就在以v2开头的js类型的响应中. 请求为GET请求,地址是http://coral.qq
-
Python实现的爬取网易动态评论操作示例
本文实例讲述了Python实现的爬取网易动态评论操作.分享给大家供大家参考,具体如下: 打开网易的一条新闻的源代码后,发现并没有所要得评论内容. 经过学习后发现,源代码只是一个完整页面的"骨架",而我所需要的内容是它的填充物,这时候需要打开工具里面的开发人员工具,从加载的"骨肉"里找到我所要的评论 圈住的是类型 找到之后打开网页,发现json类型的格式,用我已学过的正则,bs都不好闹,于是便去了解了正则,发现把json的格式换化成python的格式后,用列表提取内容
-
python制作爬虫爬取京东商品评论教程
本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化.下面是要抓取的商品信息,一款女士文胸.这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论. 京东商品评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论的信息.因此我们需要先找到存放商品评论信息的文件.这里我们使用Chrome浏览器里的开发者工具进行查找. 具体方法是在商品详情页点击鼠标右键,选择检查,在弹出的开发者工具界
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
python 爬取马蜂窝景点翻页文字评论的实现
使用Chrome.python3.7.requests库和VSCode进行爬取马蜂窝黄鹤楼的文字评论(http://www.mafengwo.cn/poi/5426285.html). 首先,我们复制一段评论,查看网页源代码,按Ctrl+F查找,发现没有找到评论,说明评论内容不在http://www.mafengwo.cn/poi/5426285.html页面. 回到页面,划到评论列表,右键检查,选择Network,然后点击后一页翻页,观察Network里的变化,我们要爬的文件就在下面的某个文件
-
python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
python根据用户需求输入想爬取的内容及页数爬取图片方法详解
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数. 主要步骤: 1.提示用户输入爬取的内容及页码. 2.根据用户输入,获取网址列表. 3.模拟浏览器向服务器发送请求,获取响应. 4.利用xpath方法找到图片的标签. 5.保存数据. 代码用面向过程的形式编写的. 关键字:requests库,xpath,面向过程 现在就来讲解代码书写的过程: 1.导入模块 import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配 import req
-
python爬取分析超级大乐透历史开奖数据第1/2页
博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取 爬取网站:http://datachart.500.com/dlt/history/history.shtml -500彩票网 (分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页) 如图: 爬虫部分: from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #
-
python爬取气象台每日天气图代码
目录 前言 1.安装Selenium 2. 安装chromedriver 3.代码 前言 中央气象台网站更新后,以前的爬虫方式就不太能用了,我研究了一下发现主要是因为网站上天气图的翻页模式从点击变成了滑动,页面上的图片src也只显示当前页面的,因此,按照网络通俗的方法去爬取就只能爬出一张图片.看了一些大佬的教程后自己改出来一个代码. 1.安装Selenium Selenium是一个Web的自动化(测试)工具,它可以根据我们的指令,让浏览器执行自动加载页面,获取需要的数据等操作. pip inst
-
详解Python 爬取13个旅游城市,告诉你五一大家最爱去哪玩?
今年五一放了四天假,很多人不再只是选择周边游,因为时间充裕,选择了稍微远一点的景区,甚至出国游.各个景点成了人山人海,拥挤的人群,甚至去卫生间都要排队半天,那一刻我突然有点理解灭霸的行为了. 今天通过分析去哪儿网部分城市门票售卖情况,简单的分析一下哪些景点比较受欢迎,等下次假期可以做个参考. 抓取数据 通过请求https://piao.qunar.com/ticket/list.htm?keyword=北京,获取北京地区热门景区信息,再通过BeautifulSoup去分析提取出我们需要的信息.
-
详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
Python爬取网页信息的示例
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初始网址,逐层查找链接,直到找到需要获取的内容. 在打开的界面中,点击鼠标右键,在弹出的对话框中,选择"检查",则在界面会显示该网页的源代码,在具体内容处点击查找,可以定位到需要查找的内容的源码. 注意:代码显示的方式与浏览器有关,有些浏览器不支持显示源代码功能(360浏览器,谷歌浏览器,火
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
教你怎么用python爬取爱奇艺热门电影
一.首先我们要找到目标 找到目标先分析一下网页(url:https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi–.html),很幸运这个只有一个网页,不需要翻页. 二.F12查看网页源代码 找到目标,分析如何获取需要的数据.找到href与电影名称 三.进行代码实现,获取想要资源. ''' 爬取爱奇艺电影与地址路径 操作步骤 1,获取到url内容 2,css选择其选择内容 3,保存自己需要数据 ''' #导入爬虫需要的包 import requ