Python3标准库之threading进程中管理并发操作方法
1. threading进程中管理并发操作
threading模块提供了管理多个线程执行的API,允许程序在同一个进程空间并发的运行多个操作。
1.1 Thread对象
要使用Thread,最简单的方法就是用一个目标函数实例化一个Thread对象,并调用start()让它开始工作。
import threading
def worker():
"""thread worker function"""
print('Worker')
threads = []
for i in range(5):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
输出有5行,每一行都是"Worker"。

如果能够创建一个线程,并向它传递参数告诉它要完成什么工作,那么这会很有用。任何类型的对象都可以作为参数传递到线程。下面的例子传递了一个数,线程将打印出这个数。
import threading
def worker(num):
"""thread worker function"""
print('Worker: %s' % num)
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
现在这个整数参数会包含在各线程打印的消息中。

1.2 确定当前线程
使用参数来标识或命名线程很麻烦,也没有必要。每个Thread实例都有一个带有默认值的名,该默认值可以在创建线程时改变。如果服务器进程中有多个服务线程处理不同的操作,那么在这样的服务器进程中,对线程命名就很有用。
import threading import time def worker(): print(threading.current_thread().getName(), 'Starting') time.sleep(0.2) print(threading.current_thread().getName(), 'Exiting') def my_service(): print(threading.current_thread().getName(), 'Starting') time.sleep(0.3) print(threading.current_thread().getName(), 'Exiting') t = threading.Thread(name='my_service', target=my_service) w = threading.Thread(name='worker', target=worker) w2 = threading.Thread(target=worker) # use default name w.start() w2.start() t.start()
调试输出的每一行中包含有当前线程的名。线程名列中有"Thread-1"的行对应未命名的线程w2。

大多数程序并不使用print来进行调试。logging模块支持将线程名嵌入到各个日志消息中(使用格式化代码%(threadName)s)。通过把线程名包含在日志消息中,就能跟踪这些消息的来源。
import logging
import threading
import time
def worker():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def my_service():
logging.debug('Starting')
time.sleep(0.3)
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='[%(levelname)s] (%(threadName)-10s) %(message)s',
)
t = threading.Thread(name='my_service', target=my_service)
w = threading.Thread(name='worker', target=worker)
w2 = threading.Thread(target=worker) # use default name
w.start()
w2.start()
t.start()
而且logging是线程安全的,所以来自不同线程的消息在输出中会有所区分。

1.3 守护与非守护线程
到目前为止,示例程序都在隐式地等待所有线程完成工作之后才退出。不过,程序有时会创建一个线程作为守护线程(daemon),这个线程可以一直运行而不阻塞主程序退出。
如果一个服务不能很容易地中断线程,或者即使让线程工作到一半时中止也不会造成数据损失或破坏(例如,为一个服务监控工具生成“心跳”的线程),那么对于这些服务,使用守护线程就很有用。要标志一个线程为守护线程,构造线程时便要传入daemon=True或者要调用它的setDaemon()方法并提供参数True。默认情况下线程不作为守护线程。
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
这个代码的输出中不包含守护线程的“Exiting“消息,因为在从sleep()调用唤醒守护线程之前,所有非守护线程(包括主线程)已经退出。

要等待一个守护线程完成工作,需要使用join()方法。
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join()
t.join()
使用join()等待守护线程退出意味着它有机会生成它的"Exiting"消息。

默认地,join()会无限阻塞。或者,还可以传入一个浮点值,表示等待线程在多长时间(秒数)后变为不活动。即使线程在这个时间段内未完成,join()也会返回。
import threading
import time
import logging
def daemon():
logging.debug('Starting')
time.sleep(0.2)
logging.debug('Exiting')
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
d = threading.Thread(name='daemon', target=daemon, daemon=True)
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join(0.1)
print('d.isAlive()', d.isAlive())
t.join()
由于传人的超时时间小于守护线程睡眠的时间,所以join()返回之后这个线程仍是"活着"。

1.4 枚举所有线程
没有必要为所有守护线程维护一个显示句柄来确保它们在退出主进程之前已经完成。
enumerate()会返回活动 Thread实例的一个列表。这个列表也包括当前线程,由于等待当前线程终止(join)会引入一种死锁情况,所以必须跳过。
import random
import threading
import time
import logging
def worker():
"""thread worker function"""
pause = random.randint(1, 5) / 10
logging.debug('sleeping %0.2f', pause)
time.sleep(pause)
logging.debug('ending')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
for i in range(3):
t = threading.Thread(target=worker, daemon=True)
t.start()
main_thread = threading.main_thread()
for t in threading.enumerate():
if t is main_thread:
continue
logging.debug('joining %s', t.getName())
t.join()
由于工作线程睡眠的时间量是随机的,所以这个程序的输出可能有变化。

1.5 派生线程
开始时,Thread要完成一些基本初始化,然后调用其run()方法,这会调用传递到构造函数的目标函数。要创建Thread的一个子类,需要覆盖run()来完成所需的工作。
import threading
import logging
class MyThread(threading.Thread):
def run(self):
logging.debug('running')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
for i in range(5):
t = MyThread()
t.start()
run()的返回值将被忽略。

由于传递到Thread构造函数的args和kwargs值保存在私有变量中(这些变量名都有前缀),所以不能很容易地从子类访问这些值。要向一个定制的线程类型传递参数,需要重新定义构造函数,将这些值保存在子类可见的一个实例属性中。
import threading
import logging
class MyThreadWithArgs(threading.Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
super().__init__(group=group, target=target, name=name,
daemon=daemon)
self.args = args
self.kwargs = kwargs
def run(self):
logging.debug('running with %s and %s',
self.args, self.kwargs)
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
for i in range(5):
t = MyThreadWithArgs(args=(i,), kwargs={'a': 'A', 'b': 'B'})
t.start()
MyThreadwithArgs使用的API与Thread相同,不过类似于其他定制类,这个类可以轻松地修改构造函数方法,以取得更多参数或者与线程用途更直接相关的不同参数。

1.6 定时器线程
有时出于某种原因需要派生Thread,Timer就是这样一个例子,Timer也包含在threading中。Timer在一个延迟之后开始工作,而且可以在这个延迟期间内的任意时刻被取消。
import threading
import time
import logging
def delayed():
logging.debug('worker running')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
t1 = threading.Timer(0.3, delayed)
t1.setName('t1')
t2 = threading.Timer(0.3, delayed)
t2.setName('t2')
logging.debug('starting timers')
t1.start()
t2.start()
logging.debug('waiting before canceling %s', t2.getName())
time.sleep(0.2)
logging.debug('canceling %s', t2.getName())
t2.cancel()
logging.debug('done')
这个例子中,第二个定时器永远不会运行,看起来第一个定时器在主程序的其余部分完成之后还会运行。由于这不是一个守护线程,所以在主线程完成时其会隐式退出。

1.7 线程间传送信号
尽管使用多线程的目的是并发地运行单独的操作,但有时也需要在两个或多个线程中同步操作。事件对象是实现线程间安全通信的一种简单方法。Event管理一个内部标志,调用者可以用set()和clear()方法控制这个标志。其他线程可以使用wait()暂停,直到这个标志被设置,可有效地阻塞进程直至允许这些线程继续。
import logging
import threading
import time
def wait_for_event(e):
"""Wait for the event to be set before doing anything"""
logging.debug('wait_for_event starting')
event_is_set = e.wait()
logging.debug('event set: %s', event_is_set)
def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
while not e.is_set():
logging.debug('wait_for_event_timeout starting')
event_is_set = e.wait(t)
logging.debug('event set: %s', event_is_set)
if event_is_set:
logging.debug('processing event')
else:
logging.debug('doing other work')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
e = threading.Event()
t1 = threading.Thread(
name='block',
target=wait_for_event,
args=(e,),
)
t1.start()
t2 = threading.Thread(
name='nonblock',
target=wait_for_event_timeout,
args=(e, 2),
)
t2.start()
logging.debug('Waiting before calling Event.set()')
time.sleep(0.3)
e.set()
logging.debug('Event is set')
wait()方法取一个参数,表示等待事件的时间(秒数),达到这个时间后就超时。它会返回一个布尔值,指示事件是否已设置,使调用者知道wait()为什么返回。可以对事件单独地使用is_set()方法而不必担心阻塞。
在这个例子中,wait_for_event_timeout()将检查事件状态而不会无限阻塞。wait_for_event()在wait()调用的位置阻塞,事件状态改变之前它不会返回。

1.8 控制资源访问
除了同步线程操作,还有一点很重要,要能够控制对共享资源的访问,从而避免破坏或丢失数据。Python的内置数据结构(列表、字典等)是线程安全的,这是Python使用原子字节码来管理这些数据结构的一个副作用(更新过程中不会释放保护Python内部数据结构的全局解释器锁GIL(Global Interpreter Lock))。Python中实现的其他数据结构或更简单的类型(如整数和浮点数)则没有这个保护。要保证同时安全地访问一个对象,可以使用一个Lock对象。
import logging
import random
import threading
import time
class Counter:
def __init__(self, start=0):
self.lock = threading.Lock()
self.value = start
def increment(self):
logging.debug('Waiting for lock')
self.lock.acquire()
try:
logging.debug('Acquired lock')
self.value = self.value + 1
finally:
self.lock.release()
def worker(c):
for i in range(2):
pause = random.random()
logging.debug('Sleeping %0.02f', pause)
time.sleep(pause)
c.increment()
logging.debug('Done')
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
counter = Counter()
for i in range(2):
t = threading.Thread(target=worker, args=(counter,))
t.start()
logging.debug('Waiting for worker threads')
main_thread = threading.main_thread()
for t in threading.enumerate():
if t is not main_thread:
t.join()
logging.debug('Counter: %d', counter.value)
在这个例子中,worker()函数使一个Counter实例递增,这个实例管理着一个Lock,以避免两个线程同时改变其内部状态。如果没有使用Lock,就有可能丢失一次对value属性的修改。

要确定是否有另一个线程请求这个锁而不影响当前线程,可以向acquire()的blocking参数传入False。在下一个例子中,worker()想要分别得到3次锁,并统计为得到锁而尝试的次数。与此同时,lock_holder()在占有和释放锁之间循环,每个状态会短暂暂停,以模拟负载情况。
import logging
import threading
import time
def lock_holder(lock):
logging.debug('Starting')
while True:
lock.acquire()
try:
logging.debug('Holding')
time.sleep(0.5)
finally:
logging.debug('Not holding')
lock.release()
time.sleep(0.5)
def worker(lock):
logging.debug('Starting')
num_tries = 0
num_acquires = 0
while num_acquires < 3:
time.sleep(0.5)
logging.debug('Trying to acquire')
have_it = lock.acquire(0)
try:
num_tries += 1
if have_it:
logging.debug('Iteration %d: Acquired',
num_tries)
num_acquires += 1
else:
logging.debug('Iteration %d: Not acquired',
num_tries)
finally:
if have_it:
lock.release()
logging.debug('Done after %d iterations', num_tries)
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
lock = threading.Lock()
holder = threading.Thread(
target=lock_holder,
args=(lock,),
name='LockHolder',
daemon=True,
)
holder.start()
worker = threading.Thread(
target=worker,
args=(lock,),
name='Worker',
)
worker.start()
worker()需要超过3次迭代才能得到3次锁。

1.8.1 再入锁
正常的Lock对象不能请求多次,即使是由同一个线程请求也不例外。如果同一个调用链中的多个函数访问一个锁,则可能会产生我们不希望的副作用。
import threading
lock = threading.Lock()
print('First try :', lock.acquire())
print('Second try:', lock.acquire(0))
在这里,对第二个acquire()调用给定超时值为0,以避免阻塞,因为锁已经被第一个调用获得。

如果同一个线程的不同代码需要"重新获得"锁,那么在这种情况下要使用RLock。
import threading
lock = threading.RLock()
print('First try :', lock.acquire())
print('Second try:', lock.acquire(0))
与前面的例子相比,对代码唯一的修改就是用RLock替换Lock。

1.8.2 锁作为上下文管理器
锁实现了上下文管理器API,并与with语句兼容。使用with则不再需要显式地获得和释放锁。
import threading
import logging
def worker_with(lock):
with lock:
logging.debug('Lock acquired via with')
def worker_no_with(lock):
lock.acquire()
try:
logging.debug('Lock acquired directly')
finally:
lock.release()
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
lock = threading.Lock()
w = threading.Thread(target=worker_with, args=(lock,))
nw = threading.Thread(target=worker_no_with, args=(lock,))
w.start()
nw.start()
函数worker_with()和worker_no_with()用等价的方式管理锁。

1.9 同步线程
除了使用Event,还可以通过使用一个Condition对象来同步线程。由于Condition使用了一个Lock,所以它可以绑定到一个共享资源,允许多个线程等待资源更新。在下一个例子中,consumer()线程要等待设置了Condition才能继续。producer()线程负责设置条件,以及通知其他线程继续。
import logging
import threading
import time
def consumer(cond):
"""wait for the condition and use the resource"""
logging.debug('Starting consumer thread')
with cond:
cond.wait()
logging.debug('Resource is available to consumer')
def producer(cond):
"""set up the resource to be used by the consumer"""
logging.debug('Starting producer thread')
with cond:
logging.debug('Making resource available')
cond.notifyAll()
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
condition = threading.Condition()
c1 = threading.Thread(name='c1', target=consumer,
args=(condition,))
c2 = threading.Thread(name='c2', target=consumer,
args=(condition,))
p = threading.Thread(name='p', target=producer,
args=(condition,))
c1.start()
time.sleep(0.2)
c2.start()
time.sleep(0.2)
p.start()
这些线程使用with来获得与Condition关联的锁。也可以显式地使用acquire()和release()方法。

屏障(barrier)是另一种线程同步机制。Barrier会建立一个控制点,所有参与线程会在这里阻塞,直到所有这些参与“方”都到达这一点。采用这种方法,线程可以单独启动然后暂停,直到所有线程都准备好才可以继续。
import threading
import time
def worker(barrier):
print(threading.current_thread().name,
'waiting for barrier with {} others'.format(
barrier.n_waiting))
worker_id = barrier.wait()
print(threading.current_thread().name, 'after barrier',
worker_id)
NUM_THREADS = 3
barrier = threading.Barrier(NUM_THREADS)
threads = [
threading.Thread(
name='worker-%s' % i,
target=worker,
args=(barrier,),
)
for i in range(NUM_THREADS)
]
for t in threads:
print(t.name, 'starting')
t.start()
time.sleep(0.1)
for t in threads:
t.join()
在这个例子中,Barrier被配置为会阻塞线程,直到3个线程都在等待。满足这个条件时,所有线程被同时释放从而越过这个控制点。wait()的返回值指示了释放的参与线程数,可以用来限制一些线程做清理资源等动作。

Barrier的abort()方法会使所有等待线程接收一个BrokenBarrierError。如果线程在wait()上被阻塞而停止处理,这就允许线程完成清理工作。
import threading
import time
def worker(barrier):
print(threading.current_thread().name,
'waiting for barrier with {} others'.format(
barrier.n_waiting))
try:
worker_id = barrier.wait()
except threading.BrokenBarrierError:
print(threading.current_thread().name, 'aborting')
else:
print(threading.current_thread().name, 'after barrier',
worker_id)
NUM_THREADS = 3
barrier = threading.Barrier(NUM_THREADS + 1)
threads = [
threading.Thread(
name='worker-%s' % i,
target=worker,
args=(barrier,),
)
for i in range(NUM_THREADS)
]
for t in threads:
print(t.name, 'starting')
t.start()
time.sleep(0.1)
barrier.abort()
for t in threads:
t.join()
这个例子将Barrier配置为多加一个线程,即需要比实际启动的线程再多一个参与线程,所以所有线程中的处理都会阻塞。在被阻塞的各个线程中,abort()调用会产生一个异常。

1.10 限制资源的并发访问
有时可能需要允许多个工作线程同时访问一个资源,但要限制总数。例如,连接池支持同时连接,但数目可能是固定的,或者一个网络应用可能支持固定数目的并发下载。这些连接就可以使用Semaphore来管理。
import logging
import threading
import time
class ActivePool:
def __init__(self):
super(ActivePool, self).__init__()
self.active = []
self.lock = threading.Lock()
def makeActive(self, name):
with self.lock:
self.active.append(name)
logging.debug('Running: %s', self.active)
def makeInactive(self, name):
with self.lock:
self.active.remove(name)
logging.debug('Running: %s', self.active)
def worker(s, pool):
logging.debug('Waiting to join the pool')
with s:
name = threading.current_thread().getName()
pool.makeActive(name)
time.sleep(0.1)
pool.makeInactive(name)
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
pool = ActivePool()
s = threading.Semaphore(2)
for i in range(4):
t = threading.Thread(
target=worker,
name=str(i),
args=(s, pool),
)
t.start()
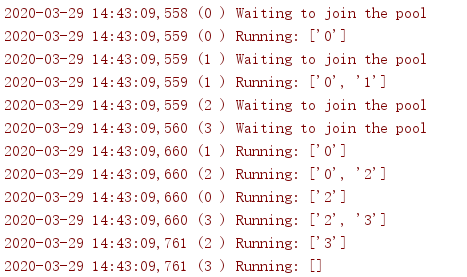
在这个例子中,ActivePool类只作为一种便利方法,用来跟踪某个给定时刻哪些线程能够运行。真正的资源池会为新的活动线程分配一个连接或另外某个值,并且当这个线程工作完成时再回收这个值。在这里,资源池只是用来保存活动线程的名,以显示至少有两个线程在并发运行。
1.11 线程特定的数据
有些资源需要锁定以便多个线程使用,另外一些资源则需要保护,以使它们对并非是这些资源的“所有者”的线程隐藏。local()函数会创建一个对象,它能够隐藏值,使其在不同线程中无法被看到。
import random
import threading
import logging
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
local_data = threading.local()
show_value(local_data)
local_data.value = 1000
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
属性local_data.value对所有线程都不可见,除非在某个线程中设置了这个属性,这个线程才能看到它。

要初始化设置以使所有线程在开始时都有相同的值,可以使用一个子类,并在_init_()中设置这些属性。
import random
import threading
import logging
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
class MyLocal(threading.local):
def __init__(self, value):
super().__init__()
logging.debug('Initializing %r', self)
self.value = value
logging.basicConfig(
level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
local_data = MyLocal(1000)
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
这会在相同的对象上调用_init_()(注意id()值),每个线程中调用一次以设置默认值。

总结
到此这篇关于Python3标准库:threading进程中管理并发操作的文章就介绍到这了,更多相关Python3标准库:threading进程中管理并发操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3标准库总结
Python3标准库 操作系统接口 os模块提供了不少与操作系统相关联的函数. >>> import os >>> os.getcwd() # 返回当前的工作目录 'C:\\Python34' >>> os.chdir('/server/accesslogs') # 修改当前的工作目录 >>> os.system('mkdir today') # 执行系统命令 mkdir 0 建议使用 "import os" 风格
-
Python标准库之Sys模块使用详解
sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分. 处理命令行参数 在解释器启动后, argv 列表包含了传递给脚本的所有参数, 列表的第一个元素为脚本自身的名称. 使用sys模块获得脚本的参数 复制代码 代码如下: print "script name is", sys.argv[0] # 使用sys.argv[0]采集脚本名称 if len(sys.argv) > 1: print "there are",
-
Python多进程并发(multiprocessing)用法实例详解
本文实例讲述了Python多进程并发(multiprocessing)用法.分享给大家供大家参考.具体分析如下: 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心. Python提供了非常好用的多进程包multiprocessing,你只需要定义一个函数,Python会替你完成其他所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换. 1.新建单一进程 如果我们新建少量进程,可以如下: import multiprocessing import t
-
Python常用的json标准库
当请求 headers 中,添加一个name为 Accept,值为 application/json 的 header(也即"我"(浏览器)接收的是 json 格式的数据),这样,向服务器请求返回的未必一定是 HTML 页面,也可能是 JSON 文档. 1. 数据交换格式 -- JSON(JavaScript Object Notation) http 1.1 规范 请求一个特殊编码的过程在 http1.1 规范中称为内容协商(content negotiation) JSON 特点
-
Python标准库sched模块使用指南
事件调度 sched 模块内容很简单,只定义了一个类.它用来最为一个通用的事件调度模块. class sched.scheduler(timefunc, delayfunc) 这个类定义了调度事件的通用接口,它需要外部传入两个参数, timefunc 是一个没有参数的返回时间类型数字的函数(常用使用的如time模块里面的time), delayfunc 应该是一个需要一个参数来调用.与timefunc的输出兼容.并且作用为延迟多个时间单位的函数(常用的如time模块的sleep). 下面是一个列
-
Python标准库shutil用法实例详解
本文实例讲述了Python标准库shutil用法.分享给大家供大家参考,具体如下: shutil模块提供了许多关于文件和文件集合的高级操作,特别提供了支持文件复制和删除的功能. 文件夹与文件操作 copyfileobj(fsrc, fdst, length=16*1024): 将fsrc文件内容复制至fdst文件,length为fsrc每次读取的长度,用做缓冲区大小 fsrc: 源文件 fdst: 复制至fdst文件 length: 缓冲区大小,即fsrc每次读取的长度 import shuti
-
Python标准库defaultdict模块使用示例
Python标准库中collections对集合类型的数据结构进行了很多拓展操作,这些操作在我们使用集合的时候会带来很多的便利,多看看很有好处. defaultdict是其中一个方法,就是给字典value元素添加默认类型,之前看到过但是没注意怎么使用,今天特地瞅了瞅. 首先是各大文章介绍的第一个例子: 复制代码 代码如下: import collections as coll def default_factory(): return 'default value' d =
-
python并发编程之多进程、多线程、异步和协程详解
最近学习python并发,于是对多进程.多线程.异步和协程做了个总结. 一.多线程 多线程就是允许一个进程内存在多个控制权,以便让多个函数同时处于激活状态,从而让多个函数的操作同时运行.即使是单CPU的计算机,也可以通过不停地在不同线程的指令间切换,从而造成多线程同时运行的效果. 多线程相当于一个并发(concunrrency)系统.并发系统一般同时执行多个任务.如果多个任务可以共享资源,特别是同时写入某个变量的时候,就需要解决同步的问题,比如多线程火车售票系统:两个指令,一个指令检查票是否卖完
-
python使用标准库根据进程名如何获取进程的pid详解
前言 标准库是Python的一个组成部分.这些标准库是Python为你准备好的利器,可以让编程事半功倍.特别是有时候需要获取进程的pid,但又无法使用第三方库的时候.下面话不多说了,来一起看看详细的介绍吧. 方法适用linux平台. 方法1 使用subprocess 的check_output函数执行pidof命令 from subprocess import check_output def get_pid(name): return map(int,check_output(["pidof&
-
Python3标准库之threading进程中管理并发操作方法
1. threading进程中管理并发操作 threading模块提供了管理多个线程执行的API,允许程序在同一个进程空间并发的运行多个操作. 1.1 Thread对象 要使用Thread,最简单的方法就是用一个目标函数实例化一个Thread对象,并调用start()让它开始工作. import threading def worker(): """thread worker function""" print('Worker') threads
-
Python3标准库之functools管理函数的工具详解
1. functools管理函数的工具 functools模块提供了一些工具来调整或扩展函数和其他callable对象,从而不必完全重写. 1.1 修饰符 functools模块提供的主要工具就是partial类,可以用来"包装"一个有默认参数的callable对象.得到的对象本身就是callable,可以把它看作是原来的函数.它与原函数的参数完全相同,调用时还可以提供额外的位置或命名函数.可以使用partial而不是lambda为函数提供默认参数,有些参数可以不指定. 1.1.1 部
-
Python3标准库之dbm UNIX键-值数据库问题
1. dbm UNIX键-值数据库 dbm是面向DBM数据库的一个前端,DBM数据库使用简单的字符串值作为键来访问包含字符串的记录.dbm使用whichdb()标识数据库,然后用适当的模块打开这些数据库.dbm还被用作shelve的一个后端,shelve使用pickle将对象存储在一个DBM数据库中. 1.1 数据库类型 Python提供了很多模块来访问DBM数据库.具体选择的默认实现取决于当前系统上可用的库以及编译Python时使用的选项.特定实现有单独的接口,这使得Python程序可以与用其
-
Python3标准库glob文件名模式匹配的问题
1. glob文件名模式匹配 尽管glob API很小,但这个模块的功能却很强大.只要程序需要查找文件系统中名字与某个模式匹配的一组文件,就可以使用这个模块.要创建一个文件名列表,要求其中各个文件名都有某个特定的扩展名.前缀或者中间都有某个共同的字符串,就可以使用glob而不用编写定制代码来扫描目录内容. glob的模式规则与re模块使用的正则表达式并不相同.实际上,glob的模式遵循标准UNIX路径扩展规则.只使用几个特殊字符来实现两个不同的通配符和字符区间.模式规则应用于文件名中的段(在路径
-
如何用tempfile库创建python进程中的临时文件
技术背景 临时文件在python项目中时常会被使用到,其作用在于随机化的创建不重名的文件,路径一般都是放在Linux系统下的/tmp目录.如果项目中并不需要持久化的存储一个文件,就可以采用临时文件的形式进行存储和读取,在使用之后可以自行决定是删除还是保留. tempfile库的使用 tempfile一般是python内置的一个函数库,不需要单独安装,这里我们直接介绍一下其常规使用方法: # tempfile_test.py import tempfile file = tempfile.Name
-
对python3标准库httpclient的使用详解
如下所示: import http.client, urllib.parse import http.client, urllib.parse import random USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; M
-
Qt动态库调用宿主进程中的对象方法纯虚函数使用
目录 引言 在运行时加载动态库并获取对象指针(QLibrary) 本贴重点:在动态库中调用宿主进程的对象方法 还是以add方法为例写一个Demo 引言 可执行程序加载动态库并调用动态库导出的函数是比较容易的: 导入库对应的头文件 在CPP文件中调用函数 在链接程序时加上动态库作为参数 假设demo.cpp中需要用到动态库libadd.so中的某个函数,可能是int add(int x, int y),那么我们编译时就需要链接上libadd.so, gcc参数中-L./libs指定了当前目录下的l
-

Python标准库之typing的用法(类型标注)
PEP 3107引入了功能注释的语法,PEP 484 加入了类型检查 标准库 typing 为类型提示指定的运行时提供支持. 示例: def f(a: str, b:int) -> str: return a * b 如果实参不是预期的类型: 但是,Python运行时不强制执行函数和变量类型注释.使用类型检查器,IDE,lint等才能帮助代码进行强制类型检查. 使用NewType 创建类型 NewType() 是一个辅助函数,用于向类型检查器指示不同的类型,在运行时,它返回一个函数,该函数返回其
-
从c++标准库指针萃取器谈一下traits技法(推荐)
本篇文章基于gcc中标准库源码剖析一下标准库中的模板类pointer_traits,并且以此为例理解一下traits技法. 说明一下,我用的是gcc7.1.0编译器,标准库源代码也是这个版本的. 还是先看一下思维导图,如下: 1. 指针萃取器pointer_traits说明 首先说明一下哈,官方并没有指针萃取器这个名称,其实pointer_traits是类模板,它是c++11以后引入的,可以通过传入的重绑定模板类型得到相应的指针类型,比较官方的描述是:pointer_traits 类模板提供标准