pandas进行数据输入和输出的方法详解
目录
- 1.文本格式数据的读写
- 1.1 分块读入文本文件
- 1.2 将数据写入文本格式
- 总结
1.文本格式数据的读写
read_csv():从文件、URL或文件型对象读取分隔好的数据,逗号是默认分隔符
read_table():从文件、URL或文件型对象读取分隔好的数据,制表符('\t')是默认分隔符
Windows用户打印文件的原始内容
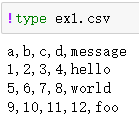
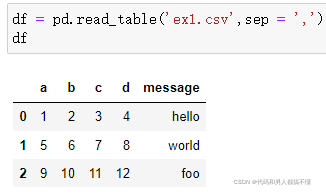
因为这个文件是逗号分隔的,我们可以使用read_csv将它读入一个DataFrame:

也可以用read_table,并指定分隔符
刚刚是文件包含表头行的情况,但有的文件并不包含表头行,比如
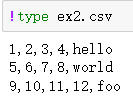
如果直接读取的话,默认将第一行作为表头了,也就是默认header=0,表示第一行为标题行。
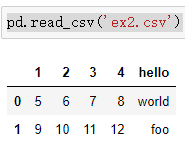
有两种方法改,
一是允许pandas自动分配默认列名,
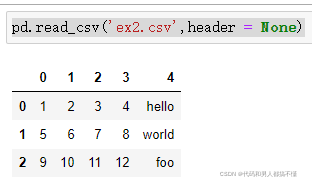
二是自己指定列名。
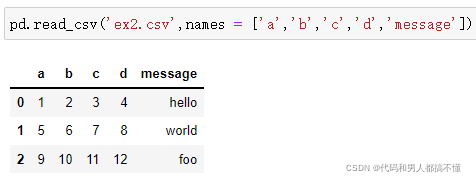
假设想要message列成为返回DataFrame的索引,可以指定位置4的列为索引,或将'message'传给参数index_col:
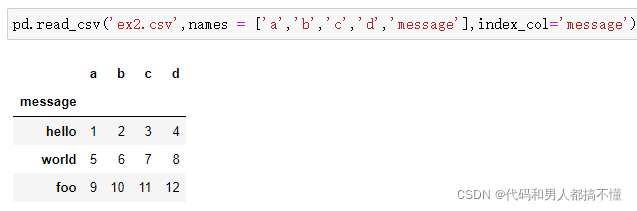
从多个列中形成一个分层索引

解析函数有很多附加参数处理各种发生异常的文件格式,例如,可以使用skiprows来跳过第一行,第三行,第四行。
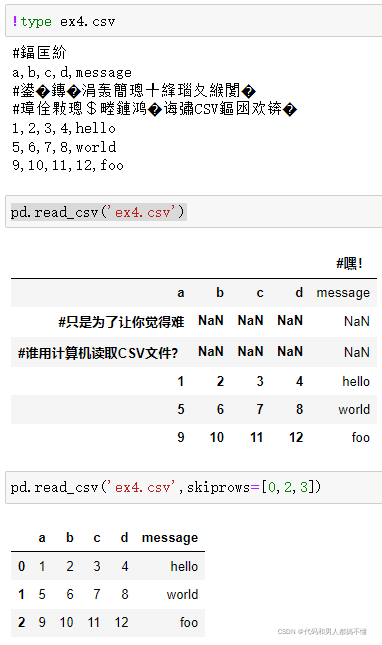
处理缺失值
通常情况下,缺失值要么不显示(空字符串,要么用一些标识值)
默认情况下,pandas用一些常见的标识,如NaN和NULL
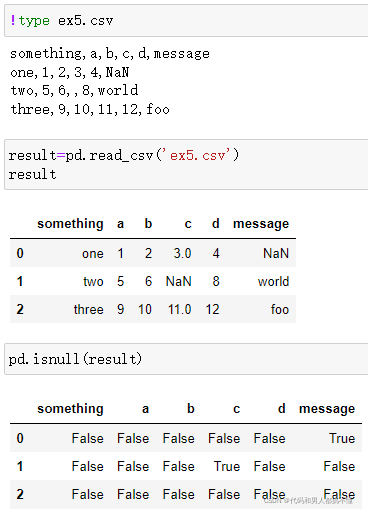
na_values选项可以传入一个列表或一组字符串来处理缺失值
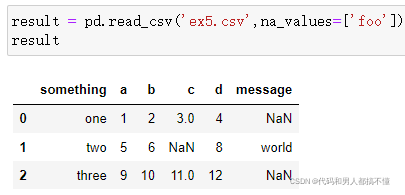
在字典中,每列可以指定不同的缺失值标识
1.1 分块读入文本文件
如果只想读取一小部分(避免读取整个文件),可以指明nrows

为了分块读入文件,可以指定chunksize作为每一块的行数
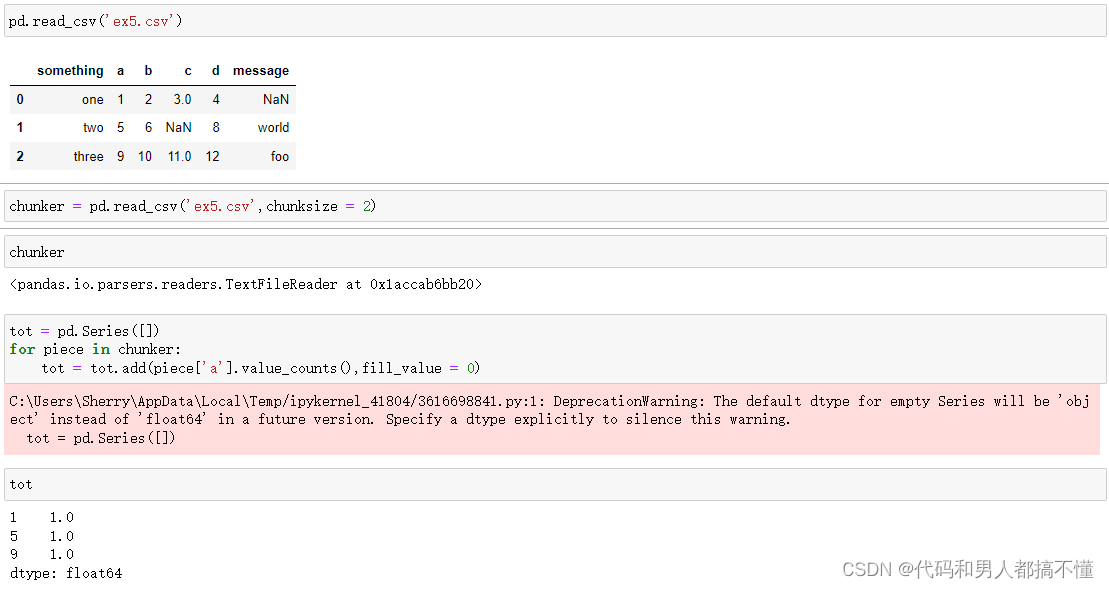
read_csv返回的TextParser对象允许根据chunksize遍历文件,并对'a'列聚合获得计数值
1.2 将数据写入文本格式
使用DataFrame的to_csv方法,可将数据导出为逗号分隔的文件
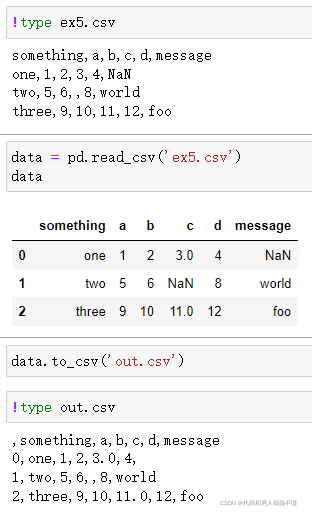
默认若是没有其他选项被指定的话,行和列的标签都会被写入,不过二者也都可以禁止写入
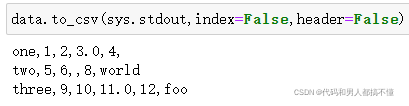
也可以仅仅写入列的子集,并且按照选择的顺序写入
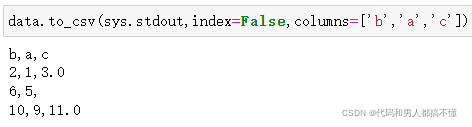
默认缺失值在输出时以空字符串出现,可以用其他标识值对缺失值进行标注
(写入到sys.stdout时,控制台中打印的文本结果)

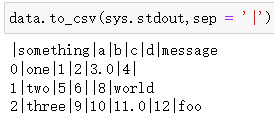
默认分隔符是逗号,可以用sep选项选择分隔符
Series也有to_csv方法
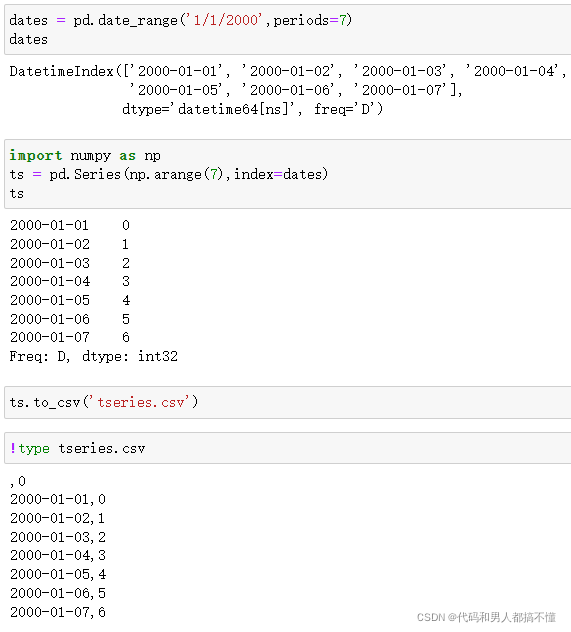
不知道为啥最后写入有,0这行????
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

pandas数据的合并与拼接的实现
目录 1. Merge方法 1.1 内连接 1.2 外连接 1.3 左连接 1.4 右连接 1.5 基于多列的连接算法 1.6 基于index的连接方法 2. join方法 3. concat方法 3.1 series类型的拼接方法 3.2 dataframe类型的拼接方法 4. 小结 Pandas包的merge.join.concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat
-
Pandas读取行列数据最全方法
1.读取方法有按行(单行,多行连续,多行不连续),按列(单列,多列连续,多列不连续):部分不连续行不连续列:按位置(坐标),按字符(索引):按块(list):函数有 df.iloc(), df.loc(), df.iat(), df.at(), df.ix(). 2.转换为DF,赋值columns,index,修改添加数据,取行列索引 data = {'省份': ['北京', '上海', '广州', '深圳'], '年份': ['2017', '2018', '2019', '2020'], '
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
利用pandas进行数据清洗的方法
目录 1.完整性 1.1 缺失值 1.2 空行 2.全面性 列数据的单位不统一 3.合理性 非ASCII字符 4.唯一性 4.1 一列有多个参数 4.2 重复数据 我们有下面的一个数据,利用其做简单的数据分析. 这是一家服装店统计的会员数据.最上面的一行是列坐标,最左侧一列是行坐标.列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸. 数据清洗规则总结为以下 4 个关键点
-
Python基础之pandas数据合并
一.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) axis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer 二.相同字段的表首尾相接 #现将表构成l
-
pandas进行数据输入和输出的方法详解
目录 1.文本格式数据的读写 1.1 分块读入文本文件 1.2 将数据写入文本格式 总结 1.文本格式数据的读写 read_csv():从文件.URL或文件型对象读取分隔好的数据,逗号是默认分隔符 read_table():从文件.URL或文件型对象读取分隔好的数据,制表符('\t')是默认分隔符 Windows用户打印文件的原始内容 因为这个文件是逗号分隔的,我们可以使用read_csv将它读入一个DataFrame: 也可以用read_table,并指定分隔符 刚刚是文件包含表头行的情况,但
-
js控制台输出的方法(详解)
console.log(object[, object, ...]) 在控制台输出一条消息.如果有多个参数,输出时会用空格隔开这些参数. 第一个参数可以是一个包含格式化占位符输出的字符串,例如: console.log("The %s jumped over %d tall buildings", animal, count); 上面的例子可以用下面的无格式化占位符输出的代码替换: console.log("The", animal, "jumped ov
-
对pandas通过索引提取dataframe的行方法详解
一.假设有这样一个原始dataframe 二.提取索引 (已经做了一些操作将Age为NaN的行提取出来并合并为一个dataframe,这里提取的是该dataframe的索引,道理和操作是相似的,提取的代码没有贴上去是为了不显得太繁杂让读者看着繁琐) >>> index = unknown_age_Mr.index.tolist() #记得转换为list格式 三.提取索引对应的原始dataframe的行 使用iloc函数将数据块提取出 >>> age_df.iloc[in
-
JS实现将数据导出到Excel的方法详解
修改之前项目代码的时候,发现前人导出excel是用纯javascript实现的.并没有调用后台接口. 之前从来没这么用过,记录一下.以备不时之需. 方法一: 将table标签,包括tr.td等对json数据进行拼接,将table输出到表格上实现,这种方法的弊端在于输出的是伪excel,虽说生成xls为后缀的文件,但文件形式上还是html,代码如下: <html> <head> <p style="font-size: 20px;color: red;&quo
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
对python3中, print横向输出的方法详解
Python 2 : print打印的时候,如果结尾有逗号,打出来时候不会换行.但是在python3里面就不行了. Python3 : 3.0的print最后加个参数end=""就可以了 以上这篇对python3中, print横向输出的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
SparkSQL读取hive数据本地idea运行的方法详解
环境准备: hadoop版本:2.6.5 spark版本:2.3.0 hive版本:1.2.2 master主机:192.168.100.201 slave1主机:192.168.100.201 pom.xml依赖如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="
-
python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
Python中json格式数据的编码与解码方法详解
本文实例讲述了Python中json格式数据的编码与解码方法.分享给大家供大家参考,具体如下: python从2.6版本开始内置了json数据格式的处理方法. 1.json格式数据编码 在python中,json数据格式编码使用json.dumps方法. #!/usr/bin/env python #coding=utf8 import json users = [{'name': 'tom', 'age': 22}, {'name': 'anny', 'age': 18}] #元组对象也可以
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基