python自动化测试之Selenium详解
目录
- 1.安装
- 2.基础操作
- 2.1声明浏览器对象
- 2.2访问网页
- 2.3查找单个节点
- 2.4查找多个节点
- 3.等待
- 3.1显式等待
- 3.2隐式等待
- 总结
1.安装
完成自动化测试,需要配置三个东西。
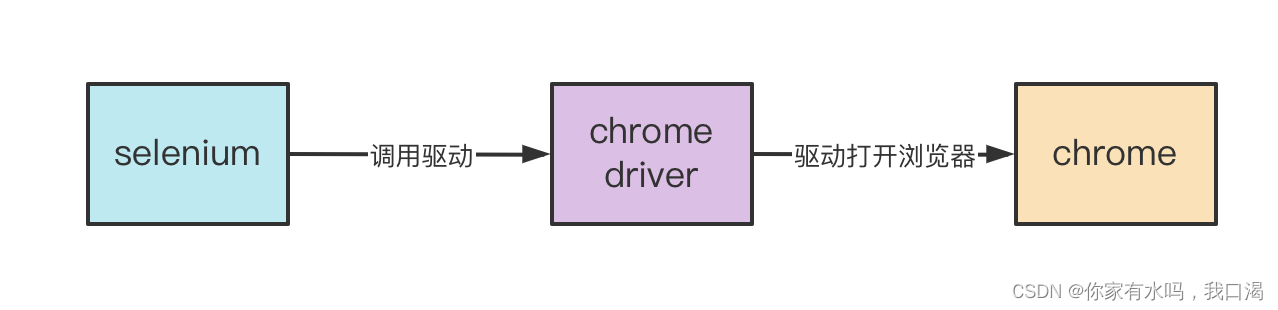
selenium:pip就可以了
chrome:浏览器下载一个谷歌浏览器就行
chrome-driver:下载地址http://chromedriver.storage.googleapis.com/index.html
从浏览器上下载到本地后,本机mac上自动保存至Download/目录下
但我们要把它转移到该去的地方
具体终端命令如下:
#目录到下载位置 cd Downloads/ #解压zip文件 unzip chromedriver_mac64.zip #拿到解压后文件Unix Executable类型文件后,移动它该去的位置 mv chromedriver /usr/local/bin/
2.基础操作
下面就来了解一下 Selenium 的一些基础操作把。先写一点简单的小功能演示一下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('杨幂')
input.send_keys(Keys.ENTER)
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
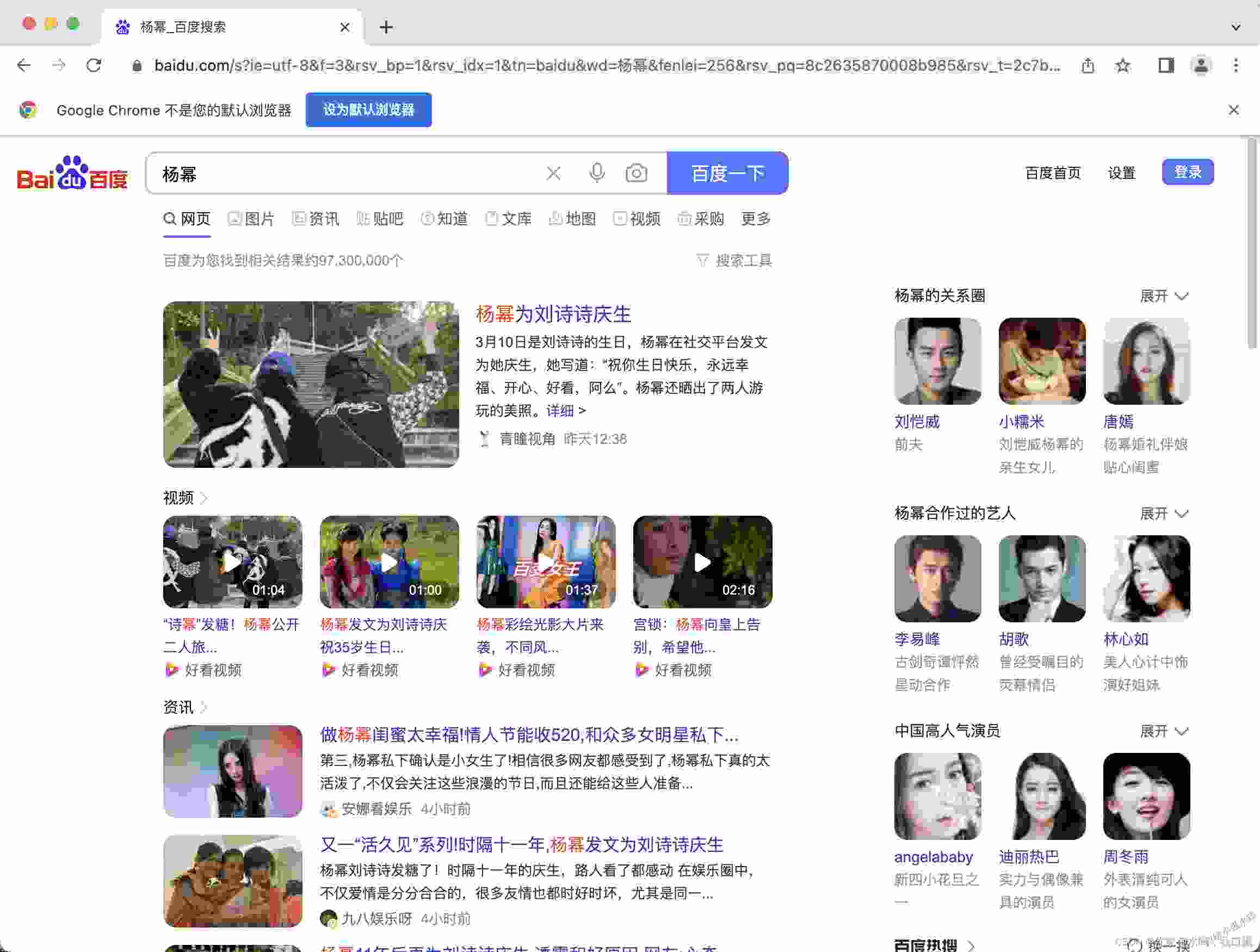
运行以上代码,可以看到自动弹出来一个 Chrome 浏览器,并且上面标示了: Chrome 正受到自动软件的控制 。然后打开了百度,在输入框中输入了 “杨幂” 进行搜索
2.1 声明浏览器对象
Selenium 支持非常多的浏览器,如:
from selenium import webdriver # 声明浏览器对象,需对应的驱动程序方可使用 browser = webdriver.android() browser = webdriver.blackberry() browser = webdriver.chrome() browser = webdriver.edge() browser = webdriver.firefox() browser = webdriver.ie() browser = webdriver.opera() browser = webdriver.phantomjs() browser = webdriver.safari()
可以看到有我熟悉的 IE 浏览器、 Edge 浏览器、 FireFox 浏览器、 Opera 浏览器等等。
2.2 访问网页
访问网页可以使用 get() 方法,参数传入我们想要访问的网站即可:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
print(browser.page_source)
通过上面两行代码,我们可以看到自动打开了浏览器并访问的京东,在控制台打印了京东的源代码。
当然,如果想要程序自动关闭浏览器的话可以使用:
browser.close()
2.3 查找单个节点
我们获取到网页后,第一步肯定是要先查找到 DOM 节点啊,然后可以直接从 DOM 节点中获取数据。
不过有了 Selenium 以后,我们不仅可以查找到节点获取数据,还可以模拟用户操作,比如在搜索框输入某些内容,点击按钮等等操作,不过还是先看看怎么查找节点:
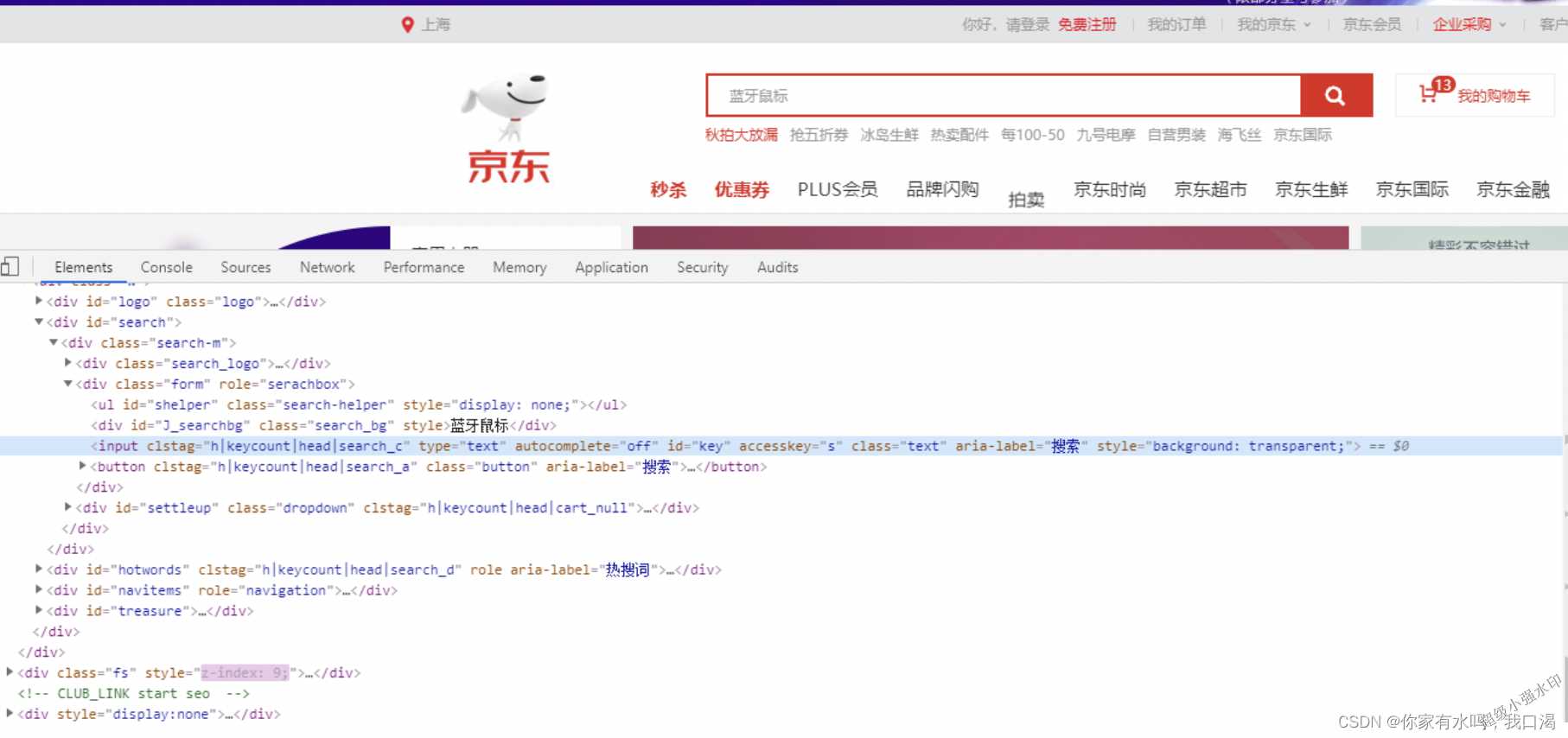
从上面这张图可以看到,我们想要获取输入框,可以通过 id 进行获取,那么我们接下来的代码要这么写:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
input_key = browser.find_element_by_id('key')
print(input_key)
结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="86d1ae1419bee22099a168dfbf921a27", element="53047804-ad39-4dfd-b3fb-a149fb1c8ac8")>
可以看到,我们获得的元素类型是 WebElement 。
这里顺手列出所有的获得单个节点的方法:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
此外, selenium 还未我们提供了一个通用方法 find_element() ,它需要传入两个参数:查找方式 By 和值。实际上上面示例中的查找方式还可以这么写(效果完全一样哦~~~)
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
input_key1 = browser.find_element(By.ID, 'key')
print(input_key1)
2.4 查找多个节点
比如我们要查找左边的这种导航条的所有条目:

可以这么写
lis = browser.find_elements_by_css_selector('.cate_menu li')
print(lis)
结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="6341ab4f39733b5f6b6bd51508b62f1d", element="8e0d1a8c-d5dc-4b1f-8250-7f0eca864ea7")>, <selenium.webdriver.remote.webelement.WebElement (session="6341ab4f39733b5f6b6bd51508b62f1d", element="15cd4dc9-42f4-4ed7-9258-9aa29073243c")>,
......]
下面列出来所有的多节点选择的方法:
find_elements_by_name find_elements_by_xpath find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name find_elements_by_css_selector
同样,多节点选择也有一个 find_elements() 的方法,
3.等待
如今,大多数 Web 应用程序都在使用 AJAX 技术。当浏览器加载页面时,该页面中的元素可能会以不同的时间间隔加载。这使定位元素变得困难:如果 DOM 中尚不存在元素,则定位函数将引发 ElementNotVisibleException 异常。使用等待,我们可以解决此问题。等待在执行的动作之间提供了一定的松弛时间-主要是定位元素或对该元素进行的任何其他操作。
Selenium Webdriver 提供两种类型的等待-隐式和显式。显式等待使 WebDriver 等待特定条件发生,然后再继续执行。隐式等待使 WebDriver 在尝试查找元素时轮询DOM一定时间。
3.1 显式等待
我们可以使用 time.sleep() 来设定等待时间,完全没有问题,但是它需要将条件设置为要等待的确切时间段。如果我们不知道准确的渲染时间,我们就无法设定一个比较合适的值。
Selenium 为我们提供了 WebDriverWait 与 ExpectedCondition 来完成这件事情,看代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://www.jd.com/")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "key"))
)
finally:
driver.quit()
结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="b1baacca997d18d7d54447127c844d15", element="a472369e-3196-4456-b43e-4e1b280bf5b9")>
上面我们使用了 WebDriverWait 来设置最长等待时间,这里我们选择获取 JD 首页的输入框,我们限定的等待时间为 10s ,如果它在 10s 内都无法返回结果,将会抛出 TimeoutException 。默认情况下, WebDriverWait 每 500 毫秒调用 ExpectedCondition ,直到成功返回。
3.2 隐式等待
隐式等待告诉 WebDriver 在尝试查找不立即可用的一个或多个元素时在一定时间内轮询 DOM 。默认设置为 0 。设置后,将在 WebDriver 对象的生存期内设置隐式等待。
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # seconds
driver.get("https://www.jd.com/")
key = driver.find_element_by_id("key")
print(key)
节点交互
Selenium 为我们提供了一些节点的交互动作,如输入文字时可以用 send_keys() 方法,清空文字时可以用 clear() 方法,点击按钮时可以用 click() 方法。
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('https://www.taobao.com/')
input = driver.find_element_by_id('q')
input.send_keys('IPad')
time.sleep(1)
input.clear()
input.send_keys('Surface Pro')
button = driver.find_element_by_class_name('btn-search')
button.click()
在上面这个示例中,我们先打开淘宝网,并且开启了隐式等待,先在搜索框中输入了 IPad ,在等待 1s 后删除,再输入了 Surface Pro ,然后点击了搜索按钮,先在淘宝搜索需要用户登录才能搜索,所以我们直接跳转到了登录页。
执行 JavaScript
对于某些 Selenium API 没有提供的操作,我们可以通过模拟运行 JavaScript 的方式来完成,用到的方法是 execute_script() ,比如我们在淘宝首页将滚动条滑到底部:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.taobao.com/')
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
获取信息
前面我们介绍了如何拿到 DOM 节点,那么最重要的是我们要从 DOM 节点上来获取我们需要的信息。
因为我们获取的是 WebElement 类型,而 WebElement 也提供了相关的方法来提取节点信息。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 实例化一个启动参数对象
chrome_options = Options()
# 设置浏览器窗口大小
chrome_options.add_argument('--window-size=1366, 768')
# 启动浏览器
driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://www.geekdigging.com/'
driver.get(url)
title = driver.find_element_by_xpath('//*[@id="text-4"]/div/div/div[1]/div[2]/a')
print(title)
# 获取属性信息
print(title.get_attribute('href'))
# 获取文本信息
print(title.text)
# 获取位置
print(title.location)
# 获取大小
print(title.size)
上面因为 Chrome 默认打开大小有点小,打开小编博客的时候小编选择的这个 DOM 节点正好看到,所以小编设置了一下 Chrome 浏览器打开时的大小。
具体信息的供大家参考:
- parent:查找到此元素的WebDriver实例的内部引用。
- rect:具有元素大小和位置的字典。
- screenshot_as_base64:以 base64 编码字符串的形式获取当前元素的屏幕快照。
- screenshot_as_png:以二进制数据获取当前元素的屏幕截图。最后这两个获取元素屏幕快照,在获取验证码的时候将验证码截取出来会很好用的。
前进和后退
我们使用浏览器最上面的地方有一个前进和后退按钮,Selenium 完成这两个动作使用了 back() 和 forward() 这两个方法。
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.geekdigging.com/')
browser.back()
time.sleep(1)
browser.forward()
Cookies
又到了一个重点内容, Cookies ,它是和服务端保持会话的一个重要元素。 Selenium 为我们提供了一些方法,让我们可以方便的对 Cookies 进行增删改查等操作。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.geekdigging.com/')
# 获取 cookies
print(browser.get_cookies())
# 添加一个 cookie
browser.add_cookie({'name': 'name', 'domain': 'www.geekdigging.com', 'value': 'geekdigging'})
print(browser.get_cookies())
# 删除所有 cookie
browser.delete_all_cookies()
print(browser.get_cookies())
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

详解Python Selenium如何获取鼠标指向的元素
有一个同学在Gne的群里面咨询如何通过Selenium获取当前鼠标指向的元素,在我讲了方法以后,他过了两天又来问: 那么,我今天就来写一篇文章,具体说说应该怎么操作. 这个方法的核心,是借助JavaScript的事件(event)来获取鼠标所在的元素.然后再把这个元素传递给Selenium.我们先来第一步,不考虑Selenium,只使用JavaScript,如何获取当前鼠标指向的元素呢? 我们首先需要知道在JavaScript中的一个事件句柄,叫做window.onmousemove.默认情况下
-
Python+Selenium实现读取网易邮箱验证码
前面写到了一些关于python+Selenium的基础操作 的教程,这篇文章将讲解一些实战内容. 在自动化工作中,有可能会遇到一些发送邮箱验证码类似的功能,如下 我们一般的解决思路就是 : 发送邮件—>打开邮箱—>输入邮箱账户密码—>登录邮箱—>打开未读邮件—>获取验证码—>保存验证码—>读取验证码 以下是一个实现打开网易邮箱读取未读邮件获取验证码的代码 def wangyi(self,username, password, name): dr = webdriv
-
Python+Selenium自动化环境搭建与操作基础详解
目录 一.环境搭建 1.python安装 2.pycharm下载安装 3.selenium下载安装 4.浏览器驱动下载安装 二.Selenium简介 (1)SeleniumIDE (2)SeleniumRC (3)SeleniumWebDriver (4)SeleniumGrid 三.常用方法 1.浏览器操作 2.如何获取页面元素 3.查找定位页面元素的方法 4.操作方法 5.下拉框操作 6.WINDOS弹窗 7.iframe内嵌页面处理 8.上传文件 9.切换页面 10.截图 11.等待时间
-
Python利用selenium建立代理ip池访问网站的全过程
目录 一.使用selenium前? 1.安装selenium 2.安装浏览器驱动 3.配置环境 二.使用selenium 1.引入库 2.完整代码 总结 一.使用selenium前? 1.安装selenium pip install Selenium 2.安装浏览器驱动 Chrome驱动文件下载:点击下载 3.配置环境 1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以 2.然后配置下系统变量:我的电脑–>属性–>系统设置
-
python单例模式之selenium driver实现单例
目录 一.使用装饰器实现单例 二.web自动化driver实现单例模式 2.1编写单例模式的装饰器 2.2driver使用装饰器,实现单例模式 2.3获取driver的实例,就是单例了 三.在自动化项目中具体的应用 3.1项目结构 四.工具层Utils 4.1singleton.py是单例装饰器 4.2GetSeleniumDriver.py driver实现单例 五.页面元素层TsetSharelab 六.流程层 七.case层,把业务逻辑组成一条条用例 一.使用装饰器实现单例 def Sin
-
python selenium中Excel数据维护指南
接着python里面的xlrd模块详解(一)中我们我们来举一个实例: 我们来举一个从Excel中读取账号和密码的例子并调用: ♦1.制作Excel我们要对以上输入的用户名和密码进行参数化,使得这些数据读取自Excel文件.我们将Excel文件命名为data.xlsx,其中有两列数据,第一列为username,第二列为password. ♦2.读取Excel代码如下 #-*- coding:utf-8 -*- import xlrd,time,sys,unittest #导入xlrd等相关模块 c
-
python自动化测试之Selenium详解
目录 1.安装 2.基础操作 2.1声明浏览器对象 2.2访问网页 2.3查找单个节点 2.4查找多个节点 3.等待 3.1显式等待 3.2隐式等待 总结 1.安装 完成自动化测试,需要配置三个东西. selenium:pip就可以了 chrome:浏览器下载一个谷歌浏览器就行 chrome-driver:下载地址http://chromedriver.storage.googleapis.com/index.html 从浏览器上下载到本地后,本机mac上自动保存至Download/目录下 但我
-
Python自动化测试利器selenium详解
目录 1 自动化测试 1.1 单元测试 1.2 接口测试 1.3 UI测试 1.3.1 UI自动化测试的优点 1.3.2 UI自动化测试的适用对象 1.4 自动化测试流程 2 selenium 3 selenium IDE 录制脚本 1 自动化测试 自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统,预设条件包括正常和异常,最后评估运行结果.将人为驱动的测试行为转化为机器执行的过程. 自动化测试包括UI自动化,接口自动化,单元测试自动化.按照这个金字塔模型来进行自动化测试规划,可以产
-
Angular.js自动化测试之protractor详解
前戏 面向模型编程: 测试驱动开发: 先保障交互逻辑,再调整细节.---by 雪狼. 为什么要自动化测试? 1,提高产出质量. 2,减少重构时的痛.反正我最近重构多了,痛苦经历多了. 3,便于新人接手. angular自动化测试主要分:端到端测试和单元测试,很明显两者都要熟练掌握. 端到端测试是从用户的角度出发,认为整个系统是个黑盒,只会有UI暴露给用户,主要是模仿人工操作测试. 单元测试认为整个系统是白盒,可以用来测试服务,控制器,过滤器还有基础函数等. 端到端测试使用protractor,今
-
Python自动化测试之异常处理机制实例详解
目录 一.前言 二.异常处理合集 2.1 异常处理讲解 2.2 异常捕获 2.3 异常捕获原理 2.4 特定异常捕获 2.5 异常捕获的处理 2.6 except.Exception与BaseException 2.7 finally用法 2.8 异常信息的打印输出 三.总结 一.前言 今天笔者还是想要讲python中的基础,主要讲解Python中异常介绍.捕获.处理相关知识点内容,只有学好了这些才能为后续自动化测试框架搭建及日常维护做铺垫,废话不多说我们直接进入主题吧. 二.异常处理合集 2.
-
Python Unittest自动化单元测试框架详解
本文实例为大家分享了Python Unittest自动化单元测试框架的具体代码,供大家参考,具体内容如下 1.python 测试框架(本文只涉及 PyUnit) 参考地址 2.环境准备 首先确定已经安装有Python,之后通过安装PyUnit,Python版本比较新的已经集成有PyUnit(PyUnit 提供了一个图形测试界面UnittestGUI.py) 参考:查看地址 3.代码实例 使用的IDE为 PyCharm,DEMO结构如图 1.简单地一个实例 # Test002_Fail.py #
-
selenium+python环境配置教程详解
一.安装Python 1)官网下载安装 2)配置环境变量(未勾选自动配置需要手动配置) 3)检查是否安装成功(交互窗口中输入Python -v) 二.Selenium 3.X +FireFox 驱动 +geckodriver 1.安装selenium: 1)W+r输入cmd,然后输入pip install selenium 2)安装FireFox,添加附加组件selenium IDE.FireBUG 3) https://github.com/mozilla/geckodriver/releas
-
Python Playwright的使用详解
目录 实战场景 实战操作 实战场景 本篇博客为大家介绍一款新的自动化测试工具,效果类似 selenium,但是这个模块年轻. 模块名称为 playwright-python,微软开源的,是针对 Python 语言的纯自动化工具,可以通过 API 调用浏览器,github 地址在本文末尾. 接下来将通过 3 篇博客为大家详细介绍该 playwright-python,彻彻底底了解它. 正式开始前依旧是模块安装: pip install playwright 该模块安装非常快,但完整体验还需要安装浏
-
Python自动化测试之登录脚本的实现
目录 环境准备 1.安装selenium模块 2.安装浏览器驱动器 代码 1.登录代码 2.xpath定位元素标签 环境准备 前提已经安装好python.pycharm,配置了对应的环境变量. 1.安装selenium模块 文件–>设置—>项目:script---->python解释器---->+selenium 2.安装浏览器驱动器 以谷歌浏览器为例下载地址:https://chromedriver.chromium.org/downloads(1)先查看谷歌浏览器版本:(2)下
-
Python ellipsis 的用法详解
背景 在 Python 的基本类型中单例模式的值有三个 None 类型的 None ,NotImplemented 类型的 NotImplemented, Ellipsis 类型的 ... . None 已经用的烂大街了,NotImplemented 也比较常用,唯独 ... 在江湖上只知它是三巨头之一,但不知其用法. Ellipsis Ellipsis 在 python 中代表"省略",用现在的流形语来表达就是"老铁,不要在意这些细节!".哪什么时候要告诉别人不要
-
Python批量操作Excel文件详解
目录 批量操作 OS模块介绍 OS模块基本操作 获取当前工作路径 获取一个文件夹下的所有文件名 对文件名进行重命名 创建一个文件夹 删除一个文件夹 删除一个文件 利用OS模块进行批量操作 批量读取一个文件下的多个文件 批量创建文件夹 批量重命名文件 其他批量操作 批量合并多个文件 将一份文件按照指定列拆分成多个文件 批量操作 OS模块介绍 OS的全称是Operation System,指操作系统.在Python里面OS模块中主要提供了与操作系统即电脑系统之间进行交互的一些功能.我们很多的自动化操