算法系列15天速成——第十五天 图【下】(大结局)
今天是大结局,说下“图”的最后一点东西,“最小生成树“和”最短路径“。
一: 最小生成树
1. 概念
首先看如下图,不知道大家能总结点什么。
对于一个连通图G,如果其全部顶点和一部分边构成一个子图G1,当G1满足:
① 刚好将图中所有顶点连通。②顶点不存在回路。则称G1就是G的“生成树”。
其实一句话总结就是:生成树是将原图的全部顶点以最小的边连通的子图,这不,如下的连通图可以得到下面的两个生成树。
② 对于一个带权的连通图,当生成的树不同,各边上的权值总和也不同,如果某个生成树的权值最小,则它就是“最小生成树”。
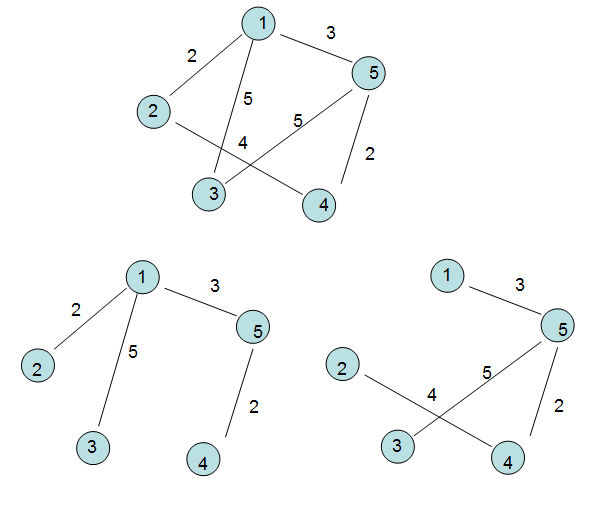
2. 场景
实际应用中“最小生成树”还是蛮有实际价值的,教科书上都有这么一句话,若用图来表示一个交通系统,每一个顶点代表一个城市,
边代表两个城市之间的距离,当有n个城市时,可能会有n(n-1)/2条边,那么怎么选择(n-1)条边来使城市之间的总距离最小,其实它
的抽象模型就是求“最小生成树”的问题。
3. prim算法
当然如何求“最小生成树”问题,前人都已经给我们总结好了,我们只要照葫芦画瓢就是了,
第一步:我们建立集合“V,U",将图中的所有顶点全部灌到V集合中,U集合初始为空。
第二步: 我们将V1放入U集合中并将V1顶点标记为已访问。此时:U(V1)。
第三步: 我们寻找V1的邻接点(V2,V3,V5),权值中发现(V1,V2)之间的权值最小,此时我们将V2放入U集合中并标记V2为已访问,
此时为U(V1,V2)。
第四步: 我们找U集合中的V1和V2的邻接边,一阵痉挛后,发现(V1,V5)的权值最小,此时将V5加入到U集合并标记为已访问,此时
U的集合元素为(V1,V2,V5)。
第五步:此时我们以(V1,V2,V5)为基准向四周寻找最小权值的邻接边,发现(V5,V4)的权值最小,此时将V4加入到U集合并标记
为已访问,此时U的集合元素为(V1,V2,V5,V4)。
第六步: 跟第五步形式一样,找到了(V1,V3)的权值最小,将V3加入到U集合中并标记为已访问,最终U的元素为(V1,V2,V5,V4,V3),
最终发现顶点全部被访问,最小生成树就此诞生。
#region prim算法获取最小生成树
/// <summary>
/// prim算法获取最小生成树
/// </summary>
/// <param name="graph"></param>
public void Prim(MatrixGraph graph, out int sum)
{
//已访问过的标志
int used = 0;
//非邻接顶点标志
int noadj = -1;
//定义一个输出总权值的变量
sum = 0;
//临时数组,用于保存邻接点的权值
int[] weight = new int[graph.vertexNum];
//临时数组,用于保存顶点信息
int[] tempvertex = new int[graph.vertexNum];
//取出邻接矩阵的第一行数据,也就是取出第一个顶点并将权和边信息保存于临时数据中
for (int i = 1; i < graph.vertexNum; i++)
{
//保存于邻接点之间的权值
weight[i] = graph.edges[0, i];
//等于0则说明V1与该邻接点没有边
if (weight[i] == short.MaxValue)
tempvertex[i] = noadj;
else
tempvertex[i] = int.Parse(graph.vertex[0]);
}
//从集合V中取出V1节点,只需要将此节点设置为已访问过,weight为0集合
var index = tempvertex[0] = used;
var min = weight[0] = short.MaxValue;
//在V的邻接点中找权值最小的节点
for (int i = 1; i < graph.vertexNum; i++)
{
index = i;
min = short.MaxValue;
for (int j = 1; j < graph.vertexNum; j++)
{
//用于找出当前节点的邻接点中权值最小的未访问点
if (weight[j] < min && tempvertex[j] != 0)
{
min = weight[j];
index = j;
}
}
//累加权值
sum += min;
Console.Write("({0},{1}) ", tempvertex[index], graph.vertex[index]);
//将取得的最小节点标识为已访问
weight[index] = short.MaxValue;
tempvertex[index] = 0;
//从最新的节点出发,将此节点的weight比较赋值
for (int j = 0; j < graph.vertexNum; j++)
{
//已当前节点为出发点,重新选择最小边
if (graph.edges[index, j] < weight[j] && tempvertex[j] != used)
{
weight[j] = graph.edges[index, j];
//这里做的目的将较短的边覆盖点上一个节点的邻接点中的较长的边
tempvertex[j] = int.Parse(graph.vertex[index]);
}
}
}
}
#endregion
二: 最短路径
1. 概念
求最短路径问题其实也是非常有实用价值的,映射到交通系统图中,就是求两个城市间的最短路径问题,还是看这张图,我们可以很容易的看出比如
V1到图中各顶点的最短路径。
① V1 -> V2 直达, 权为2。
② V1 -> V3 直达 权为3。
③ V1->V5->V4 中转 权为3+2=5。
④ V1 -> V5 直达 权为3。
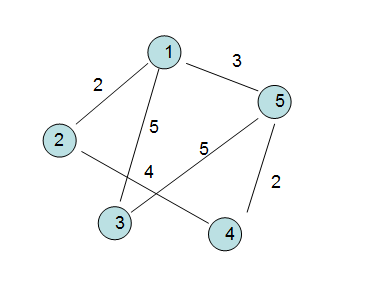 、
、
2. Dijkstra算法
我们的学习需要站在巨人的肩膀上,那么对于现实中非常复杂的问题,我们肯定不能用肉眼看出来,而是根据一定的算法推导出来的。
Dijkstra思想遵循 “走一步,看一步”的原则。
第一步: 我们需要一个集合U,然后将V1放入U集合中,既然走了一步,我们就要看一步,就是比较一下V1的邻接点(V2,V3,V5),
发现(V1,V2)的权值最小,此时我们将V2放入U集合中,表示我们已经找到了V1到V2的最短路径。
第二步:然后将V2做中间点,继续向前寻找权值最小的邻接点,发现只有V4可以连通,此时修改V4的权值为(V1,V2)+(V2,V4)=6。
此时我们就要看一步,发现V1到(V3,V4,V5)中权值最小的是(V1,V5),此时将V5放入U集合中,表示我们已经找到了
V1到V5的最短路径。
第三步:然后将V5做中间点,继续向前寻找权值最小的邻接点,发现能连通的有V3,V4,当我们正想修该V3的权值时发现(V1,V3)的权值
小于(V1->V5->V3),此时我们就不修改,将V3放入U集合中,最后我们找到了V1到V3的最短路径。
第四步:因为V5还没有走完,所以继续用V5做中间点,此时只能连通(V5,V4),当要修改权值的时候,发现原来的V4权值为(V1,V2)+(V2,V4),而
现在的权值为5,小于先前的6,此时更改原先的权值变为5,将V4放入集合中,最后我们找到了V1到V4的最短路径。
#region dijkstra求出最短路径
/// <summary>
/// dijkstra求出最短路径
/// </summary>
/// <param name="g"></param>
public void Dijkstra(MatrixGraph g)
{
int[] weight = new int[g.vertexNum];
int[] path = new int[g.vertexNum];
int[] tempvertex = new int[g.vertexNum];
Console.WriteLine("\n请输入源点的编号:");
//让用户输入要遍历的起始点
int vertex = int.Parse(Console.ReadLine()) - 1;
for (int i = 0; i < g.vertexNum; i++)
{
//初始赋权值
weight[i] = g.edges[vertex, i];
if (weight[i] < short.MaxValue && weight[i] > 0)
path[i] = vertex;
tempvertex[i] = 0;
}
tempvertex[vertex] = 1;
weight[vertex] = 0;
for (int i = 0; i < g.vertexNum; i++)
{
int min = short.MaxValue;
int index = vertex;
for (int j = 0; j < g.vertexNum; j++)
{
//顶点的权值中找出最小的
if (tempvertex[j] == 0 && weight[j] < min)
{
min = weight[j];
index = j;
}
}
tempvertex[index] = 1;
//以当前的index作为中间点,找出最小的权值
for (int j = 0; j < g.vertexNum; j++)
{
if (tempvertex[j] == 0 && weight[index] + g.edges[index, j] < weight[j])
{
weight[j] = weight[index] + g.edges[index, j];
path[j] = index;
}
}
}
Console.WriteLine("\n顶点{0}到各顶点的最短路径为:(终点 < 源点) " + g.vertex[vertex]);
//最后输出
for (int i = 0; i < g.vertexNum; i++)
{
if (tempvertex[i] == 1)
{
var index = i;
while (index != vertex)
{
var j = index;
Console.Write("{0} < ", g.vertex[index]);
index = path[index];
}
Console.WriteLine("{0}\n", g.vertex[index]);
}
else
{
Console.WriteLine("{0} <- {1}: 无路径\n", g.vertex[i], g.vertex[vertex]);
}
}
}
#endregion
最后上一下总的运行代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace MatrixGraph
{
public class Program
{
static void Main(string[] args)
{
MatrixGraphManager manager = new MatrixGraphManager();
//创建图
MatrixGraph graph = manager.CreateMatrixGraph();
manager.OutMatrix(graph);
int sum = 0;
manager.Prim(graph, out sum);
Console.WriteLine("\n最小生成树的权值为:" + sum);
manager.Dijkstra(graph);
//Console.Write("广度递归:\t");
//manager.BFSTraverse(graph);
//Console.Write("\n深度递归:\t");
//manager.DFSTraverse(graph);
Console.ReadLine();
}
}
#region 邻接矩阵的结构图
/// <summary>
/// 邻接矩阵的结构图
/// </summary>
public class MatrixGraph
{
//保存顶点信息
public string[] vertex;
//保存边信息
public int[,] edges;
//深搜和广搜的遍历标志
public bool[] isTrav;
//顶点数量
public int vertexNum;
//边数量
public int edgeNum;
//图类型
public int graphType;
/// <summary>
/// 存储容量的初始化
/// </summary>
/// <param name="vertexNum"></param>
/// <param name="edgeNum"></param>
/// <param name="graphType"></param>
public MatrixGraph(int vertexNum, int edgeNum, int graphType)
{
this.vertexNum = vertexNum;
this.edgeNum = edgeNum;
this.graphType = graphType;
vertex = new string[vertexNum];
edges = new int[vertexNum, vertexNum];
isTrav = new bool[vertexNum];
}
}
#endregion
/// <summary>
/// 图的操作类
/// </summary>
public class MatrixGraphManager
{
#region 图的创建
/// <summary>
/// 图的创建
/// </summary>
/// <param name="g"></param>
public MatrixGraph CreateMatrixGraph()
{
Console.WriteLine("请输入创建图的顶点个数,边个数,是否为无向图(0,1来表示),已逗号隔开。");
var initData = Console.ReadLine().Split(',').Select(i => int.Parse(i)).ToList();
MatrixGraph graph = new MatrixGraph(initData[0], initData[1], initData[2]);
//我们默认“正无穷大为没有边”
for (int i = 0; i < graph.vertexNum; i++)
{
for (int j = 0; j < graph.vertexNum; j++)
{
graph.edges[i, j] = short.MaxValue;
}
}
Console.WriteLine("请输入各顶点信息:");
for (int i = 0; i < graph.vertexNum; i++)
{
Console.Write("\n第" + (i + 1) + "个顶点为:");
var single = Console.ReadLine();
//顶点信息加入集合中
graph.vertex[i] = single;
}
Console.WriteLine("\n请输入构成两个顶点的边和权值,以逗号隔开。\n");
for (int i = 0; i < graph.edgeNum; i++)
{
Console.Write("第" + (i + 1) + "条边:\t");
initData = Console.ReadLine().Split(',').Select(j => int.Parse(j)).ToList();
int start = initData[0];
int end = initData[1];
int weight = initData[2];
//给矩阵指定坐标位置赋值
graph.edges[start - 1, end - 1] = weight;
//如果是无向图,则数据呈“二,四”象限对称
if (graph.graphType == 1)
{
graph.edges[end - 1, start - 1] = weight;
}
}
return graph;
}
#endregion
#region 输出矩阵数据
/// <summary>
/// 输出矩阵数据
/// </summary>
/// <param name="graph"></param>
public void OutMatrix(MatrixGraph graph)
{
for (int i = 0; i < graph.vertexNum; i++)
{
for (int j = 0; j < graph.vertexNum; j++)
{
if (graph.edges[i, j] == short.MaxValue)
Console.Write("∽\t");
else
Console.Write(graph.edges[i, j] + "\t");
}
//换行
Console.WriteLine();
}
}
#endregion
#region 广度优先
/// <summary>
/// 广度优先
/// </summary>
/// <param name="graph"></param>
public void BFSTraverse(MatrixGraph graph)
{
//访问标记默认初始化
for (int i = 0; i < graph.vertexNum; i++)
{
graph.isTrav[i] = false;
}
//遍历每个顶点
for (int i = 0; i < graph.vertexNum; i++)
{
//广度遍历未访问过的顶点
if (!graph.isTrav[i])
{
BFSM(ref graph, i);
}
}
}
/// <summary>
/// 广度遍历具体算法
/// </summary>
/// <param name="graph"></param>
public void BFSM(ref MatrixGraph graph, int vertex)
{
//这里就用系统的队列
Queue<int> queue = new Queue<int>();
//先把顶点入队
queue.Enqueue(vertex);
//标记此顶点已经被访问
graph.isTrav[vertex] = true;
//输出顶点
Console.Write(" ->" + graph.vertex[vertex]);
//广度遍历顶点的邻接点
while (queue.Count != 0)
{
var temp = queue.Dequeue();
//遍历矩阵的横坐标
for (int i = 0; i < graph.vertexNum; i++)
{
if (!graph.isTrav[i] && graph.edges[temp, i] != 0)
{
graph.isTrav[i] = true;
queue.Enqueue(i);
//输出未被访问的顶点
Console.Write(" ->" + graph.vertex[i]);
}
}
}
}
#endregion
#region 深度优先
/// <summary>
/// 深度优先
/// </summary>
/// <param name="graph"></param>
public void DFSTraverse(MatrixGraph graph)
{
//访问标记默认初始化
for (int i = 0; i < graph.vertexNum; i++)
{
graph.isTrav[i] = false;
}
//遍历每个顶点
for (int i = 0; i < graph.vertexNum; i++)
{
//广度遍历未访问过的顶点
if (!graph.isTrav[i])
{
DFSM(ref graph, i);
}
}
}
#region 深度递归的具体算法
/// <summary>
/// 深度递归的具体算法
/// </summary>
/// <param name="graph"></param>
/// <param name="vertex"></param>
public void DFSM(ref MatrixGraph graph, int vertex)
{
Console.Write("->" + graph.vertex[vertex]);
//标记为已访问
graph.isTrav[vertex] = true;
//要遍历的六个点
for (int i = 0; i < graph.vertexNum; i++)
{
if (graph.isTrav[i] == false && graph.edges[vertex, i] != 0)
{
//深度递归
DFSM(ref graph, i);
}
}
}
#endregion
#endregion
#region prim算法获取最小生成树
/// <summary>
/// prim算法获取最小生成树
/// </summary>
/// <param name="graph"></param>
public void Prim(MatrixGraph graph, out int sum)
{
//已访问过的标志
int used = 0;
//非邻接顶点标志
int noadj = -1;
//定义一个输出总权值的变量
sum = 0;
//临时数组,用于保存邻接点的权值
int[] weight = new int[graph.vertexNum];
//临时数组,用于保存顶点信息
int[] tempvertex = new int[graph.vertexNum];
//取出邻接矩阵的第一行数据,也就是取出第一个顶点并将权和边信息保存于临时数据中
for (int i = 1; i < graph.vertexNum; i++)
{
//保存于邻接点之间的权值
weight[i] = graph.edges[0, i];
//等于0则说明V1与该邻接点没有边
if (weight[i] == short.MaxValue)
tempvertex[i] = noadj;
else
tempvertex[i] = int.Parse(graph.vertex[0]);
}
//从集合V中取出V1节点,只需要将此节点设置为已访问过,weight为0集合
var index = tempvertex[0] = used;
var min = weight[0] = short.MaxValue;
//在V的邻接点中找权值最小的节点
for (int i = 1; i < graph.vertexNum; i++)
{
index = i;
min = short.MaxValue;
for (int j = 1; j < graph.vertexNum; j++)
{
//用于找出当前节点的邻接点中权值最小的未访问点
if (weight[j] < min && tempvertex[j] != 0)
{
min = weight[j];
index = j;
}
}
//累加权值
sum += min;
Console.Write("({0},{1}) ", tempvertex[index], graph.vertex[index]);
//将取得的最小节点标识为已访问
weight[index] = short.MaxValue;
tempvertex[index] = 0;
//从最新的节点出发,将此节点的weight比较赋值
for (int j = 0; j < graph.vertexNum; j++)
{
//已当前节点为出发点,重新选择最小边
if (graph.edges[index, j] < weight[j] && tempvertex[j] != used)
{
weight[j] = graph.edges[index, j];
//这里做的目的将较短的边覆盖点上一个节点的邻接点中的较长的边
tempvertex[j] = int.Parse(graph.vertex[index]);
}
}
}
}
#endregion
#region dijkstra求出最短路径
/// <summary>
/// dijkstra求出最短路径
/// </summary>
/// <param name="g"></param>
public void Dijkstra(MatrixGraph g)
{
int[] weight = new int[g.vertexNum];
int[] path = new int[g.vertexNum];
int[] tempvertex = new int[g.vertexNum];
Console.WriteLine("\n请输入源点的编号:");
//让用户输入要遍历的起始点
int vertex = int.Parse(Console.ReadLine()) - 1;
for (int i = 0; i < g.vertexNum; i++)
{
//初始赋权值
weight[i] = g.edges[vertex, i];
if (weight[i] < short.MaxValue && weight[i] > 0)
path[i] = vertex;
tempvertex[i] = 0;
}
tempvertex[vertex] = 1;
weight[vertex] = 0;
for (int i = 0; i < g.vertexNum; i++)
{
int min = short.MaxValue;
int index = vertex;
for (int j = 0; j < g.vertexNum; j++)
{
//顶点的权值中找出最小的
if (tempvertex[j] == 0 && weight[j] < min)
{
min = weight[j];
index = j;
}
}
tempvertex[index] = 1;
//以当前的index作为中间点,找出最小的权值
for (int j = 0; j < g.vertexNum; j++)
{
if (tempvertex[j] == 0 && weight[index] + g.edges[index, j] < weight[j])
{
weight[j] = weight[index] + g.edges[index, j];
path[j] = index;
}
}
}
Console.WriteLine("\n顶点{0}到各顶点的最短路径为:(终点 < 源点) " + g.vertex[vertex]);
//最后输出
for (int i = 0; i < g.vertexNum; i++)
{
if (tempvertex[i] == 1)
{
var index = i;
while (index != vertex)
{
var j = index;
Console.Write("{0} < ", g.vertex[index]);
index = path[index];
}
Console.WriteLine("{0}\n", g.vertex[index]);
}
else
{
Console.WriteLine("{0} <- {1}: 无路径\n", g.vertex[i], g.vertex[vertex]);
}
}
}
#endregion
}
}

算法速成系列至此就全部结束了,公司给我们的算法培训也于上周五结束,呵呵,赶一下同步。最后希望大家能对算法重视起来,
学好算法,终身收益。
相关推荐
-

算法系列15天速成 第四天 五大经典查找【上】
在我们的算法中,有一种叫做线性查找. 分为:顺序查找. 折半查找. 查找有两种形态: 分为:破坏性查找, 比如有一群mm,我猜她们的年龄,第一位猜到了是23+,此时这位mm已经从我脑海里面的mmlist中remove掉了. 哥不找23+的,所以此种查找破坏了原来的结构. 非破坏性查找, 这种就反之了,不破坏结构. 顺序查找: 这种非常简单,就是过一下数组,一个一个的比,找到为止. 复制代码 代码如下: using System;using System.Collections.
-
算法系列15天速成 第十四天 图【上】
今天来分享一下图,这是一种比较复杂的非线性数据结构,之所以复杂是因为他们的数据元素之间的关系是任意的,而不像树那样 被几个性质定理框住了,元素之间的关系还是比较明显的,图的使用范围很广的,比如网络爬虫,求最短路径等等,不过大家也不要胆怯, 越是复杂的东西越能体现我们码农的核心竞争力. 既然要学习图,得要遵守一下图的游戏规则. 一: 概念 图是由"顶点"的集合和"边"的集合组成.记作:G=(V,E): <1> 无向图 就是"图"中的边没
-
算法系列15天速成 第九天 队列
一:概念 队列是一个"先进先出"的线性表,牛X的名字就是"First in First Out(FIFO)",生活中有很多这样的场景,比如读书的时候去食堂打饭时的"排队".当然我们拒绝插队. 二:存储结构 前几天也说过,线性表有两种"存储结构",① 顺序存储,②链式存储.当然"队列"也脱离不了这两种服务,这里我就分享一下"顺序存储". 顺序存储时,我们会维护一个叫做"head头
-
算法系列15天速成 第二天 七大经典排序【中】
首先感谢朋友们对第一篇文章的鼎力支持,感动中....... 今天说的是选择排序,包括"直接选择排序"和"堆排序". 话说上次"冒泡排序"被快排虐了,而且"快排"赢得了内库的重用,众兄弟自然眼红,非要找快排一比高下. 这不今天就来了两兄弟找快排算账. 1.直接选择排序: 先上图: 说实话,直接选择排序最类似于人的本能思想,比如把大小不一的玩具让三岁小毛孩对大小排个序, 那小孩首先会在这么多玩具中找到最小的放在第一位,然后找到次
-
算法系列15天速成 第八天 线性表【下】
一:线性表的简单回顾 上一篇跟大家聊过"线性表"顺序存储,通过实验,大家也知道,如果我每次向顺序表的头部插入元素,都会引起痉挛,效率比较低下,第二点我们用顺序存储时,容易受到长度的限制,反之就会造成空间资源的浪费. 二:链表 对于顺序表存在的若干问题,链表都给出了相应的解决方案. 1. 概念:其实链表的"每个节点"都包含一个"数据域"和"指针域". "数据域"中包含当前的数据. "指针域"
-
算法系列15天速成 第十一天 树操作(上)
先前我们讲的都是"线性结构",他的特征就是"一个节点最多有一个"前驱"和一个"后继".那么我们今天讲的树会是怎样的呢? 我们可以对"线性结构"改造一下,变为"一个节点最多有一个"前驱"和"多个后继".哈哈,这就是我们今天说的"树". 一: 树 我们思维中的"树"就是一种枝繁叶茂的形象,那么数据结构中的"树"该
-
算法系列15天速成 第六天 五大经典查找【下】
大家是否感觉到,树在数据结构中大行其道,什么领域都要沾一沾,碰一碰.就拿我们前几天学过的排序就用到了堆和今天讲的"二叉排序树",所以偏激的说,掌握的树你就是牛人了. 今天就聊聊这个"五大经典查找"中的最后一个"二叉排序树". 1. 概念: <1> 其实很简单,若根节点有左子树,则左子树的所有节点都比根节点小. 若根节点有右子树,则右子树的所有节点都比根节点大. &
-
算法系列15天速成 第一天 七大经典排序【上】
针对现实中的排序问题,算法有七把利剑可以助你马道成功. 首先排序分为四种: 交换排序: 包括冒泡排序,快速排序. 选择排序: 包括直接选择排序,堆排序. 插入排序: 包括直接插入排序,希尔排序. 合并排序: 合并排序. 那么今天我们讲的就是交换排序,我们都知道,C#类库提供的排序是快排,为了让今天玩的有意思点,我们设计算法来跟类库提供的快排较量较量.争取KO对手. 冒泡排序: 首先我们自己来设计一下"冒泡排序",这种排序很现实的例子就是:我抓一
-
算法系列15天速成 第十二天 树操作【中】
先前说了树的基本操作,我们采用的是二叉链表来保存树形结构,当然二叉有二叉的困扰之处,比如我想找到当前结点的"前驱"和"后继",那么我们就必须要遍历一下树,然后才能定位到该"节点"的"前驱"和"后继",每次定位都是O(n),这不是我们想看到的,那么有什么办法来解决呢? (1) 在节点域中增加二个指针域,分别保存"前驱"和"后继",那么就是四叉链表了,哈哈,还是有点浪费空
-
算法系列15天速成——第十三天 树操作【下】
听说赫夫曼胜过了他的导师,被认为"青出于蓝而胜于蓝",这句话也是我比较欣赏的,嘻嘻. 一 概念 了解"赫夫曼树"之前,几个必须要知道的专业名词可要熟练记住啊. 1: 结点的权 "权"就相当于"重要度",我们形象的用一个具体的数字来表示,然后通过数字的大小来决定谁重要,谁不重要. 2: 路径 树中从"一个结点"到"另一个结点"之间的分支. 3: 路径长度 一个路径上的分支数量. 4: 树
-
算法系列15天速成 第五天 五大经典查找【中】
哈希查找: 对的,他就是哈希查找,说到哈希,大家肯定要提到哈希函数,呵呵,这东西已经在我们脑子里面形成固有思维了.大家一定要知道"哈希"中的对应关系. 比如说: "5"是一个要保存的数,然后我丢给哈希函数,哈希函数给我返回一个"2",那么此时的"5"和"2"就建立一种对应关系,这种关系就是所谓的"哈希关系",在实际应用中也就形成了"2"是key,"5
-
算法系列15天速成 第七天 线性表【上】
哈哈,我们的数据也一样,存在这三种基本关系,用术语来说就是: <1> 线性关系.<2> 树形关系.<3> 网状关系. 一: 线性表 1 概念: 线性表也就是关系户中最简单的一种关系,一对一. 如:学生学号的集合就是一个线性表. 2 特征: ① 有且只有一个"首元素". ② 有且只有一个"末元素".
-
算法系列15天速成 第十天 栈
一: 概念 栈,同样是一种特殊的线性表,是一种Last In First Out(LIFO)的形式,现实中有很多这样的例子, 比如:食堂中的一叠盘子,我们只能从顶端一个一个的取. 二:存储结构 "栈"不像"队列",需要两个指针来维护,栈只需要一个指针就够了,这得益于栈是一种一端受限的线性表. 这里同样用"顺序结构"来存储这个"栈",top指针指向栈顶,所有的操作只能在top处. 代码段: 复制代码 代码如下: #region
-
算法系列15天速成 第三天 七大经典排序【下】
直接插入排序: 这种排序其实蛮好理解的,很现实的例子就是俺们斗地主,当我们抓到一手乱牌时,我们就要按照大小梳理扑克,30秒后, 扑克梳理完毕,4条3,5条s,哇塞...... 回忆一下,俺们当时是怎么梳理的. 最左一张牌是3,第二张牌是5,第三张牌又是3,赶紧插到第一张牌后面去,第四张牌又是3,大喜,赶紧插到第二张后面去, 第五张牌又是3,狂喜,哈哈,一门炮就这样产生了. 怎么样,生活中处处都是算法,早已经融入我们的生活和血液. 下面就上图说明: 看这张图不知道大家可