mysql优化之路----hash索引优化
创建表
CREATE TABLE `t1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `msg` varchar(20) NOT NULL DEFAULT '', `crcmsg` int(15) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
//插入数据
insert into t1 (msg) values('www.baidu.com'),('www.sina.com');
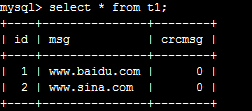
分别给msg, crcmsg 字段添加索引
alter table t1 add index msg(msg(5)); update t1 set crcmsg=crc32(msg);
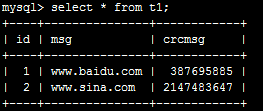
alter table t1 add index crcmsg(crcmsg);
开始做测试
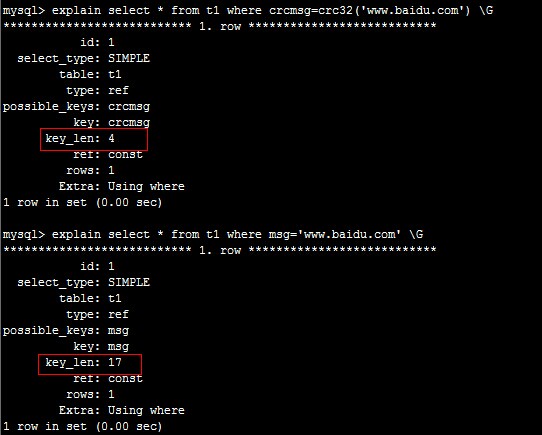
最后数据表结构
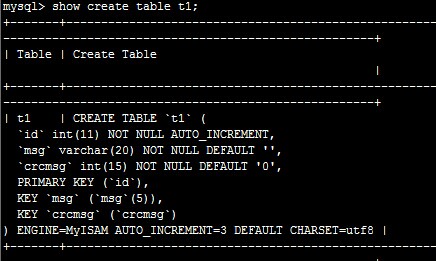
根据key_len的长度的大小从而给数据库查询提高速度。
自己做的小测试,希望能够给您带来收获,祝您工作愉快。
相关推荐
-
Mysql limit 优化,百万至千万级快速分页 复合索引的引用并应用于轻量级框架
MySql 这个数据库绝对是适合dba级的高手去玩的,一般做一点1万篇新闻的小型系统怎么写都可以,用xx框架可以实现快速开发.可是数据量到了10万,百万至千万,他的性能还能那么高吗?一点小小的失误,可能造成整个系统的改写,甚至更本系统无法正常运行!好了,不那么多废话了.用事实说话,看例子: 数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中 title 用定长,info 用text, id 是逐渐,vtype是tinyint,vtype是索引.这是一个
-
Mysql使用索引实现查询优化
索引的目的在于提高查询效率,可以类比字典,如果要查"mysql"这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的. 1.索引的优点 假设你拥有三个未索引的表t1.t2和t3,每个表都分别包含数据列i1.i2和i3,并且每个表都包含了1000条数据行,其序号从1到1000.查找某些值匹配的数据行组合的查询可能如下所示: SELECT t1.i1, t2.i2, t3.i3 FROM t1, t2,
-
MySQL查询优化之索引的应用详解
糟糕的SQL查询语句可对整个应用程序的运行产生严重的影响,其不仅消耗掉更多的数据库时间,且它将对其他应用组件产生影响. 如同其它学科,优化查询性能很大程度上决定于开发者的直觉.幸运的是,像MySQL这样的数据库自带有一些协助工具.本文简要讨论诸多工具之三种:使用索引,使用EXPLAIN分析查询以及调整MySQL的内部配置. MySQL允许对数据库表进行索引,以此能迅速查找记录,而无需一开始就扫描整个表,由此显著地加快查询速度.每个表最多可以做到16个索引,此外MySQL还支持多列索引及全文检索.
-
MySQL Order By索引优化方法
尽管 ORDER BY 不是和索引的顺序准确匹配,索引还是可以被用到,只要不用的索引部分和所有的额外的 ORDER BY 字段在 WHERE 子句中都被包括了. 使用索引的MySQL Order By 下列的几个查询都会使用索引来解决 ORDER BY 或 GROUP BY 部分: 复制代码 代码如下: SELECT * FROM t1 ORDER BY key_part1,key_part2,... ; SELECT * FROM t1 WHERE key_part1=constant ORD
-

MySQL索引背后的之使用策略及优化(高性能索引策略)
本章的内容完全基于上文的理论基础,实际上一旦理解了索引背后的机制,那么选择高性能的策略就变成了纯粹的推理,并且可以理解这些策略背后的逻辑. 示例数据库 为了讨论索引策略,需要一个数据量不算小的数据库作为示例.本文选用MySQL官方文档中提供的示例数据库之一:employees.这个数据库关系复杂度适中,且数据量较大.下图是这个数据库的E-R关系图(引用自MySQL官方手册): 图12 MySQL官方文档中关于此数据库的页面为http://dev.mysql.com/doc/employee/en
-
MySQL中索引优化distinct语句及distinct的多字段操作
MySQL通常使用GROUPBY(本质上是排序动作)完成DISTINCT操作,如果DISTINCT操作和ORDERBY操作组合使用,通常会用到临时表.这样会影响性能. 在一些情况下,MySQL可以使用索引优化DISTINCT操作,但需要活学活用.本文涉及一个不能利用索引完成DISTINCT操作的实例. 实例1 使用索引优化DISTINCT操作 create table m11 (a int, b int, c int, d int, primary key(a)) engine=INNODB;
-
mysql性能优化之索引优化
作为免费又高效的数据库,mysql基本是首选.良好的安全连接,自带查询解析.sql语句优化,使用读写锁(细化到行).事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多.即使有这么多优点,仍依赖人去做点优化,看书后写个总结巩固下,有错请指正. 完整的mysql优化需要很深的功底,大公司甚至有专门写mysql内核的,sql优化攻城狮,mysql服务器的优化,各种参数常量设定,查询语句优化,主
-
MySQL的id关联和索引使用的实际优化案例
昨晚收到客服MM电话,一用户反馈数据库响应非常慢,手机收到load异常报警,登上主机后发现大量sql执行非常慢,有的执行时间超过了10s 优化点一: SELECT * FROM `sitevipdb`.`game_shares_buy_list` WHERE price>='2.00′ ORDER BY tran_id DESC LIMIT 10; 表结构为: CREATE TABLE `game_shares_buy_list` ( `tran_id` int(10) unsigned NOT
-
美团网技术团队分享的MySQL索引及慢查询优化教程
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如"精通MySQL"."SQL语句优化"."了解数据库原理"等要求.我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,
-
MySQL 联合索引与Where子句的优化 提高数据库运行效率
网站系统上线至今,数据量已经不知不觉上到500M,近8W记录了.涉及数据库操作的基本都是变得很慢了,用的人都会觉得躁火~~然后把这个情况在群里一贴,包括机器配置什么的一说,马上就有群友发话了,而且帮我确定了不是机器配置的问题,"深圳-枪手"热心人他的机器512内存过百W的数据里也跑得飞快,甚至跟那些几W块的机器一样牛(吹过头了),呵呵~~~ 在群友的分析指点下,尝试把排序.条件等一个一个去除来做测试,结果发现问题就出在排序部分,去除排序的时候,执行时间由原来的48秒变成0.3x秒,这是