SQL Server 性能调优之查询从20秒至2秒的处理方法
一、需求
需求很简单,就是需要查询一个报表,只有1个表,数据量大约60万左右,但是中间有些逻辑。
先说明一下服务器配置情况:1核CPU、2GB内存、机械硬盘、Sqlserver 2008 R2、Windows Server2008 R2 SP1和阿里云的服务器,简单说就是阿里云最差的服务器。
1、原始表结构
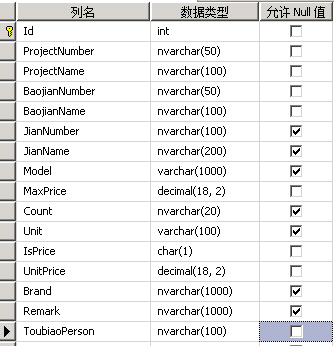
非常简单的一张表,这次不讨论数据冗余和表字段的设计,如是否可以把Project和Baojian提出成一个表等等,这个是原始表结构,这个目前是没有办法改变的。
2、查询的sql语句为
select *from(
select *,ROW_NUMBER() OVER (ORDER BY sc desc) as rank
from(
select *,
case when ( 40-(a.p*(case when a.p > 0 then 1 else -0.5 end)))<=30
then 30
else ( 40-(a.p*(case when a.p > 0 then 1 else -0.5 end)))
end as sc
from (
select * from (
select a.ProjectNumber, a.ProjectName, a.BaojianNumber, a.BaojianName, a.ToubiaoPerson,
sum(UnitPrice) as sumPrice,
b.price as avgPrice,
((sum(UnitPrice)-b.price)/nullif(b.price,0)*100) as p,
sum(case when UnitPrice>b.price then b.price else UnitPrice end )as pprice,
sum(case when UnitPrice>MaxPrice then 1 else 0 end ) as countChao
from ToubiaoDetailTest1 a
join (
select ProjectNumber, ProjectName, BaojianNumber, BaojianName, avg(price) as price
from(
select * from(
select ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson,
SUM(UnitPrice) as price,
SUM(case when UnitPrice>MaxPrice then 1 else 0 end ) as countChao
from ToubiaoDetailTest1
group BY ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson
) tt
where tt.countChao = 0
) t
group by ProjectNumber, ProjectName, BaojianNumber, BaojianName
) b
on a.ProjectNumber=b.ProjectNumber and a.ProjectName=b.ProjectName and a.BaojianNumber=b.BaojianNumber and a.BaojianName=b.BaojianName
group by a.BaojianNumber, a.BaojianName, a.ProjectNumber, a.ProjectName, a.ToubiaoPerson, b.price
) tt
where tt.countChao=0
) a
) b
) t
order by rank
此段sql语句主要的功能是:
1、根据ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson分组,查询所有数据的sum(UnitPrice)
其中UnitPrice>MaxPrice的判断是为了逻辑,如果有一条数据满足,则此分组所有的数据不查询。
2、根据ProjectNumber, ProjectName, BaojianNumber, BaojianName 分组,查询所有数据的avg(price),以上两步主要就是为了查询根据ProjectNumber, ProjectName, BaojianNumber, BaojianName分组的avg(price)值。
3、然后根据逻辑获取相应的值、分数和按照分数排序分页等等操作。
二、性能调优
在未做任何优化之前,查询一次的时间大约为20秒左右。
1、建立索引
根据sql语句我们可以知道,会根据5个字段(ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson)进行分组聚合,所以尝试添加非聚集索引idx_calc。
在索引键列添加ProjectNumber, ProjectName, BaojianNumber, BaojianName, ToubiaoPerson。如图:
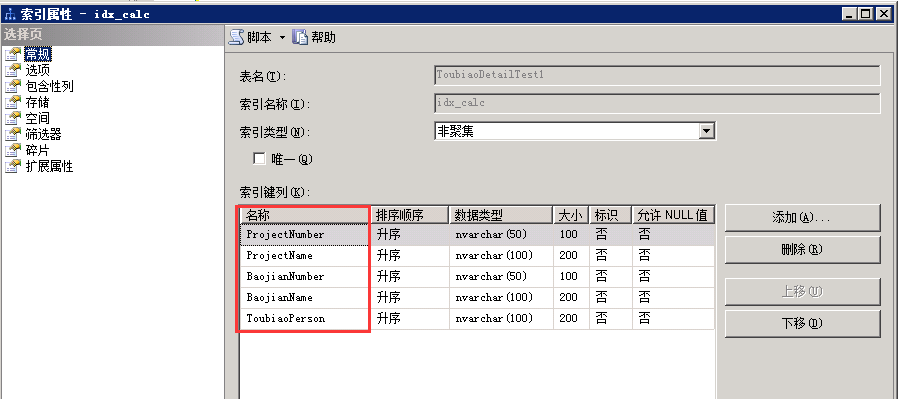
然后执行查询sql语句,发现执行时间已经减半了,只要10610毫秒。
2、索引包含列
分析查询sql可以得知,我们需要计算的值只有UnitPrice和MaxPrice,所以想到把UnitPrice和MaxPrice添加到idx_calc的包含列中。如图

然后执行查询sql语句,发现执行时间再次减半,只要6313毫秒,现在已经从之前的20多秒优化成6秒多。
3、再次优化查询Sql
再次分析sql语句可以把计算所有数据的avg(price)语句暂时放置临时表(#temp_table)中,再计算其他值的时候直接从临时表中(#temp_table)获取数据。

然后执行查询sql语句,执行时间只有2323毫秒。
在硬件、表数据量和查询稍复杂的情况下,这样已经可以基本上满足查询需求了。
三、总结
经过三步:1、建立索引,2、添加包含列,3、用临时表。用三步可以把查询时间从20秒优化至2秒。
以上所述是小编给大家介绍的SQL Server 性能调优之查询从20秒至2秒,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

sqlserver性能调优经验总结
相信不少的朋友,无论是做开发.架构的,还是DBA等,都经常听说"调优"这个词.说起"调优",可能会让很多技术人员心头激情澎湃,也可能会让很多人感觉苦恼.当然,也有很多人对此不屑一顾,因为并不是每个人接触到的项目都很大,也不是每个人做的项目都对性能要求很高. 在主流的企业级开发和互联网应用中,数据库的重要性是不言而喻的,而数据库的性能对于整个系统的性能而言也是至关重要的,这里无庸赘述. sqlserver的性能调优,其实是个很宽广的话题.坦白讲,想从概念到实践的完全讲
-
SQL Server性能调优之缓存
在执行任何查询时,SQL Server都会将数据读取到内存,数据使用之后,不会立即释放,而是会缓存在内存Buffer中,当再次执行相同的查询时,如果所需数据全部缓存在内存中,那么SQL Server不会产生Disk IO操作,立即返回查询结果,这是SQL Server的性能优化机制. 一,主要的内存消费者(Memory Consumer) 1,数据缓存(Data Cache) Data Cache是存储数据页(Data Page)的缓冲区,当SQL Server需要读取数据文件(File)中的数
-
SQL Server 性能调优之查询从20秒至2秒的处理方法
一.需求 需求很简单,就是需要查询一个报表,只有1个表,数据量大约60万左右,但是中间有些逻辑. 先说明一下服务器配置情况:1核CPU.2GB内存.机械硬盘.Sqlserver 2008 R2.Windows Server2008 R2 SP1和阿里云的服务器,简单说就是阿里云最差的服务器. 1.原始表结构 非常简单的一张表,这次不讨论数据冗余和表字段的设计,如是否可以把Project和Baojian提出成一个表等等,这个是原始表结构,这个目前是没有办法改变的. 2.查询的sql语句为 sele
-
sql server性能调优 I/O开销的深入解析
一.概述 IO 内存是sql server最重要的资源,数据从磁盘加载到内存,再从内存中缓存,输出到应用端,在sql server 内存初探中有介绍.在明白了sqlserver内存原理后,就能更好的分析I/O开销,从而提升数据库的整体性能. 在生产环境下数据库的sqlserver服务启动后一个星期,就可以通过dmv来分析优化.在I/O分析这块可以从物理I/O和内存I/O二方面来分析, 重点分析应在内存I/O上,可能从多个维度来分析,比如从sql server服务启动以来 历史I/O开销总量分析,
-
mysql sql语句性能调优简单实例
mysql sql语句性能调优简单实例 在做服务器开发时,有时候对并发量有一定的要求,有时候影响速度的是某个sql语句,比如某个存储过程.现在假设服务器代码执行过程中,某个sql执行比较缓慢,那如何进行优化呢? 假如现在服务器代码执行如下sql存储过程特别缓慢: call sp_wplogin_register(1, 1, 1, '830000', '222222'); 可以按如下方法来进行调试: 1. 打开mysql profiling: 2. 然后执行需要调优的sql,我们这里执行两条sq
-
使用MySQL的Explain执行计划的方法(SQL性能调优)
目录 前言 1. explain的使用 2. explain字段详解 id列 select_type列 table列 partitions列 type列 system const eq_ref ref ref_or_null index_merge range index ALL possible_keys列 key列 key_len列 ref列 rows列 filtered列 Extra列 Using where Using index Using filesort Using tempora
-
SQL SERVER性能优化综述(很好的总结,不要错过哦)第1/3页
一.分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求.响应时间的需求.硬件的配置等.最好能有各种需求的量化的指标. 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统). 二.设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎
-
关于redis状态监控和性能调优详解
前言 对于任何应用服务和组件,都需要一套完善可靠谱监控方案. 尤其redis这类敏感的纯内存.高并发和低延时的服务,一套完善的监控告警方案,是精细化运营的前提. 本文主要给大家介绍了关于redis状态监控和性能调优的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 1.redis-benchmark redis基准信息,redis服务器性能检测 例如: 检测redis服务器性能,本机6379端口的实例,100个并发连接,100000个请求 redis-benchmark
-
10个MySQL性能调优的方法
MYSQL 应该是最流行了 WEB 后端数据库.WEB 开发语言最近发展很快,PHP, Ruby, Python, Java 各有特点,虽然 NOSQL 最近越來越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储. MYSQL 如此方便和稳定,以至于我们在开发 WEB 程序的时候很少想到它.即使想到优化也是程序级别的,比如,不要写过于消耗资源的 SQL 语句.但是除此之外,在整个系统上仍然有很多可以优化的地方. 1. 选择合适的存储引擎: InnoDB 除非你的数据表使用来做
-
关于MySQL性能调优你必须了解的15个重要变量(小结)
前言: MYSQL 应该是最流行了 WEB 后端数据库.虽然 NOSQL 最近越来越多的被提到,但是相信大部分架构师还是会选择 MYSQL 来做数据存储.本文作者总结梳理MySQL性能调优的15个重要变量,又不足需要补充的还望大佬指出. 1.DEFAULT_STORAGE_ENGINE 如果你已经在用MySQL 5.6或者5.7,并且你的数据表都是InnoDB,那么表示你已经设置好了.如果没有,确保把你的表转换为InnoDB并且设置default_storage_engine为InnoDB. 为