如何避免go的map竞态问题的方法
目录
- 背景
- 为什么会出现竞态问题
- 如何解决竞态问题
- 1、使用go的一些并发原语
- 2、加读写锁(RWMutex map)
- 3、分片加锁
- 4、go的原生可并发map
- 性能对比
- 最终结论
背景
在使用go语言开发的过程中,我碰到过这样一种情况,就是代码自测没问题,代码检查没问题,上线跑了一段时间时间了也没问题,就是突然偶尔会抽风panic,导致程序所在的pod(k8s的运行docker镜像的最小单位)重启了,而程序里抛出来的异常如下

,意思是多个协程正在同时对同一个map变量进行读写,这个就涉及到go程序的竞态问题,而竞态问题也是我们日常开发中遇到比较多的情况
为什么会出现竞态问题
出现这个问题的主要原因是有多个协程在对同一个map变量进行修改,这样就可能会出现map被一个协程修改到一半的时候,然后另外一个协程就来读取了,导致读到一个“半成品”的map变量。而这个就说明一个问题,就是map类型并不是并发安全的
而并发安全的定义就是:在高并发下,进程、线程(协程)出现资源竞争,导致出现脏读,脏写,死锁等情况。
那么go语言有如下几种类型不具备并发安全:map,slice,struct,channel,string
不过奇怪的是,只有map类型发生并发竞争的时候,才会抛出fatal error,这个是无法被recover的,一定会中断程序,而这也导致程序运行的pod会被检测出异常从而重启
查了资料,有一种说法是,map大部分会被用来存配置文件,而配置文件出错可能会导致一些严重的业务问题,所以宁愿程序崩溃也要保全业务数据不会出现脏数据(只是一种说法,不用太过在意)
如何解决竞态问题
1、使用go的一些并发原语
如果需要修改的变量是程序启动之后就不需要修改的配置,那么可以使用sync.Once包来处理,这个包的作用就是限制一件事情只做一次,示例代码如下
type User struct {
Name string
Other map[string]interface{}
ConfigOnce sync.Once
}
// InitConfigOnce
// @description "初始化配置信息,只执行一次"
// @auth yezibin 2023-01-21 15:38:09
// @param name string "description"
// @param other map[string]interface{} "description"
// @return *User "description"
func (u *User)InitConfigOnce(name string, other map[string]interface{}) *User {
//Do包起来的方法,只会执行一次,但是必须是同一个sync.Once变量
u.ConfigOnce.Do(func() {
fmt.Println("ok")
u.Name = name
u.Other = other
})
return u
}
// GetUserConfig
// @description "打印配置文件"
// @auth yezibin 2023-01-21 15:38:36
func (u *User) GetUserConfig() {
fmt.Println(u)
}
2、加读写锁(RWMutex map)
出现竞态的本质是因为多个协程对同一个变量同时进行读与写,通过用锁来防止这个情况,因为我举得案例是读多写少的情况,用上读写锁性能会更好,示例代码如下
type Mmap struct {
Data map[string]interface{}
Mu sync.RWMutex //因为主要是配置,属于读多写少情况,所以使用读写锁提高锁的性能
}
// InitMmap
// @description "初始化读写锁的map结构体"
// @auth yezibin 2023-01-21 00:09:30
// @return *Config "description"
func InitMmap() *Mmap {
return &Mmap{
Data: make(map[string]interface{}),
}
}
// Get
// @description "获取配置map数据"
// @auth yezibin 2023-01-21 00:10:09
// @param name string "description"
// @return interface{} "description"
func (m *Mmap) Get(name string) interface{} {
m.Mu.RLock()
defer m.Mu.RUnlock()
return m.Data[name]
}
// Set
// @description "批量设置map的值"
// @auth yezibin 2023-02-05 13:08:17
// @param data map[string]interface{} "description"
func (m *Mmap) Set(data map[string]interface{}) {
m.Mu.Lock()
defer m.Mu.Unlock()
for k, v := range data {
m.Data[k] = v
}
}
// SetOne
// @description "设置配置map数据"
// @auth yezibin 2023-01-21 00:10:23
// @param key string "description"
// @param val string "description"
func (m *Mmap) SetOne(key, val string) {
m.Mu.Lock()
defer m.Mu.Unlock()
m.Data[key] = val
}
建议
1、如果属于读多写少的情况,尽量选择读写锁来减少锁住的范围,从而提高读写性能
2、这里推荐将需要用来读写的map变量和锁共同组建一个struct,这样能保证读和写上的是同一把读写锁,同时也方便整合对map变量的操作
3、分片加锁
方案2中虽然加了读写锁,比加一把普通的锁要性能高些,不过锁的粒度还是大了些,当高并发来袭时,写的操作必然会阻塞读的动作,那么有没有办法将锁住的范围缩小一些呢
思路:如果给map里的每个元素加锁,每次修改只是单个元素的锁生效,其他没改到的元素就正常读,这样锁的粒度会更细,这就是分片加锁的原理

这种就是将一把“大”锁拆成一把把小锁,是一种空间换时间的方法
实现上,已经有人实现了好用的具有分片锁的map,库地址:https://github.com/orcaman/concurrent-map
import (
cmap "github.com/orcaman/concurrent-map"
"sync"
)
// InitCmap
// @description "初始化分片锁的map"
// @auth yezibin 2023-02-05 14:08:17
// @return *cmapConfig "description"
func InitCmap() *cmapConfig {
return &cmapConfig{
cmap.New(),
}
}
// Set
// @description "批量往map写入元素"
// @auth yezibin 2023-02-05 14:10:02
// @param config map[string]interface{} "description"
func (c *cmapConfig) Set(config map[string]interface{}) {
for k, v := range config{
c.Cmap.Set(k, v)
}
}
// Get
// @description "从map获取元素"
// @auth yezibin 2023-02-05 14:10:22
// @param k string "description"
// @return interface{} "description"
func (c *cmapConfig) Get(k string) interface{} {
v, ok := c.Cmap.Get(k)
if ok {
return v
} else {
return nil
}
}
4、go的原生可并发map
最后还会跟大家介绍一个go原生库里就有一个可并发读写的map,这个放在sync库
官方的文档中指出,在以下两个场景中使用 sync.Map,会比使用 map+RWMutex 的方式,性能要好得多:
1、只会增长的缓存系统中,一个 key 只写入一次而被读很多次;
2、多个 goroutine 为不相交的键集读、写和重写键值对。
原理:sync.Map结构里有两个字段,一个read,一个dirty。dirty包含read的所有字段,新增字段是写在dirty上,有个miss变量用户访问到read没有,但是dirty有的数据次数

- 空间换时间。通过冗余的两个数据结构(只读的 read 字段、可写的 dirty),来减少加锁对性能的影响。对只读字段(read)的操作不需要加锁。优先从 read 字段读取、更新、删除,因为对 read 字段的读取不需要锁。
- 动态调整。miss 次数多了之后,将 dirty 数据提升为 read,避免总是从 dirty 中加锁读取。double-checking。加锁之后先还要再检查 read 字段,确定真的不存在才操作 dirty 字段。
- 延迟删除。删除一个键值只是打标记,只有在提升 dirty 字段为 read 字段的时候才清理删除的数据。
示例代码
type syncMapConfig struct {
Smap sync.Map
}
// InitSmap
// @description "初始化sync.map"
// @auth yezibin 2023-02-05 15:43:08
// @return *syncMapConfig "description"
func InitSmap() *syncMapConfig {
return &syncMapConfig{
sync.Map{},
}
}
// Set
// @description "批量写入map"
// @auth yezibin 2023-02-05 15:43:57
// @param config map[string]interface{} "description"
func (s *syncMapConfig) Set(config map[string]interface{}) {
for k, v := range config {
s.Smap.Store(k, v)
}
}
// Get
// @description "从map里获取数据"
// @auth yezibin 2023-02-05 15:44:09
// @param k string "description"
// @return interface{} "description"
func (s *syncMapConfig) Get(k string) interface{} {
c, ok := s.Smap.Load(k)
if ok {
return c
} else {
return nil
}
}
性能对比
上面说了4种方法,处理用once这个包比较特殊(map只写一次,以后只读),其他都是可读写多次的,有可比性,那么2,3,4这三种方案的性能对比如何呢,哪种情况下该用哪种呢
标注:下面数据对比,带有相关字符的有如下含义
| 字符 | 含义 | 字符 | 含义 |
|---|---|---|---|
| Cmap | 使用了concurrent-map包 | WnR | 写和读一样多次 |
| Smap | 使用了sync.Map包 | WnRMore | 读多写少 |
| Mmap | 使用RWMutex | WMorenR | 写多读少 |
当并发=1000,对map是部分更新,且不是更新读取的字段
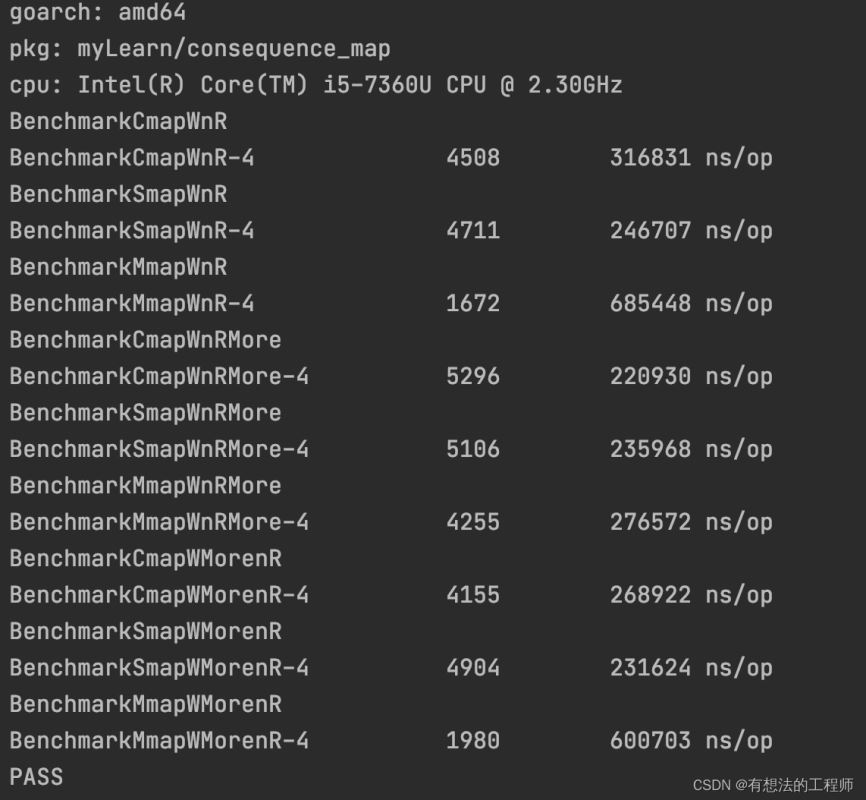
当读写一样多的时候性能: sync.Map > concurrent-map > RWMutex map
当读多写少的时候性能:concurrent-map > sync.Map > RWMutex map
当写多读少的时候性能:sync.Map > concurrent-map > RWMutex map
结论:当高并发对map进行读写时,如果写的字段和读的字段错开的时候
concurrent-map 在读多写少的情况下有优势,因为锁的粒度小
sync.Map 在写多读少的情况下有优势,因为有结构设计有优势
而读写锁因为加锁粒度大,导致高并发下性能都不是很好
当并发=1000,对map是更新和读取都是同一个字段

当读写一样多的时候性能: sync.Map > RWMutex map > concurrent-map
当读多写少的时候性能:sync.Map > RWMutex map > concurrent-map
当写多读少的时候性能:sync.Map > concurrent-map > RWMutex map
在读写都是同一个map字段的时候,sync.Map的结构优势就凸显了,因为对读和写是针对sync.Map 结构里的read字段,且不加锁;而其他两个包都是会上锁的
当并发=10,对map是部分更新,且不是更新读取的字段

当读写一样多的时候性能: RWMutex map > sync.Map > concurrent-map
当读多写少的时候性能:RWMutex map > sync.Map > concurrent-map
当写多读少的时候性能:RWMutex map > concurrent-map > sync.Map
当并发变低的情况下,RWMutex map的性能就好于其他两种,主要原因是并发低,锁的竞争和阻塞情况变少,反而是结构简单不需要占用大空间的RWMutex map形式要更好
当并发=10,对map是更新和读取都是同一个字段
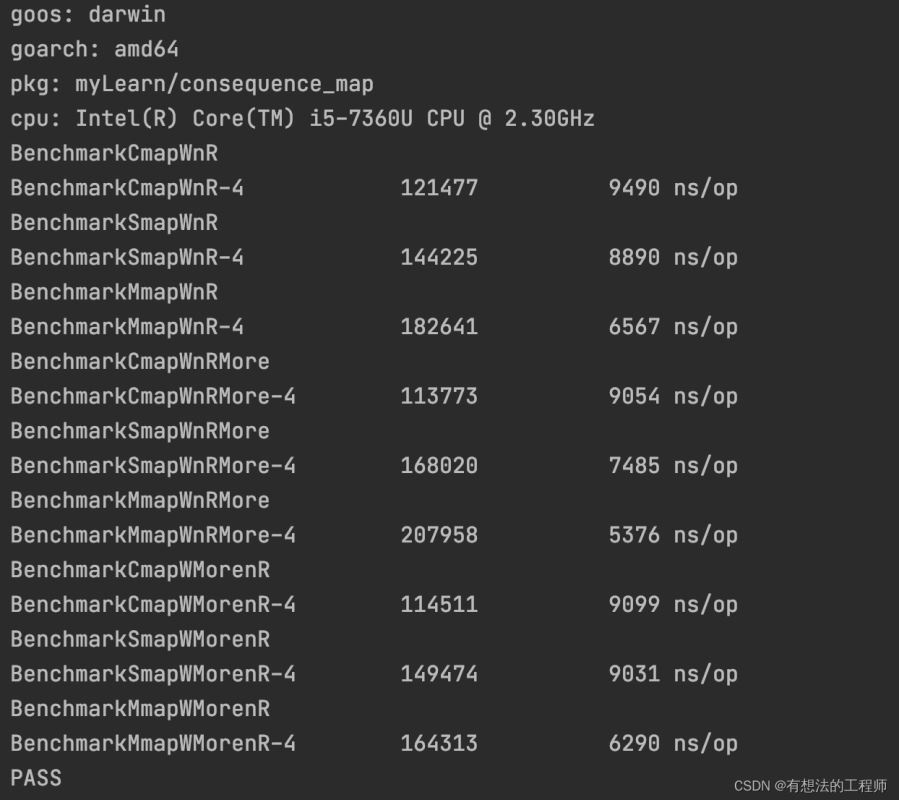
当读写一样多的时候性能: RWMutex map > sync.Map > concurrent-map
当读多写少的时候性能:RWMutex map > sync.Map > concurrent-map
当写多读少的时候性能:RWMutex map > sync.Map > concurrent-map
当并发变低的情况下,RWMutex map的性能就好于其他两种,主要原因是并发低,锁的竞争和阻塞情况变少,反而是结构简单不需要占用大空间的RWMutex map形式要更好
最终结论
选用哪个方式,其实主要先看并发数,其次看读写模式,再来选择使用哪种模式,以下表格是选用最优解
| 读多写少 | 写多读少 | |
|---|---|---|
| 并发高 | concurrent-map | sync.Map |
| 并发低 | RWMutex map | RWMutex map |
到此这篇关于如何避免go的map竞态问题的方法的文章就介绍到这了,更多相关go map竞态内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈Golang数据竞态
目录 一个数据竞态的case 检查数据竞态 解决方案 1.WaitGroup等待 2.Channel阻塞等待 3.Channel通道 4.互斥锁 典型数据竞态 1.循环计数上的竞态 2.意外共享变量 3.无保护的全局变量 4.原始无保护变量 5.未同步的发送和关闭操作 本文以一个简单事例的多种解决方案作为引子,用结构体Demo来总结各种并发读写的情况 一个数据竞态的case package main import ( "fmt" "testing" "ti
-

JS前端常见的竞态问题解决方法详解
目录 什么是竞态问题 取消过期请求 XMLHttpRequest 取消请求 fetch API 取消请求 axios 取消请求 可取消的 promise 忽略过期请求 封装指令式 promise 使用唯一 id 标识每次请求 「取消」和「忽略」的比较 「取消」更实际 「忽略」更通用 总结 什么是竞态问题 竞态问题,又叫竞态条件(race condition),它旨在描述一个系统或者进程的输出依赖于不受控制的事件出现顺序或者出现时机. 此词源自于两个信号试着彼此竞争,来影响谁先输出. 简单来说,竞
-
Java如何在临界区中避免竞态条件
当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件.导致竞态条件发生的代码区称作临界区.在临界区中使用适当的同步就可以避免竞态条件. 界区实现方法有两种,一种是用synchronized,一种是用Lock显式锁实现.synchronized 关键字,代表这个方法加锁,相当于不管哪一个线程(例如线程A),运行到这个方法时,都要检查有没有其它线程B(或者C. D等)正在用这个方法(或者该类的其他同步方法),有的话要等正在使用synchronized方法的线程B(或者C .D)运行完
-
React Suspense解决竞态条件详解
目录 前言 Suspense 执行机制 实际应用 好处:请求前置 好处:解决竞态条件 错误处理 源码 前言 在上一篇<React 之 Race Condition>中,我们最后引入了 Suspense 来解决竞态条件问题,本篇我们来详细讲解一下 Suspense. Suspense React 16.6 新增了 <Suspense> 组件,让你可以“等待”目标代码加载,并且可以直接指定一个加载的界面(像是个 spinner),让它在用户等待的时候显示. 目前,Suspense 仅支
-
go语言map字典删除操作的方法
本文实例讲述了go语言map字典删除操作的方法.分享给大家供大家参考.具体分析如下: 这里先构造了一点map,添加了青岛.济南.烟台三地的拼音和汉字字典,然后删除青岛,最后查看青岛是否还存在 复制代码 代码如下: package main import "fmt" func main(){ var pc map[string] string pc = make(map[string] string) pc["qingdao"] = "
-
Go语言用map实现堆栈功能的方法
本文实例讲述了Go语言用map实现堆栈功能的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: package stack import ( "strconv" ) type Stack struct { quenu map[int]int } func New() *Stack{ s := new(Stack) s.quenu = make(map[int]int) return s } func (s *Stack) Pus
-
java中关于Map的三种遍历方法详解
map的三种遍历方法!集合的一个很重要的操作---遍历,学习了三种遍历方法,三种方法各有优缺点~~ 复制代码 代码如下: /* * To change this template, choose Tools | Templates * and open the template in the editor. */package cn.tsp2c.liubao;import java.util.Collection;import java.util.HashMap;import java.util
-
Map获取键值,Map的几种遍历方法总结(推荐)
Map获取键值 Map以按键/数值对的形式存储数据,和数组非常相似,在数组中存在的索引,它们本身也是对象. Map的接口 Map---实现Map Map.Entry--Map的内部类,描述Map中的按键/数值对. SortedMap---扩展Map,使按键保持升序排列 关于怎么使用,一般是选择Map的子类,而不直接用Map类. 下面以HashMap为例 public static void main(String args[]) { HashMap hashmap =new HashMap();
-
Java 把json对象转成map键值对的方法
工具方法: 本文的目的是把json串转成map键值对存储,而且只存储叶节点的数据 maven 引用jar包版本: <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20090211</version> </dependency> 工具类: package com.baofoo.admin.test; /
-
Java Bean与Map之间相互转化的实现方法
概述 Apache的BeanUtils Bean工具类很强大,基本涵盖了Bean操作的所有方法.这里的话我们就讲讲两个方面,一是Bean covert to Map,二是Map covert to Bean:Bean转Map其实利用的是Java的动态性-Reflection技术,不管是什么Bean通过动态解析都是可以转成Map对象的,但前提条件是field需要符合驼峰命名不过这也是写码规范,另一个条件就是每个field需要getter.setter方法.而Map转Bean一样也是通过Reflec