python获取redis memory使用情况场景分析
目录
- 一、环境搭建
- 二、代码实现
- 1、StrictRedis vs Redis
- 2、 实验代码
- 三、redis info
项目研发过程中,用到Python操作Redis场景,记录学习过程中的心得体会。
一、环境搭建
- Windows + Anaconda3
- 安装
redis第3方包,pip install -u redispip install -u # 升级安装
- linux下查看redis配置信息
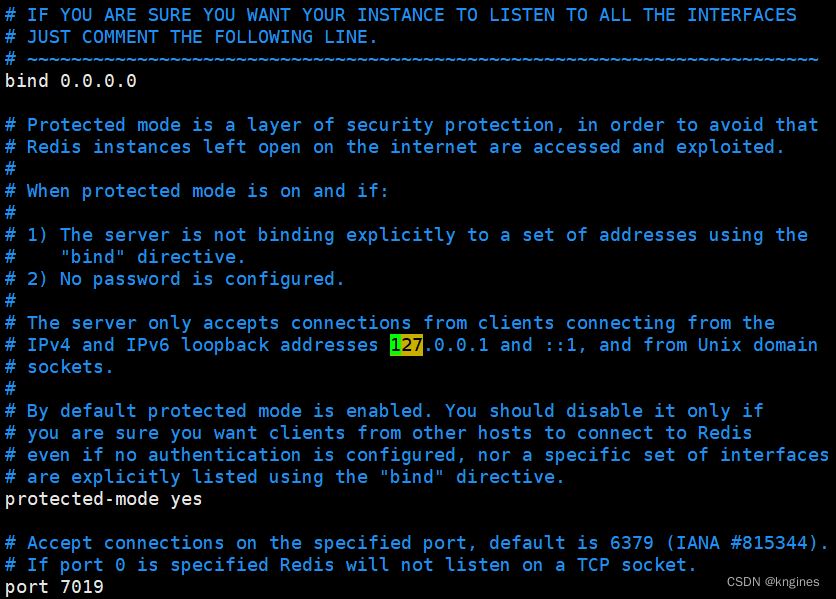
bind 127.0.0.1 # 表示只允许本地访问,无法远程连接 bind 0.0.0.0 # 表示任何ip都可以访问 protected-mode yes # 保护模式,只允许本地链接 protected-mode no # 保护模式关闭 daemonize yes # 开启守护进程模式。单进程多线程模式,redis在后台运行。 daemonize no # redis命令行界面,exit强制退出或关闭连接都会导致redis进程退出
配置示例
- 查找
redis.conf文件路径位置,find / -name 'redis.conf' - 查看
redis.conf文件,vim redis.conf
二、代码实现
1、StrictRedis vs Redis
- StrictRedis用于实现大部分官方的命令,并使用官方语法和命令;
- Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py;
- 官方推荐使用StrictRedis方法。
2、 实验代码
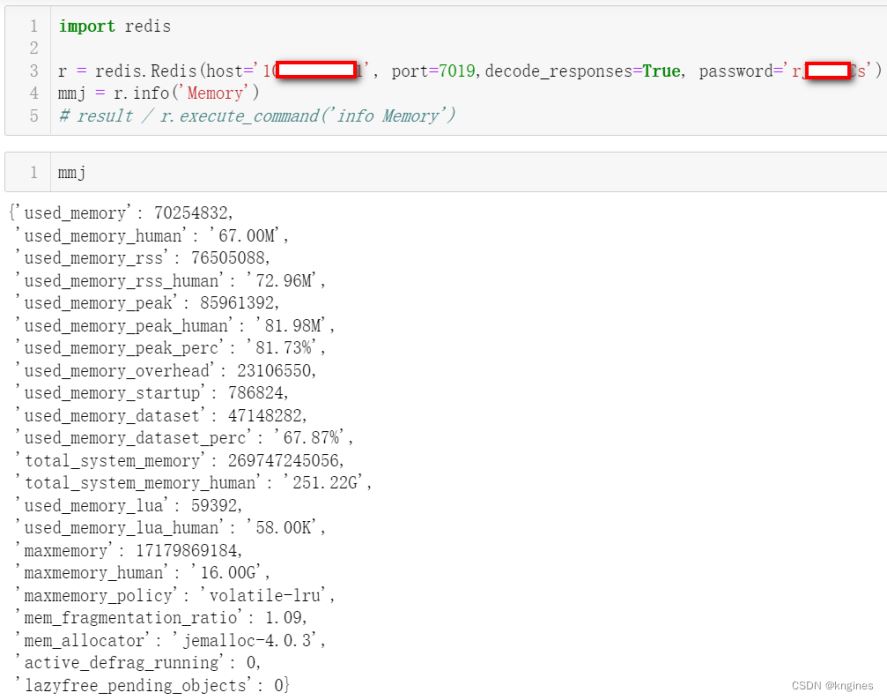
import redis
r = redis.Redis(host='10.xx.xx.201', port=7019,decode_responses=True, password='********')
mmj = r.info('Memory')
# result / r.execute_command('info Memory')
used_memory = mmj.get('used_memory')
maxmemory = mmj.get('maxmemory')
used_memory_human = mmj.get('used_memory_human')
maxmemory_human = mmj.get('maxmemory_human')
left_mem_ratio = (maxmemory - used_memory)*1.0/maxmemory
三、redis info
1、memory
| 信息项 | 解释 |
|---|---|
| used_memory | 由Redis分配器分配的内存总量,包含redis进程内部的开销和数据占用的内存,以字节为单位 |
| used_memory_human | 更直观展示分配的内存总量。 |
| used_memory_rss | 向os申请的内存大小。与 top 、 ps等命令的输出一致。 |
| used_memory_rss_human | 更直观展示向os申请的内存大小。 |
| used_memory_peak | redis的内存消耗峰值(以字节为单位) |
| used_memory_peak_human | 更直观返回redis的内存消耗峰值 |
| used_memory_peak_perc | 使用内存达到峰值内存的百分比,即(used_memory/ used_memory_peak) *100% |
| used_memory_overhead | Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。 |
| used_memory_startup | Redis服务器启动时消耗的内存 |
| used_memory_dataset | 数据占用的内存大小,即used_memory-sed_memory_overhead |
| used_memory_dataset_perc | 数据占用的内存大小的百分比,100%*(used_memory_dataset/(used_memory-used_memory_startup)) |
| total_system_memory | 整个系统内存 |
| total_system_memory_human | 以更直观的格式显示整个系统内存 |
| used_memory_lua | Lua脚本存储占用的内存 |
| used_memory_lua_human | 以更直观的格式显示Lua脚本存储占用的内存 |
| maxmemory | Redis实例的最大内存配置 |
| maxmemory_human | 以更直观的格式显示Redis实例的最大内存配置 |
| maxmemory_policy | 当达到maxmemory时的淘汰策略 |
| mem_fragmentation_ratio | 碎片率,used_memory_rss/ used_memory |
| mem_allocator | 内存分配器 |
| active_defrag_running | 表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理) |
| lazyfree_pending_objects | 0表示不存在延迟释放的挂起对象 |
到此这篇关于python获取redis memory使用情况的文章就介绍到这了,更多相关python redis memory使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python交互Redis的实现
模块(redis) Ubuntu sudo pip3 install redis 使用流程 import redis # 创建数据库连接对象 r = redis.Redis(host='127.0.0.1',port=6379,db=0,password='123456') 代码示例 import redis # 1 创建redis数据库连接对象 r = redis.Redis(password='123456') # 2 使用,很多命令的返回值是字节串,需要用字符串 # 表示时,调用deco
-
python3操作redis实现List列表实例
目录 下面是具体例子详解和代码: ①lrange(key , start , stop) ②lpush(key , value) ③rpush(key , value) ④lpop(key) ⑤rpop(key) ⑥blpop(key) ⑦brpop(key) ⑧brpoplpush(source,destination,timeout) ⑨lindex(key,index) ⑩linsert(key,before|after,privot,value) ①①llen(key) ①②lpushx
-
Python redis模块的使用教程指南
目录 1.安装模块 2.连接池 3.redis 基本命令 String 4.redis 基本命令 hash 5.redis基本命令 list 6.redis基本命令 set 7.其他常用操作 8.管道 1.安装模块 Python 要使用 redis,需要先安装 redis 模块: pip install redis 测试安装: redis 取出的结果默认是字节,我们可以设定 decode_responses=True 改成字符串 r = redis.Redis(host='localhost',
-

Python操作Redis数据库的超详细教程
目录 介绍 常用数据结构 安装 连接 String 字符串(键值对) List 列表 Hash 哈希 Set 集合 Zset 有序集合 Bitmap 位图 全局函数 总结 介绍 Redis是一个开源的基于内存也可持久化的Key-Value数据库,采用ANSI C语言编写.它拥有丰富的数据结构,拥有事务功能,保证命令的原子性.由于是内存数据库,读写非常高速,可达10w/s的评率,所以一般应用于数据变化快.实时通讯.缓存等.但内存数据库通常要考虑机器的内存大小. Redis有16个逻辑数据库(db0
-
python连接读写操作redis的完整代码实例
python读写操作redis数据库 redis有16个逻辑数据库(编号db0到db15),每个逻辑数据库数据是隔离的,默认db0.选择第n个逻辑数据库,命令select n ,python连接时可指定数据库编号(0~15). 为python安装支持库: pip install redis 连接redis 第一种方式,直连: import redis def redis_opt(): redis_conn = redis.Redis(host='127.0.0.1', port=6379, pa
-
python获取redis memory使用情况场景分析
目录 一.环境搭建 二.代码实现 1.StrictRedis vs Redis 2. 实验代码 三.redis info 项目研发过程中,用到Python操作Redis场景,记录学习过程中的心得体会. 一.环境搭建 Windows + Anaconda3 安装redis第3方包,pip install -u redis pip install -u # 升级安装 linux下查看redis配置信息 bind 127.0.0.1 # 表示只允许本地访问,无法远程连接 bind 0.0.0.0 #
-
Python获取Redis所有Key以及内容的方法
一.获取所有Key # -*- encoding: UTF-8 -*- __author__ = "Sky" import redis pool=redis.ConnectionPool(host='127.0.0.1',port=6379,db=0) r = redis.StrictRedis(connection_pool=pool) keys = r.keys() print type(keys) print keys 运行结果: <type 'list'> ['fa
-
python在linux系统下获取系统内存使用情况的方法
本文实例讲述了python在linux系统下获取系统内存使用情况的方法.分享给大家供大家参考.具体如下: """ Simple module for getting amount of memory used by a specified user's processes on a UNIX system. It uses UNIX ps utility to get the memory usage for a specified username and pipe it
-
Python 私有属性和私有方法应用场景分析
类的私有属性和方法 Python是个开放的语言,默认情况下所有的属性和方法都是公开的 或者叫公有方法,不像C++和 Java中有明确的public,private 关键字来区分私有公有. Python默认的成员函数和成员变量都是公开的,类的私有属性指只有在类的内部使用的属性或方法,表现形式为以"__" 属性名或方法名以双下划线开头. class Test(object): __count = 0 # 私有属性 __count def get_count(self): return se
-
Python获取android设备cpu和内存占用情况
功能:获取android设备中某一个app的cpu和内存 环境:python和adb 使用方法:使用adb连接android设备,打开将要测试的app,执行cpu/内存代码 cpu获取代码如下:(输入参数为脚本执行时间) # coding:utf-8 ''' 获取系统total cpu ''' import os, csv import time import csv import numpy as np from matplotlib import pyplot as plt cpu_list
-
Python获取江苏疫情实时数据及爬虫分析
目录 1.引言 2.获取目标网站 3.爬取目标网站 4.解析爬取内容 4.1. 解析全国今日总况 4.2. 解析全国各省份疫情情况 4.3. 解析江苏各地级市疫情情况 5.结果可视化 6. 代码 7. 参考 1.引言 最近江苏南京.湖南张家界陆续爆发疫情,目前已波及8省22市,全国共有2个高风险地区,52个中风险地区.身在南京,作为兢兢业业的打工人,默默地成为了"苏打绿".为了关注疫情状况,今天我们用python来爬一爬疫情的实时数据. 2.获取目标网站 为了使用python来获取疫情
-
Python获取基金网站网页内容、使用BeautifulSoup库分析html操作示例
本文实例讲述了Python获取基金网站网页内容.使用BeautifulSoup库分析html操作.分享给大家供大家参考,具体如下: 利用 urllib包 获取网页内容 #引入包 from urllib.request import urlopen response = urlopen("http://fund.eastmoney.com/fund.html") html = response.read(); #这个网页编码是gb2312 #print(html.decode("
-
Python获取好友地区分布及好友性别分布情况代码详解
利用Python + wxpy 可以快速的查询自己好友的地区分布情况,以及好友的性别分布数量.还可以批量下载好友的头像,拼接成大图. 本次教程是基于上次机器人后的,所有依赖模块都可以复用上次的,还不知道的小伙伴可以戳这里. python + wxpy 机器人 准备工作 编辑器 一个注册一年以上的微信号 公共部分代码 from wxpy import * // wxpy 依赖 from PIL import Image // 二维码登录依赖 import os // 本地下载依赖 import m
-
使用this.$nextTick()获取不到数据更新后的this.$refs.xxx.及场景分析
目录 使用this.$nextTick()获取不到数据更新后的this.$refs.xxx. 补充:详解Vue中this.$nextTick()用法 使用this.$nextTick()获取不到数据更新后的this.$refs.xxx. 今天遇到了这样一个场景,在数据更新之后,使用this.$nextTick(()=>{console.log(this.$refs.xxx)}) 获取不到改dom,但是用setTimeout能够获取到,在此记录一下. 先看代码 <!--这是模板代码,父级用的v-
-
Python获取当前页面内所有链接的四种方法对比分析
本文实例讲述了Python获取当前页面内所有链接的四种方法.分享给大家供大家参考,具体如下: ''' 得到当前页面所有连接 ''' import requests import re from bs4 import BeautifulSoup from lxml import etree from selenium import webdriver url = 'http://www.testweb.com' r = requests.get(url) r.encoding = 'gb2312'