Redis脑裂导致数据丢失的解决
目录
- 1 案例
- 2 脑裂原因
- 2.1 为什么数据会丢失?
- 3 为何脑裂会导致数据丢失?
- 4 脑裂应急方案
- 5 总结
- 6 最佳实践
1 案例
主从集群有1个主库、5个从库和3个哨兵实例,突然发现客户端发送的一些数据丢了,直接影响业务层数据可靠性。
最终排查发现是主从集群中的脑裂问题导致:主从集群中,同时有两个主节点都能接收写请求。
影响
客户端不知道应往哪个主节点写数据,导致不同客户端往不同主节点写数据。严重的,脑裂会进一步导致数据丢失。
2 脑裂原因
最初问题:在主从集群中,客户端发送的数据丢失了。
2.1 为什么数据会丢失?
① 确认数据同步是否异常
在主从集群中发生数据丢失,最常见原因:主库数据还没同步到从库,结果主库故障,等从库升级为主库后,未同步数据丢了。
新写入主库的数据a=1、b=3,因为在主库故障前未同步到从库,失了。
这种数据丢失case,可直接对比主从库的复制进度差值:
master_repl_offset - slave_repl_offset
若从库的slave_repl_offset < 原主库的master_repl_offset,则可认定数据丢失是由数据同步未完成导致。
部署主从集群时,也监测了:
- 主库的master_repl_offset
- 从库上的slave_repl_offset
但发现数据丢失后,检查了新主库升级前的slave_repl_offset,以及原主库的master_repl_offset,一致,说明该升级为新主库的从库,在升级时已和原主库的数据一致。
那为啥还会出现客户端发的数据丢失?
所有数据操作都是从客户端发给Redis实例,是否可从客户端操作日志发现问题?
② 排查客户端的操作日志,发现脑裂现象
发现主从切换后的一段时间,有个客户端仍在和原主库通信,并没有和升级的新主库交互。
相当于主从集群中同时有两个主库。据此,想到主从集群故障的脑裂。但不同客户端给两个主库发送数据写操作,应只会导致新数据会分布在不同主库,而不会造成数据丢失。
思路又断了。“从原理出发是追本溯源的好方法”。脑裂是发生在主从切换过程,猜测是漏掉了主从集群切换过程中的某环节,所以,聚焦主从切换的执行过程。
③ 发现是原主库假故障导致的脑裂
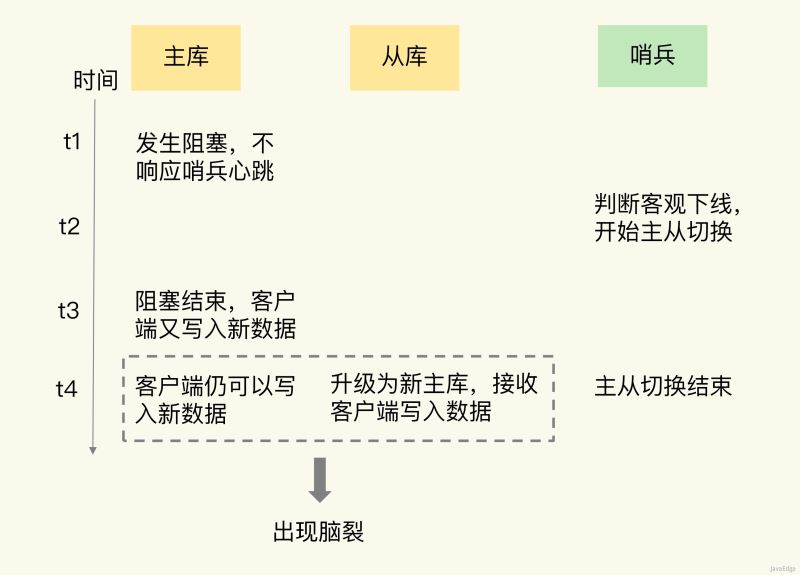
我们采用哨兵机制进行主从切换的,主从切换发生时,一定有超过预设数量(quorum配置项)的哨兵实例和主库的心跳都超时,才会把主库判断为客观下线,然后,哨兵开始执行切换操作。
哨兵切换完成后,客户端会和新主库通信,发送请求操作。
但切换过程中,既然客户端仍和原主库通信,说明原主库并未真故障(如主库进程挂掉)。怀疑主库某些原因无法处理请求,也没响应哨兵的心跳,被哨兵错判客观下线。
被判下线后,原主库又重新开始处理请求了,而此时,哨兵还没完成主从切换,客户端仍可和原主库通信,客户端发送的写操作就会在原主库写数据。
为验证原主库只是“假故障”,查看原主库服务器的资源使用监控。原主库所在机器有段时间CPU利用率飙升,因某程序把机器CPU用满,导致Redis主库无法响应心跳,这期间,哨兵就把主库判为客观下线,开始主从切换。这程序很快恢复正常,CPU使用率也下来了。原主库又继续正常服务请求。
正因原主库未真故障,在客户端操作日志中就看到和原主库通信记录。从库被升级为新主库后,主从集群里就有两个主库,这就是案例脑裂原因。
3 为何脑裂会导致数据丢失?
主从切换后,从库一旦升级为新主,哨兵就会让原主库执行slave of命令,和新主重新进行全量同步。
在全量同步执行最后阶段,原主需清空本地数据,加载新主发送的RDB文件,原主在主从切换期间保存的新写数据就丢了。

主从切换过程中,若原主只是“假故障”,会触发哨兵启动主从切换,一旦等它从假故障恢复,又开始处理请求,这就和新主共存,导致脑裂。
等哨兵让原主和新主做全量同步后,原主在切换期间保存的数据就丢了。
4 脑裂应急方案
主从集群中的数据丢失是因为发生脑裂,必须有应对脑裂方案。
问题出在原主假故障后,仍能接收请求,因此,可在主从集群机制的配置项中查找是否有限制主库接收请求的设置。Redis提供如下配置项限制主库的请求处理:
min-replicas-to-write
主库能进行数据同步的最少从库数量
min-replicas-max-lag
主从库间进行数据复制时,从库给主库发送ACK消息的最大延迟(单位s)

分别设置阈值N和T,俩配置项组合后的要求是:
- 主库连接的从库中至少有N个从库
- 和主库进行数据复制时的ACK消息延迟不能超过T秒
否则,主库就不会再接收客户端请求。
即使原主假故障,假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然就无法和从库进行ACK确认。这俩配置项组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写新数据。
等新主上线,就只有新主能接收和处理客户端请求,此时,新写的数据会被直接写到新主。而原主会被哨兵降为从库,即使它的数据被清空,也不会有新数据的丢失。
假设
- min-replicas-to-write=1
- min-replicas-max-lag设为12s
- 哨兵的down-after-milliseconds设为10s
主库因某原因卡住15s,导致哨兵判断主库客观下线,开始进行主从切换。
同时,因原主库卡住15s,没有一个从库能和原主库在12s内进行数据复制,原主库也无法接收客户端请求。
主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失。
5 总结
脑裂,主从集群中,同时有两个主能接收写请求。Redis主从切换过程中,若发生脑裂,客户端数据就会写入原主,若原主被降为从库,这些新写入数据就丢了。
脑裂主要是因为原主库发生了假故障,假故障的原因:
- 和主库部署在同一台服务器上的其他程序临时占用了大量资源(例如CPU资源),导致主库资源使用受限,短时间内无法响应心跳。其它程序不再使用资源时,主库又恢复正常
- 主库自身遇到阻塞,如处理bigkey或是发生内存swap(你可以复习下第19讲中总结的导致实例阻塞的原因),短时间内无法响应心跳,等主库阻塞解除后,又恢复正常的请求处理了。
应对脑裂,你可以在主从集群部署时,通过合理地配置参数min-slaves-to-write和min-slaves-max-lag,来预防脑裂。
在实际应用中,可能会因为网络暂时拥塞导致从库暂时和主库的ACK消息超时。在这种情况下,并不是主库假故障,我们也不用禁止主库接收请求。
6 最佳实践
假设从库有K个,可将:
- min-slaves-to-write设置为K/2+1(如果K等于1,就设为1)
- min-slaves-max-lag设置为十几秒(例如10~20s)
这个配置下,如果有一半以上的从库和主库进行的ACK消息延迟超过十几s,我们就禁止主库接收客户端写请求。
这样一来,我们可以避免脑裂带来数据丢失的情况,而且,也不会因为只有少数几个从库因为网络阻塞连不上主库,就禁止主库接收请求,增加了系统的鲁棒性。
假设:
- min-slaves-to-write 置 1
- min-slaves-max-lag 设置为 15s,哨兵的
- down-after-milliseconds 设置为 10s
哨兵主从切换需要 5s,主库因为某些原因卡住12s,此时,还会发生脑裂吗?主从切换完成后,数据会丢失吗?
主库卡住 12s,达到哨兵设定的切换阈值,所以哨兵会触发主从切换。但哨兵切换时间5s,即哨兵还未切换完成,主库就会从阻塞状态中恢复回来,且没有触发 min-slaves-max-lag 阈值,所以主库在哨兵切换剩下的 3s 内,依旧可以接收客户端的写操作,如果这些写操作还未同步到从库,哨兵就把从库提升为主库了,那么此时也会出现脑裂的情况,之后旧主库降级为从库,重新同步新主库的数据,新主库也会发生数据丢失。
即使 Redis 配置了 min-slaves-to-write 和 min-slaves-max-lag,当脑裂发生时,还是无法严格保证数据不丢失,只是尽量减少数据的丢失。
这种情况下,新主库之所以会发生数据丢失,是因为旧主库从阻塞中恢复过来后,收到的写请求还没同步到从库,从库就被哨兵提升为主库了。如果哨兵在提升从库为新主库前,主库及时把数据同步到从库了,那么从库提升为主库后,也不会发生数据丢失。但这种临界点的情况还是有发生的可能性,因为 Redis 本身不保证主从同步的强一致。
还有一种脑裂情况,就是网络分区:主库和客户端、哨兵和从库被分割成了 2 个网络,主库和客户端处在一个网络中,从库和哨兵在另一个网络中,此时哨兵也会发起主从切换,出现 2 个主库的情况,而且客户端依旧可以向旧主库写入数据。等网络恢复后,主库降级为从库,新主库丢失了这期间写操作的数据。
脑裂本质是,Redis 主从集群内部没有通过共识算法,来维护多个节点数据的强一致性。不像 Zookeeper,每次写请求必须大多数节点写成功后才认为成功。当脑裂发生时,Zookeeper 主节点被孤立,此时无法写入大多数节点,写请求会直接返回失败,因此它可以保证集群数据的一致性。
对于min-slaves-to-write,如果只有 1 个从库,当把 min-slaves-to-write 设置为 1 时,在运维时需要小心一些,当日常对从库做维护时,例如更换从库的实例,需要先添加新的从库,再移除旧的从库才可以,或者使用 config set 修改 min-slaves-to-write 为 0 再做操作,否则会导致主库拒绝写,影响到业务。
到此这篇关于Redis脑裂导致数据丢失的解决的文章就介绍到这了,更多相关Redis脑裂内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis主从集群切换数据丢失的解决方案
一.数据丢失的情况 异步复制同步丢失 集群产生脑裂数据丢失 1.异步复制丢失 对于Redis主节点与从节点之间的数据复制,是异步复制的,当客户端发送写请求给master节点的时候,客户端会返回OK,然后同步到各个slave节点中. 如果此时master还没来得及同步给slave节点时发生宕机,那么master内存中的数据会丢失: 要是master中开启持久化设置数据可不可以保证不丢失呢?答案是否定的.在master 发生宕机后,sentinel集群检测到master发生故障,重新选举新的mast
-
解决docker重启redis,mysql数据丢失的问题
官方文档: 所以 mysql应如下启动: docker run -p 3306:3306 -d -e MYSQL_ROOT_PASSWORD=密码 -v /windows盘符/指定的文件夹路径:/var/lib/mysql mysql:5.7 redis: docker run -p 6379:6379 -d -v /windows盘符/指定的文件夹路径:/data redis:5.0 redis-server --appendonly yes 多看官方文档,里面有详细的说明 补充
-
为什么断电后Redis数据不会丢失
目录 前言 Redis 持久化机制 RDB 持久化机制 RDB 机制触发条件 自动触发 RDB 机制相关配置文件 RDB 机制优点 RDB 机制缺点 AOF 持久化机制 AOF 机制如何开启 AOF 机制数据是否实时写入磁盘 AOF 文件重写 AOF 重写缓冲区 AOF 机制触发条件 AOF 机制机制优点 AOF 机制机制缺点 总结 前言 Redis 作为一款内存数据库,被广泛使用于缓存,分布式锁等场景,那么假如断电或者因其他因素导致 Reids 服务宕机,在重启之后数据会丢失吗? Redis
-
Redis脑裂导致数据丢失的解决
目录 1 案例 2 脑裂原因 2.1 为什么数据会丢失? 3 为何脑裂会导致数据丢失? 4 脑裂应急方案 5 总结 6 最佳实践 1 案例 主从集群有1个主库.5个从库和3个哨兵实例,突然发现客户端发送的一些数据丢了,直接影响业务层数据可靠性. 最终排查发现是主从集群中的脑裂问题导致:主从集群中,同时有两个主节点都能接收写请求. 影响 客户端不知道应往哪个主节点写数据,导致不同客户端往不同主节点写数据.严重的,脑裂会进一步导致数据丢失. 2 脑裂原因 最初问题:在主从集群中,客户端发送的数据丢失
-
redis scan命令导致redis连接耗尽,线程上锁的解决
使用redis scan方法无法获取connection,导致线程锁死. 0.关键字 redis springboot redistemplate scan try-with-resource 1.异常现象 应用部署后,功能正常使用,但约数小时左右,部分功能接口异常,接口请求无响应. 2.异常排查 查看堆栈信息,jstask pid.首先找到java进程pid:输出堆栈信息至log文件,jstask 30 > stask.log,看到与redis相关的日志,线程状态为waiting. "p
-
vuex页面刷新导致数据丢失的解决方案
解决vuex页面刷新导致数据丢失问题 vuex数据是存在内存当中,当页面刷新之后vuex数据自然会丢失.我们有两种方法解决该问题: 1.使用vuex-along 2.使用localStorage或者sessionStroage 1.使用vuex-along vuex-along的实质也是将vuex中的数据存放到localStorage或者sessionStroage中,只不过这个存取过程这个组件会帮我们完成,我们只需要用vuex的读取数据方式操作就可以了,简单了解一下vuex-along的使用方
-
dubbo服务使用redis注册中心的系列异常解决
目录 前言 1.不支持带密码,设置indexdb的reids 解决方法: 二,集群容错模式异常 三,jedis连接池连接的坑 四,服务超过8个应用启动卡死 文末结语 前言 dubbo支持zookeeper,reids,multicast等注册中心注册服务信息,使用redis作为注册中心时,因为reids作为注册中心使用并不广泛,早期reids由于定位内网访问,使用密码验证也不怎么重视,导致框架本身设计缺陷,会有很多坑,如1.没有考虑到带密码验证的redis,2.集群容错模式判断错误 3.不可以设
-
redis远程连接不上的解决办法
目录 问题描述: 如图所示: 解决步骤: 步骤一:注释掉redis.window.conf文件中的bind属性设置. 步骤二:把protected-mode属性设置no 问题描述: redis远程服务端运行在192.168.3.90计算机上,客户端计算机(ip:192.168.3.110)通过redsi-cli.exe客户端工具连接时,没有反应,连接不上. 如图所示: 解决步骤: 步骤一:注释掉redis.window.conf文件中的bind属性设置. 如图所示: 步骤二:把protected
-
vuex存储复杂参数(如对象数组等)刷新数据丢失的解决方法
我需要在搜索页拿到结果之后跳转到搜索结果页并携带搜索结果 尝试过几种方法之后最终采用vuex+sessionStorage结合的方法在mutations中 setResultValue(state,flag){ sessionStorage.setItem("resultValue", JSON.stringify(flag)) state.resultValue = flag } 在getters中 getResultValue getResultValue(state){ stat
-
vuex刷新后数据丢失的解决方法
导语: 我们在写vue项目的时候,经常要用到vuex作为内存来储存,但是我们存放在vuex中的数据(用户数据,当前页面的数据等等)在刷新后就会丢失,那么如何解决呢?超级简单. 1,安装vuex-persistedstate npm install --save vuex-persistedstate 2,修改store import createPersistedState from 'vuex-persistedstate' const store = new Vuex.Store({ sta
-
Redis中哈希分布不均匀的解决办法
Redis 是一个键值对数据库,其键是通过哈希进行存储的.整个 Redis 可以认为是一个外层哈希,之所以称为外层哈希,是因为 Redis 内部也提供了一种哈希类型,这个可以称之为内部哈希.当我们采用哈希对象进行数据存储时,对整个 Redis 而言,就经过了两层哈希存储. 哈希对象 哈希对象本身也是一个 key-value 存储结构,底层的存储结构也可以分为两种:ziplist(压缩列表) 和 hashtable(哈希表).这两种存储结构也是通过编码来进行区分: 编码属性 描述 object e
-
idea中使用Inputstream流导致中文乱码解决方法
1.问题描述 idea中使用Inputstream流导致中文乱码解决方法,当然也不一定就是输入流,可能输出流或者其他用到了流相关的字符的都可能出现乱码,这里有一个可能的解决办法. 2. 解决办法 ① idea中找到下面的路径 File--Settings--Editor--File Encodings ② Transparent native-to-ascii conversion把这个前面勾上,重新创建文件,执行就OK 很多朋友遇到Java FileInputStream读中文乱码问题,下面小
-
redis使用不当导致应用卡死bug的过程解析
目录 top jstack 查看堆内存 执行thread命令 首先说下问题现象:内网sandbox环境API持续1周出现应用卡死,所有api无响应现象 刚开始当测试抱怨环境响应慢的时候 ,我们重启一下应用,应用恢复正常,于是没做处理.但是后来问题出现频率越来越频繁,越来越多的同事开始抱怨,于是感觉代码可能有问题,开始排查. 首先发现开发的本地ide没有发现问题,应用卡死时候数据库,redis都正常,并且无特殊错误日志.开始怀疑是sandbox环境机器问题(测试环境本身就很脆!_!) 于是ssh上