go defer return panic 执行顺序示例详解
目录
- 一、函数中有panic
- 二、然后将代码中 panic注释掉再执行
- 三、函数返回的是匿名参数
- 四、总结:
- ps:go语言错误和异常处理,panic、defer、recover的执行顺序
- 一、panic()和recover()
根据代码实例运行结果来总结
说明:定义一个函数,有多个defer (用于判断多个defer执行顺序),有panic和 return (判断与defer对比执行顺序)
一、函数中有panic
package main
import "fmt"
func main() {
fmt.Println("main func start")
defer func(){
fmt.Println("main defer func 1")
}()
s := test()
fmt.Println("main get test() return:",s)
}
func test() (str string) {
defer func() {
//捕获panic
if msg := recover(); msg != nil {
fmt.Println("test defer func1 捕获到错误:",msg)
}
str = "bbb"
}()
defer func(){
fmt.Println("test defer func2")
}()
defer func(){
fmt.Println("test defer func3")
}()
str = "aaa"
fmt.Println("panic抛出前")
panic("test painc")
fmt.Println("panic抛出后")
return str
}
执行结果:
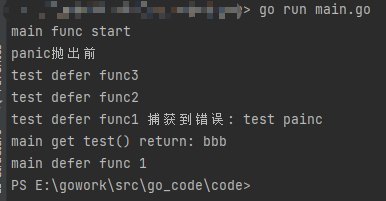
根据执行结果可知道:
- 函数内多个defer执行顺序是 先入后出(即入栈)
- panic 先于defer执行,不然defer函数内捕获不到错误
- panic执行后 后续逻辑及return 没有执行
二、然后将代码中 panic注释掉再执行
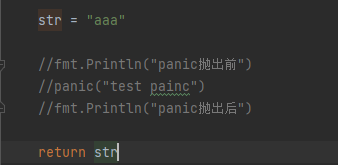
执行结果:
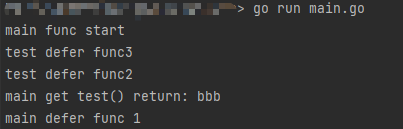
根据执行结果可知:
- defer中可以修改返回值,注意:前提是函数的返回值不是匿名的
三、函数返回的是匿名参数
package main
import "fmt"
func main() {
fmt.Println("main func start")
defer func(){
fmt.Println("main defer func 1")
}()
s := test()
fmt.Println("main get test() return:",s)
}
func test() (string) {
str := "aaa"
defer func() {
//捕获panic
if msg := recover(); msg != nil {
fmt.Println("test defer func1 捕获到错误:",msg)
}
str = "ccc"
}()
defer func(){
fmt.Println("test defer func2")
}()
defer func(){
fmt.Println("test defer func3")
}()
fmt.Println("panic抛出前")
panic("test painc")
fmt.Println("panic抛出后")
return str
}
执行结果:
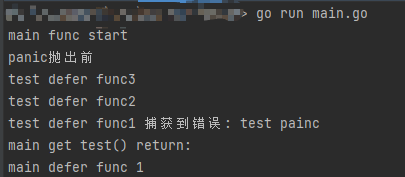
然后注释掉panic执行结果
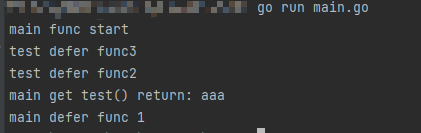
根据执行结果:
- 函数返回参数是匿名的 defer无法修改
- 函数中有panic 匿名的返回值是零值,因为return赋值得不到执行,defer又修改不到返回值
***注意(非常重要):这里需要提到的是函数的return是分为两个步骤:return最先执行,先将结果写入返回值中(即赋值);接着defer开始执行一些收尾工作;最后函数携带当前返回值退出(即返回值)。
有panic的时候,return第一步没有执行到,无法将结果写入返回值中,那么函数退出前则只能返回参数类型的零值
四、总结:
- 函数中有多个defer,则是按先进后出(压栈)执行
- panic先于defer执行,所以能通过defer中去捕获panic错误
- defer可以修改函数的返回参数,前提是函数返回的参数不是匿名的
- 函数执行出现panic那么return得不到执行,如果返回参数是匿名的,那么函数最终返回的是返回参数的类型零值,如果返回参数不是匿名的,在panic前有对返回参数赋值,那么就能返回这个值,如果defer有对其修改,那么返回值则是defer修改的。
ps:go语言错误和异常处理,panic、defer、recover的执行顺序
一、panic()和recover()
Golang中引入两个内置函数panic和recover来触发和终止异常处理流程,同时引入关键字defer来延迟执行defer后面的函数。 一直等到包含defer语句的函数执行完毕时,延迟函数(defer后的函数)才会被执行,而不管包含defer语句的函数是通过return的正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。 当程序运行时,如果遇到引用空指针、下标越界或显式调用panic函数等情况,则先触发panic函数的执行,然后调用延迟函数。调用者继续传递panic,因此该过程一直在调用栈中重复发生:函数停止执行,调用延迟执行函数等。如果一路在延迟函数中没有recover函数的调用,则会到达该协程的起点,该协程结束,然后终止其他所有协程,包括主协程(类似于C语言中的主线程,该协程ID为1)。
panic: 1、内建函数 2、假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行 3、返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行,这里的defer 有点类似 try-catch-finally 中的 finally 4、直到goroutine整个退出,并报告错误
recover: 1、内建函数 2、用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为 3、一般的调用建议 a). 在defer函数中,通过recever来终止一个gojroutine的panicking过程,从而恢复正常代码的执行 b). 可以获取通过panic传递的error
简单来讲:go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
错误和异常从Golang机制上讲,就是error和panic的区别。很多其他语言也一样,比如C++/Java,没有error但有errno,没有panic但有throw。
Golang错误和异常是可以互相转换的:
错误转异常,比如程序逻辑上尝试请求某个URL,最多尝试三次,尝试三次的过程中请求失败是错误,尝试完第三次还不成功的话,失败就被提升为异常了。异常转错误,比如panic触发的异常被recover恢复后,将返回值中error类型的变量进行赋值,以便上层函数继续走错误处理流程。
什么情况下用错误表达,什么情况下用异常表达,就得有一套规则,否则很容易出现一切皆错误或一切皆异常的情况。
以下给出异常处理的作用域(场景):
空指针引用下标越界除数为0不应该出现的分支,比如default输入不应该引起函数错误
其他场景我们使用错误处理,这使得我们的函数接口很精炼。对于异常,我们可以选择在一个合适的上游去recover,并打印堆栈信息,使得部署后的程序不会终止。
说明: Golang错误处理方式一直是很多人诟病的地方,有些人吐槽说一半的代码都是"if err != nil { / 打印 && 错误处理 / }",严重影响正常的处理逻辑。当我们区分错误和异常,根据规则设计函数,就会大大提高可读性和可维护性。
代码演示:
package main
import "fmt"
func main() {
/*
panic:词义"恐慌",
recover:"恢复"
go语言利用panic(),recover(),实现程序中的极特殊的异常的处理
panic(),让当前的程序进入恐慌,中断程序的执行
recover(),让程序恢复,必须在defer函数中执行
*/
defer func(){
if msg := recover();msg != nil{
fmt.Println(msg,"程序回复啦。。。")
}
}()
funA()
defer myprint("defer main:3.....")
funB()
defer myprint("defer main:4.....")
fmt.Println("main..over。。。。")
}
func myprint(s string){
fmt.Println(s)
}
func funA(){
fmt.Println("我是一个函数funA()....")
}
func funB(){//外围函数
fmt.Println("我是函数funB()...")
defer myprint("defer funB():1.....")
for i:= 1;i<=10;i++{
fmt.Println("i:",i)
if i == 5{
//让程序中断
panic("funB函数,恐慌了")
}
}//当外围函数的代码中发生了运行恐慌,只有其中所有的已经defer的函数全部都执行完毕后,该运行恐慌才会真正被扩展至调用处。
defer myprint("defer funB():2.....")
}
运行结果:
我是一个函数funA()....
我是函数funB()...
i: 1
i: 2
i: 3
i: 4
i: 5
defer funB():1.....
defer main:3.....
funB函数,恐慌了 程序回复啦。。。
可见当外围函数的代码中发生了运行恐慌,只有其中所有的已经defer的函数全部都执行完毕后,该运行恐慌才会真正被扩展至调用处。
到此这篇关于go defer return panic 执行顺序的文章就介绍到这了,更多相关go defer return panic 执行顺序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
聊聊golang中多个defer的执行顺序
golang 中多个 defer 的执行顺序 引用 Ture Go 中的一个示例: package main import "fmt" func main() { fmt.Println("counting") for i := 0; i < 10; i++ { defer fmt.Println(i) } fmt.Println("done") } 程序执行结果为: counting done 9 8 7 6 5 4 3 2 1 0 从结
-
Golang控制协程执行顺序方法详解
目录 循环控制 通道控制 互斥锁 async.Mutex 在 Go 里面的协程执行实际上默认是没有严格的先后顺序的.由于 Go 语言 GPM 模型的设计理念,真正执行实际工作的实际上是 GPM 中的 M(machine) 执行器,而我们的协程任务 G(goroutine) 协程需要被 P(produce) 关联到某个 M 上才能被执行.而每一个 P 都有一个私有队列,除此之外所有的 P 还共用一个公共队列.因此当我们创建了一个协程之后,并不是立即执行,而是进入队列等待被分配,且不同队列之间没有顺
-
Go中init()执行顺序详解
目录 概述 init()函数 执行时机 概述 init()一般用来做一些初始化工作, go允许定义多个init(),根据init()重复场景不同,可以分为 同文件 单文件中定义多个init() 同模块 同模块下不同文件中定义了多个init() 子模块 本模块和子模块都包含init() 跨模块 多个被引用模块中均含init() 要点秘诀: 涉及引用时,先加载的先执行 同一文件中,先定义的先执行 init()函数 init()函数没有参数,也没有返回值. init()函数在程序运行时,自动自动被调用
-
Go语言defer与return执行的先后顺序详解
目录 先了解什么是defer defer 的用法 那么defer 和 return有什么联系? 原因: 更进一步理解 省流小结 先了解什么是defer Go语言中的defer与return执行的先后顺序 Go语言的 defer 语句会将其后面跟随的语句进行延迟处理,在 defer 归属的函数即将返回时,将延迟处理的语句按 defer 的逆序进行执行.也就是说,先被 defer 的语句最后被执行,最后被 defer 的语句,最先被执行.(与栈的先入后出是一个道理,也可以将其理解为入栈和出栈) 举一
-
go defer return panic 执行顺序示例详解
目录 一.函数中有panic 二.然后将代码中 panic注释掉再执行 三.函数返回的是匿名参数 四.总结: ps:go语言错误和异常处理,panic.defer.recover的执行顺序 一.panic()和recover() 根据代码实例运行结果来总结 说明:定义一个函数,有多个defer (用于判断多个defer执行顺序),有panic和 return (判断与defer对比执行顺序) 一.函数中有panic package main import "fmt" func main
-
Python中实例化class的执行顺序示例详解
前言 本文主要介绍了关于Python实例化class的执行顺序的相关内容,下面话不多说了,来一起看看详细的介绍吧 Python里对类的实例化时有怎样的顺序 一般来说一个类里面有类变量和方法,比如我们定义一个名为A的类 class A(): bar = "my lover love me" def __init__(self, name): print('A的class' ,self.__class__, name) 我们在这个类里面定义了一个类变量bar和一个构造方法__init__,
-
Go语言defer的一些神奇规则示例详解
目录 测试题 分析 规则一当defer被声明时,其参数就会被实时解析 规则二 defer可能操作主函数的具名返回值 规则三 延迟函数执行按后进先出顺序执行 坑实例 测试题 defer有一些规则,如果不了解,代码实现的最终结果会与预期不一致.对于这些规则,你了解吗? 这是关于defer使用的代码,可以先考虑一下返回值. package main import ( "fmt" ) /** * @Author: Jason Pang * @Description: 快照 */ func de
-
语言编程花絮内建构建顺序示例详解
目录 1 构建 顺序 1.1 交叉编译 1.2 设置 2 构建测试支持 1 构建 顺序 依据词法名顺序 当导入一个包,且这个包 定义了 init(), 那么导入时init()将被执行. 具体执行顺序: 全局变量定义时的函数 import 执行导入 -> cont 执行常量 --> var 执行变量 --> 执行初始化 init() --> 执行 main() ----> main import pk1 ---> pk1 const ... import pk2 ---&
-

DOM事件阶段以及事件捕获与事件冒泡先后执行顺序(图文详解)
俗话说的好,好记性不如个烂笔头,这么多技术文章如果不去吃透,技术点很快就容易忘掉,下面是小编平时浏览的技术文章,整理的笔记,分享给大家. 开发过程中我们都希望使用别人成熟的框架,因为站在巨人的肩膀上会使得我们开发的效率大幅度提升.不过,我们也应该.必须了解其基本原理.比如DOM事件,jquery框架帮我们为我们封装和抽象了各浏览器的差异行为,为事件处理带来了极大的便利.不过浏览器逐步走向统一和标准化,我们可以更加安全地使用官方规范的接口.因为只有获得众多开发者的芳心,浏览器才会走得更远.正如我们
-
对java for 循环执行顺序的详解
如下所示: for(表达式1;表达式2;表达式3) { //循环体 } 先执行"表达式1",再进行"表达式2"的判断,判断为真则执行 "循环体",循环体执行完以后执行表达式3. 例如 for(int i=0;i<2;i++){ //TODO } 先执行 int i = 0; 然后 判断 i<2 然后执行函数体 最后执行i++ 然后轮回到判断i<2 int[] arr = new int[3]; int j; arr[0] = 1
-
golang gorm更新日志执行SQL示例详解
目录 1. 更新日志 1.1. v1.0 1.1.1. 破坏性变更 gorm执行sql 1. 更新日志 1.1. v1.0 1.1.1. 破坏性变更 gorm.Open返回类型为*gorm.DB而不是gorm.DB 更新只会更新更改的字段 大多数应用程序不会受到影响,只有当您更改回调中的更新值(如BeforeSave,BeforeUpdate)时,应该使用scope.SetColumn,例如: func (user *User) BeforeUpdate(scope *gorm.Scope) {
-
C#类继承中构造函数的执行序列示例详解
前言 大家都知道类的继承规则: 1.派生类自动包含基类的所有成员.但对于基类的私有成员,派生类虽然继承了,但是不能在派生类中访问. 2.所有的类都是按照继承链从顶层基类开始向下顺序构造.最顶层的基类是System.Object类,所有的类都隐式派生于它.只要记住这条规则,就能理解派生类在实例化时对构造函数的调用过程. 不知道大家在使用继承的过程中有木有遇到过调用构造函数时没有按照我们预期的那样执行呢?一般情况下,出现这样的问题往往是因为类继承结构中的某个基类没有被正确实例化,或者没有正确给基类构
-
oracle select执行顺序的详解
SQL Select语句完整的执行顺序:1.from子句组装来自不同数据源的数据:2.where子句基于指定的条件对记录行进行筛选:3.group by子句将数据划分为多个分组:4.使用聚集函数进行计算:5.使用having子句筛选分组:6.计算所有的表达式:7.使用order by对结果集进行排序. oracle 语句提高查询效率的方法 1:.. where column in(select * from ... where ...); 2:... where exists (select '