Python机器学习利用鸢尾花数据绘制ROC和AUC曲线
目录
- 一、ROC与AUC
- 1.ROC
- 2.AUC
- 二、代码实现
- 效果
一、ROC与AUC
很多学习器是为了测试样本产生的一个实值或概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类。主要看需要建立的模型侧重于想用在测试数据的泛华性能的好坏。排序本身的质量好坏体系了综合考虑学习去在不同任务下的“期望泛化性能”的好坏。ROC曲线则是从这个角度出发来研究学习器泛化性能。
1.ROC
ROC的全称是“受试者工作特征”曲线,与P-R曲线相似。与P-R曲线使用查准率、查全率为纵、横坐标不同,ROC曲线的纵轴是“真正例率”{简称TPR),横轴是“假正例率”(简称FPR)二者分别定义为:
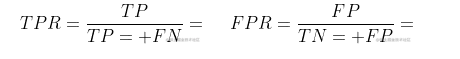
ROC曲线图以真正例率为Y轴,假正例率为X轴。
2.AUC
进行检验判定ROC曲线性能的合理判据是比较ROC曲线下的面积,即AUC。从定义知AUC可通过对ROC曲线下各部分的面积求和而得,AUC可估算为:
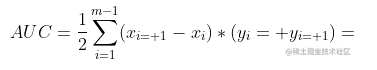
从形式化看,AUC考虑的是样本预测的排序质量,因此它与排序误差有紧密联系。因此存在排序损失。
二、代码实现
形式基本和P-R曲线差不多,只是几个数值要改一下。
代码如下(示例):
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
from itertools import cycle
from sklearn.preprocessing import label_binarize #标签二值化LabelBinarizer,可以把yes和no转化为0和1,或是把incident和normal转化为0和1。
import numpy as np
from sklearn.multiclass import OneVsRestClassifier
iris = datasets.load_iris()
# 鸢尾花数据导入
X = iris.data
#每一列代表了萼片或花瓣的长宽,一共4列,每一列代表某个被测量的鸢尾植物,iris.shape=(150,4)
y = iris.target
#target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,所以数组的长度是150,所有不同值只有三个
random_state = np.random.RandomState(0)
#给定状态为0的随机数组
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
#添加合并生成特征测试数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.25,
random_state=0)
#根据此模型训练简单数据分类器
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True,
random_state=random_state))#线性分类支持向量机
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
#用一个分类器对应一个类别, 每个分类器都把其他全部的类别作为相反类别看待。
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
#计算ROC曲线面积
roc_auc[i] = auc(fpr[i], tpr[i])
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
import matplotlib.pyplot as plt
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.ylim([0.0, 1.0])
plt.xlim([0.0, 1.0])
plt.legend(loc="lower right")
plt.title("Precision-Recall")
plt.show()
效果
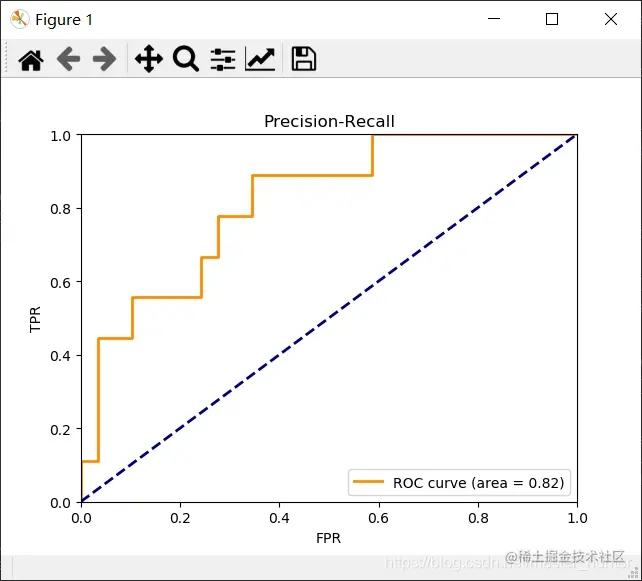
以上就是Python机器学习利用鸢尾花数据绘制ROC和AUC曲线的详细内容,更多关于Python数据绘制ROC AUC的资料请关注我们其它相关文章!
相关推荐
-

python人工智能human learn绘图可创建机器学习模型
目录 什么是 human-learn 安装 human-learn 互动绘图 创建模型并进行预测 预测新数据 解释结果 预测和评估测试数据 结论 如今,数据科学家经常给带有标签的机器学习模型数据,以便它可以找出规则. 这些规则可用于预测新数据的标签. 这很方便,但是在此过程中可能会丢失一些信息.也很难知道引擎盖下发生了什么,以及为什么机器学习模型会产生特定的预测. 除了让机器学习模型弄清楚所有内容之外,还有没有一种方法可以利用我们的领域知识来设置数据标记的规则? 是的,这可以通过 human-l
-
python机器学习Github已达8.9Kstars模型解释器LIME
目录 LIME 代 码 对单个样本进行预测解释 适用问题 简单的模型例如线性回归,LR等模型非常易于解释,但在实际应用中的效果却远远低于复杂的梯度提升树模型以及神经网络等模型. 现在大部分互联网公司的建模都是基于梯度提升树或者神经网络模型等复杂模型,遗憾的是,这些模型虽然效果好,但是我们却较难对其进行很好地解释,这也是目前一直困扰着大家的一个重要问题,现在大家也越来越加关注模型的解释性. 本文介绍一种解释机器学习模型输出的方法LIME.它可以认为是SHARP的升级版,Github链接:https
-
Python机器学习性能度量利用鸢尾花数据绘制P-R曲线
目录 一.性能度量 1.错误率与精度 2.查准率.查全率与F1 二.代码实现: 1.基于具体二分类问题算法实现代码: 2.利用鸢尾花绘制P-R曲线 效果: 一.性能度量 性能度量目的是对学习期的泛华能力进行评估,性能度量反映了任务需求,在对比不同算法的泛华能力时,使用不同的性能度量往往会导致不同的评判结果.常用度量有均方误差,错误率与精度,查准率与查全率等. 1.错误率与精度 这两种度量既适用于二分类任务,也适用于多分类任务.错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样
-
Python机器学习利用随机森林对特征重要性计算评估
目录 1 前言 2 随机森林(RF)简介 3 特征重要性评估 4 举个例子 5 参考文献 1 前言 随机森林是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能,因此,随机森林也被誉为"代表集成学习技术水平的方法". 2 随机森林(RF)简介 只要了解决策树的算法,那么随机森林是相当容易理解的.随机森林的算法可以用如下几个步骤概括: 1.用有抽样放回的方法(bootstrap)从样本集中选取n个样本作为一个
-
python机器学习算法与数据降维分析详解
目录 一.数据降维 1.特征选择 2.主成分分析(PCA) 3.降维方法使用流程 二.机器学习开发流程 1.机器学习算法分类 2.机器学习开发流程 三.转换器与估计器 1.转换器 2.估计器 一.数据降维 机器学习中的维度就是特征的数量,降维即减少特征数量.降维方式有:特征选择.主成分分析. 1.特征选择 当出现以下情况时,可选择该方式降维: ①冗余:部分特征的相关度高,容易消耗计算性能 ②噪声:部分特征对预测结果有影响 特征选择主要方法:过滤式(VarianceThreshold).嵌入式(正
-
python机器学习pytorch自定义数据加载器
目录 正文 1. 加载数据集 2. 迭代和可视化数据集 3.创建自定义数据集 3.1 __init__ 3.2 __len__ 3.3 __getitem__ 4. 使用 DataLoaders 为训练准备数据 5.遍历 DataLoader 正文 处理数据样本的代码可能会逐渐变得混乱且难以维护:理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化.PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.util
-
Python机器学习入门(二)数据理解
目录 1.数据导入 1.1使用标准Python类库导入数据 1.2使用Numpy导入数据 1.3使用Pandas导入数据 2.数据理解 2.1数据基本属性 2.1.1查看前10行数据 2.1.2查看数据维度,数据属性和类型: 2.1.3查看数据描述性统计 2.2数据相关性和分布分析 2.2.1数据相关矩阵 2.2.2数据分布分析 3.数据可视化 3.1单一图表 3.1.1直方图 3.1.2密度图 3.1.3箱线图 3.2多重图表 3.2.1相关矩阵图 3.2.2散点矩阵图 总结 统计学是什么?概
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
Python+Pyecharts实现散点图的绘制
目录 第1关:Scatter:散点图(一) 编程要求 代码 测试说明 第2关:Scatter:散点图(二) 编程要求 代码 测试说明 第3关:Scatter:散点图(三) 编程要求 代码 测试说明 第1关:Scatter:散点图(一) 编程要求 根据以上介绍,在右侧编辑器补充代码,绘制给定数据的散点图,要求: 画布大小初始化为宽 1600 像素,高 1000 像素 X 轴数据设置为 x_data 添加 Y 轴数据.系列名称设置为空,数据使用 y_data,标记的大小设置为20,不显示标签 X 轴
-
Python机器学习入门(二)之Python数据理解
目录 1.数据导入 1.1使用标准Python类库导入数据 1.2使用Numpy导入数据 1.3使用Pandas导入数据 2.数据理解 2.1数据基本属性 2.1.1查看前10行数据 2.1.2查看数据维度,数据属性和类型: 2.1.3查看数据描述性统计 2.2数据相关性和分布分析 2.2.1数据相关矩阵 2.2.2数据分布分析 3.数据可视化 3.1单一图表 3.1.1直方图 3.1.2密度图 3.1.3箱线图 3.2多重图表 3.2.1相关矩阵图 3.2.2散点矩阵图 总结 统计学是什么?概
-
python如何利用matplotlib绘制并列双柱状图并标注数值
目录 项目场景: 代码: 效果图: 扩展功能及代码: 补充:Python画图实现同一结点多个柱状图 总结 项目场景: Python项目需要画两组数据的双柱状图,以下以一周七天两位小朋友吃糖颗数为例进行演示,用matplotlib库实现 代码: import matplotlib import matplotlib.pyplot as plt import numpy as np def drawHistogram(): matplotlib.rc("font", family='Mic
-
Python利用networkx画图绘制Les Misérables人物关系
目录 数据集介绍 数据处理 画图 networkx自带的数据集 完整代码 数据集介绍 <悲惨世界>中的人物关系图,图中共77个节点.254条边. 数据集截图: 打开README文件: Les Misérables network, part of the Koblenz Network Collection =========================================================================== This directory con
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行