全栈轻量级搭配之Remix Prisma Sqlite使用分析
目录
- 一、为什么是 Remix/Prisma/Sqlite ?
- 二、Prisma 命令提前看
- 三、在 Remix 中添加 Sqlite 和 Prisma 的流程如下:
- 1、安装依赖
- 2、用 sqlite 初始化 prisma
- 3、在 Schema 文件中添加模型
- 4、生成客户端代码
- 5、使用迁移命令
- 6、在 studio 中查看
- 7、在 Remix 中使用
- ①. 对外暴露 db
- ②. 抽象模型层
- ③. 在 action/loader 中使用模型层操作数据库
- ④. 额外的 seed 初始化
- 四、流程总结
- 五、小结
一、为什么是 Remix/Prisma/Sqlite ?
最主要的一个原因就是轻量级别,轻量级体现在只需要一个 Remix 服务即可。
- Remix 轻量级 React 全栈框架
- Prisma 轻量级 ORM 库
- Sqlite 嵌入式无需启动服务的数据库
二、Prisma 命令提前看
如果你还不熟悉 Prisma 的常用命令,那么下面盘点的常用命令,提前熟悉,后面会用到:
| 命令 | 说明 |
|---|---|
| prisma init | 初始化一个新的Prisma项目 |
| prisma migrate dev | 将数据模型应用于数据库 |
| prisma migrate reset | 回滚数据库到最初状态 |
| prisma studio | 启动一个Web界面,用于查看和修改数据库中的数据 |
| prisma generate | 生成Prisma客户端代码,用于连接和操作数据库 |
| prisma format | 格式化Prisma模型文件 |
| prisma validate | 验证Prisma模型文件的正确性 |
| prisma db seed | 开发环境将种子数据添加到数据库中 |
| npx prisma migrate reset | 重置您的数据库并将其恢复到迁移历史中的最初状态 |
三、在 Remix 中添加 Sqlite 和 Prisma 的流程如下:

快速初始化一个 Remix 项目:
pnpm dlx create-remix@latest <app_name>
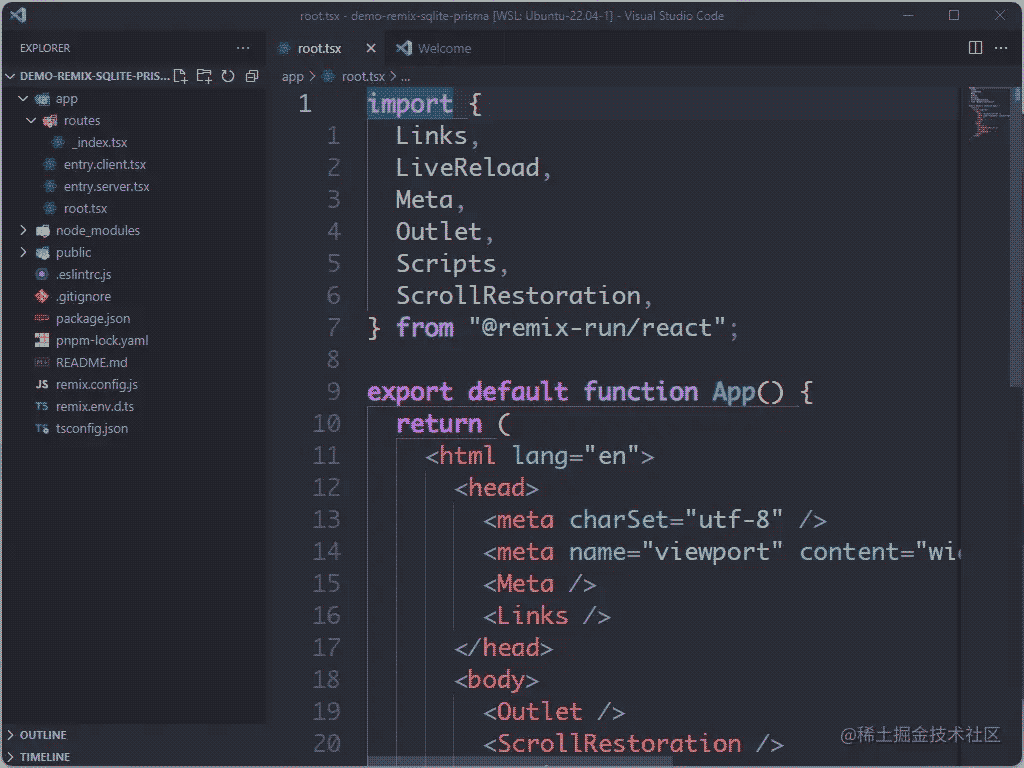
1、安装依赖
pnpm install prisma -g # 全局安装
2、用 sqlite 初始化 prisma
prisma init --datasource-provider sqlite
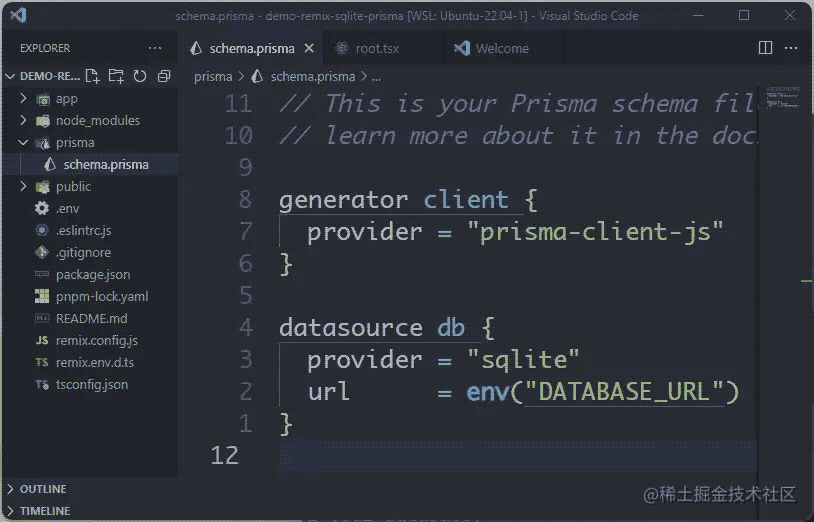
命令自动生成文件如下:
- .env 文件
DATABASE_URL="file:./dev.db"
- prisma/schema.prisma 文件
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
3、在 Schema 文件中添加模型
model User {
id Int @id @default(autoincrement())
name String
email String @unique
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
content String
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
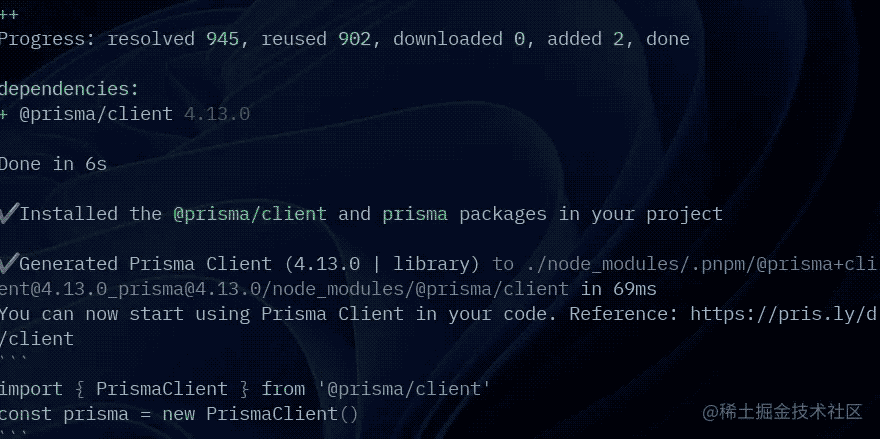
4、生成客户端代码
"prisma generate" 根据 Prisma schema 文件生成 Prisma Client 代码,该代码提供了一种类型安全的方法来访问数据库,简化了应用程序与数据库交互的过程,减少了手动编写重复代码的工作量。
5、使用迁移命令
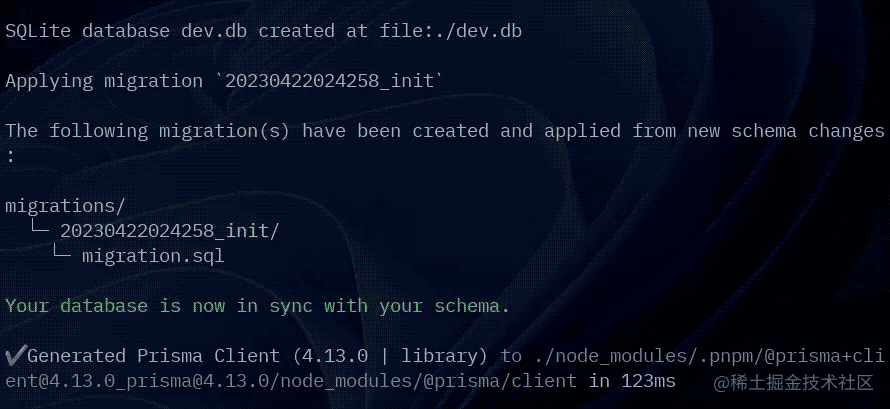
npx prisma migrate dev --name init
每一次 Schema 发生变化的时候,都要调用此命令生成新的迁移文件(生成 sql 文件,数据文件件,安装包)
生成文件:
├── dev.db
├── dev.db-journal
├── migrations
│ ├── 2x23x42x1x3x4x_init
│ │ └── migration.sql
│ └── migration_lock.toml
同时自动安装了 npm 包:
- prisma
- @prisma/client
6、在 studio 中查看
npx prisma studio
会启动一个 web 服务,在浏览器中操作数据库,不需要一个单独的客户端。
- 初始界面
- 模型中
在 stdio 也可以对数据库进行相应的增删改查工作。
7、在 Remix 中使用
①. 对外暴露 db
- db.server.ts 文件
import { PrismaClient } from "@prisma/client";
let prisma: PrismaClient;
declare global {
var __db__: PrismaClient;
}
if (process.env.NODE_ENV === "production") {
prisma = new PrismaClient();
} else {
if (!global.__db__) {
global.__db__ = new PrismaClient();
}
prisma = global.__db__;
prisma.$connect();
}
export { prisma };
②. 抽象模型层
在 app/models 下面定义模型,以是一个示例:
import { prisma } from "~/db.server";
export async function getUserById(id: User["id"]) {
return prisma.user.findUnique({ where: { id } });
}
export async function getUserByEmail(email: User["email"]) {
return prisma.user.findUnique({ where: { email } });
}
③. 在 action/loader 中使用模型层操作数据库
import { createUser, getUserByEmail } from "~/models/user.server";
export const action = async ({ request }: ActionArgs) => {
// ...
const existingUser = await getUserByEmail(email);
// ...
const user = await createUser(email, password);
}
④. 额外的 seed 初始化
如果需要在初始化的时候,初始化一些数据,那么可以定义 prisma/seed.ts 文件。
import { PrismaClient } from "@prisma/client";
const db = new PrismaClient();
async function seed() {
// use db write data ...
}
seed();
然后在 package.json 中定义 seed 字段
{
"name": "my-project",
"version": "1.0.0",
"prisma": {
"seed": "ts-node prisma/seed.ts"
},
"devDependencies": {
"@types/node": "^14.14.21",
"ts-node": "^9.1.1",
"typescript": "^4.1.3"
}
}
然后配合命令: npx prisma db seed 初始出初始化数据
四、流程总结
- prisma init --source-provider sqlite
- 添加 model
- 生成客户端
- prisma migrate dev --name init
- npx prisma studio
- 使用客户端操作
- 外额的 seed 初始化
五、小结
prisma 能提供了新的 ORM 操作数据库,cli 命令生成的内容相对较多。熟悉之后会变得简单容易。并且提供 studio 在浏览器中访问数据库,而不需要安装多余的客户端,对前端友好,是轻量级全栈开发很好选择。
以上就是全栈轻量级搭配:Remix/Prisma/Sqlite的详细内容,更多关于全栈轻量级搭配:Remix/Prisma/Sqlite的资料请关注我们其它相关文章!
相关推荐
-
Remix如何支持原生 CSS方法详解
目录 Remix CSS 语法 links 函数写法 links 函数层级 links 函数中 css 媒体查询 第三方 css import 语法 小结 Remix CSS 语法 Remix 是一个多页面的框架,对页面的原生 CSS 的支持分为两大类型: 使用 links 函数,转换成 link 标签支持 css 使用 javascript import 语法支持 css ,但是最终也会成为 link 标签 驼峰命名法 .PrimaryButton { /* ... */ } html 属性法
-
Remix中mdx table不支持表格解决
目录 remix 配置文件中配置 mdx 属性 添加插件 remark-gfm remix 配置文件中配置 mdx 属性 remix 中支持 md/mdx 语法,但是 Remix 语法没有内置对 markdown 表格的支持. mdx 配置在 Remix 文档很不明显,从 remix 的配置文件的 .d.ts 文件. export interface AppConfig { mdx?: RemixMdxConfig | RemixMdxConfigFunction; } export inter
-
Remix 路由模块输出对象handle函数
目录 正文 在哪里可以定义 handle? 在根路由定义 在页面 _index 路由中与 useMatch 一起 match 数组 使用场景 正文 Remix handle 函数是一个有用的对外输出的 Route 模块对象,用于暴露特定的数据 match 对象,它们经常在一起使用. 当前 Remix 版本:1.15.0 在哪里可以定义 handle? root 根组件 路由页面 在根路由定义 import { /.../ } from "@remix-run/react"; // 根路
-
Remix路由模块输出对象loader函数详解
目录 主要内容 loader 函数定义 loader 函数配合 useLoaderData 一起使用 loader 函数返回值 loader 函数的类型 loader 函数中获取 params loader 函数中处理 headers loader 函数上下文 loader 中重定向到 错误处理 在页面中的表现 loader 作为纯 api 输出数据使用 小结 主要内容 Remix loader 函数是一个获取当前页面页面数据的函数,经常与 useLoaderData 一起配合使用 当前 Rem
-
Remix 后台桌面开发electron-remix-antd-admin
目录 Remix Antd Admin Electron 项目地址 当前 Remix 版本 设计动机 Core Packages 增加左面主文件 增加 Remix 配置文件 增加 nodemon.json 核心包 国际化 图表库 裁剪工具 优点 npmrc config 使用方法 格式化工具 构建 支持 Remix Antd Admin Electron 基于 Electron/Remix/Antd/Echarts/Styled-components 的管理系统,能够快速初始化项目. 项目地址
-
Remix后台开发之remix-antd-admin配置过程
目录 Remix Antd Admin Project experience URL Current Remix Version 设计动机 核心包 国际化 图表库 裁剪工具 Remix 优点 用法 格式化工具 支持 Remix Antd Admin 一款基于 Remix / Antd / Echarts / Styled-components 的管理系统,可快速进行项目初始化.(本项目偏前端) Project experience URL 访问地址(注意部署在 vercel):remix-ant
-
Typescript是必须要学习吗?如何学习TS全栈开发
目录 TS的全面性 TS的必学性 如何学习TS 学习经历 第一步学习ES6 学习React 学习Electron 学习Taro和React Native 学习Nestjs 学习CLI构建 推荐给大家 总结 Typescript目前在前端,网站,小程序中的位置基本无可替代,同时也可以构建完美的CLI应用.在移动,桌面,后端方面,性能不是要求很高的情况下完全可以胜任,并且在区块链,嵌入式,人工智能方面也开始茁壮成长. TS的全面性 目前来说前端基本是React,Vue,Angular这三框架占据主流
-

最流行的Node.js精简型和全栈型开发框架介绍
快速开发而又容易扩展,高性能且鲁棒性强.Node.js的出现让所有网络应用开发者的这些梦想成为现实.但是,有如其他新的开发语言技术一样,从头开始使用Node.js的最基本功能来编写代码构建应用是一个非常划不来的耗时的事情.这个问题的解决方案非常简单且已经经受起时间的考验:使用一个已经提前打造好的开发框架.因此才会有如此多的如Express.js,Koa,Sails.js等框架的概念提出来并加以实现. 这些开发框架的角色非常简单.就是要去为应用开发人员节省时间,让我们不用话费太多精力在一些不必要的
-
Nodejs全栈框架StrongLoop推荐
StrongLoop是一个基于Nodejs的强大框架,几乎包含了移动开发全栈所需要的所有功能.2013年成立,很少的员工,一个技术驱动,执行力强大的团队.也是在13年我开始接触StrongLoop,当时是为了做nodejs方面的技术选型,看了许多框架,LoopBack是我觉得最酷的一个.我还记得当时是觉得LoopBack的文档太差(主要是跟在线的版本不一样),不知道能活多久所以才放弃了它.时隔一年回来看到这个绿油油的框架,这一年可真是突飞猛进呢. 全栈框架StrongLoop StrongLoo
-
Python轻量级ORM框架Peewee访问sqlite数据库的方法详解
本文实例讲述了Python轻量级ORM框架Peewee访问sqlite数据库的方法.分享给大家供大家参考,具体如下: ORM框架就是 object relation model,对象关系模型,用来实现把数据库中的表 映射到 面向对象编程语言中的类,不需要写sql,通过操作对象就能实现 增删改查. ORM的基本技术有3种: (1)映射技术 数据类型映射:就是把数据库中的数据类型,映射到编程语言中的数据类型.比如,把数据库的int类型映射到Python中的integer 类型. 类映射:把数据库中的
-
基于NodeJS的前后端分离的思考与实践(一)全栈式开发
前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异.痛定思痛,今天我们重新思考了"前后端"的定义,引入前端同学都熟悉的NodeJS,试图探索一条全新的前后端分离模式. 随着不同终端(Pad/Mobile/PC)的兴起,对开发人员的要求越来越高,纯浏览器端的响应式已经不能满足用户体验的高要求,我们往往需要针对不同的终端开发定制的版本.为了提升开发效率,前后端分离的需求越来越被重视,后端负责业务/数据接口,前端负责展现/交互逻
-
Express结合Webpack的全栈自动刷新
在以前的一篇文章自动刷新 从BrowserSync开始中,我介绍了BrowserSync这样一个出色的开发工具.通过BrowserSync我感受到了这样一个理念:如果在一次ctrl + s保存后可以自动刷新,然后立即看到新的页面效果,那会是很棒的开发体验. 现在,webpack可以说是最流行的模块加载器(module bundler).一方面,它为前端静态资源的组织和管理提供了相对较完善的解决方案,另一方面,它也很大程度上改变了前端开发的工作流程.在应用了webpack的开发流程中,想要继续"自
-
python全栈要学什么 python全栈学习路线
IT行业,技术要比学历.年龄.从业经验更为重要,技术水平直接决定就业薪资,想要学好python,首先要先了解精通Python语言基础.Python web开发.Python爬虫.Python数据分析这四大方面. 全栈即指的是全栈工程师,指掌握多种技能,并能利用多种技能独立完成产品的人.就是与这项技能有关的都会,都能够独立的完成. 全栈只是个概念,也分很多种类.真正的全栈工程师涵盖了web开发.DBA .爬虫 .测试.运维,要学的内容那是相当的巨量.就web开发方向而言需要学习的内容:前端知识 包
-
python全栈知识点总结
全栈即指的是全栈工程师,指掌握多种技能,并能利用多种技能独立完成产品的人.就是与这项技能有关的都会,都能够独立的完成. 全栈只是个概念,也分很多种类.真正的全栈工程师涵盖了web开发.DBA .爬虫 .测试.运维,要学的内容那是相当的巨量.就web开发方向而言需要学习的内容:前端知识 包括HTML5 CSS3 JS Jquery Ajax,后端至少需要能够熟练使用Django和tornado,当然会flask更好. 扩展资料: 全栈工程师的厉害之处并不是他掌握很多知识,可以一个人干多份工作.而是
-
python全栈开发语法总结
太多的小伙伴正在学习Python,就说自己以后要做全栈开发,大家知道这是做什么的吗?我们现在所知道的知识点,哪些是以后你要从事这个全栈所需要的呢?从名字上我们可以获知,"全"一样是掌握全部内容,没错,这里就是要自己掌握全部编程技能,足够独立开发的人,因此全栈士不如也说叫"全战士",如果想做,那就看下面能用到的语法吧. 1.中文编码-UTF8字符集 #!/usr/bin/env python # coding:utf8 2.数值 a = 1 b = 2.1 print
-
python爬虫搭配起Bilibili唧唧的流程分析
前言 最近需要大规模下载B站视频,同时要将下载好的视频用BV号进行重命名,最后上传至服务器.这个工作一开始我是完全手工完成的,通过游猴来下载,可是下载几十个视频还好,再多一点的话真是太烦了,而且生产力低下,因此诞生了编写脚本的想法. 一开始我需要在B站搜索关键词,然后不断点开视频后进行下载,同时在视频下载后还需要找到这个视频来修改BV号,效率实在太低,特别是当下载的视频多了,再返回来寻找它对应的BV号时也是个很繁琐的过程,因此决定进行编写python脚本. 本次的脚本可以大幅度提高工作效率,但是