C++ BloomFilter布隆过滤器应用及概念详解
目录
- 一、布隆过滤器概念
- 二、布隆过滤器应用
- 三、布隆过滤器实现
- 1.插入
- 2.查找
- 3.删除
- 四、布隆过滤器优缺
- 五、结语
一、布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间 .
位图的优点是节省空间,快,缺点是要求范围相对集中,如果范围分散,空间消耗上升,同时只能针对整型,字符串通过哈希转化成整型,再去映射,对于整型没有冲突,因为整型是有限的,映射唯一的位置,但是对于字符串来说,是无限的,会发生冲突,会发生误判:此时的情况的是不在是正确的,在是不正确的,因为可能不来是不在的,但是位置跟别人发生冲突,发生误判
此时布隆过滤器就登场了,可以降低误判率:让一个值映射多个位置,但是并不是消除误判

可能还是会出现误判:
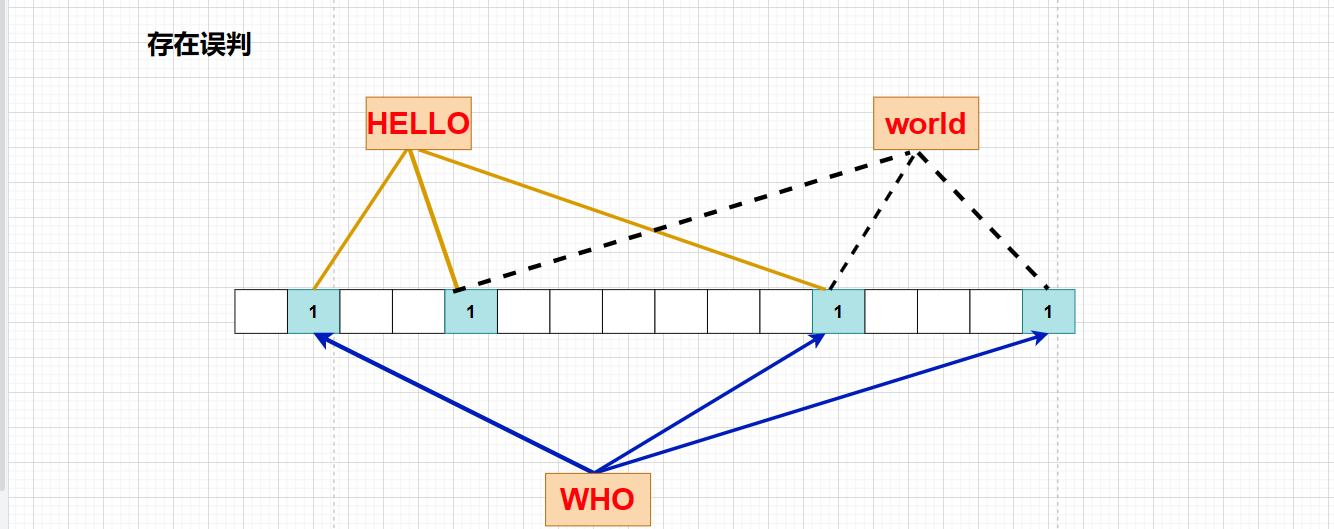
虽然布隆过滤器还是会出现误判,因为这个数据的比特位被其他数据所占,但是判断一个数据不存在是准确,不存在就是0!
布隆过滤器改进:映射多个位置,降低误判率(位置越多,消耗也越多)
如果布隆过滤器长度比较小,比特位很快会被占为1,误判率自然会上升,所以布隆过滤器的长度会影响误判率,理论上来说,如果一个值映射的位置越多,则误判的概率越小,但是并不是位置越多越好,空间也会消耗:大佬们自然也能够想得到,所以有公式:

我们可以来估算一下,假设用 3 个哈希函数,即K=3,ln2 的值我们取 0.7,那么 m 和 n 的关系大概是 m = n×k/ln2=4.2n ,也就是过滤器长度应该是插入元素个数的 4 -5倍
二、布隆过滤器应用
不需要一定准确的场景。比如游戏注册时候的昵称的判重:如果不在那就是不在,没被使用,在的话可能会被误判。
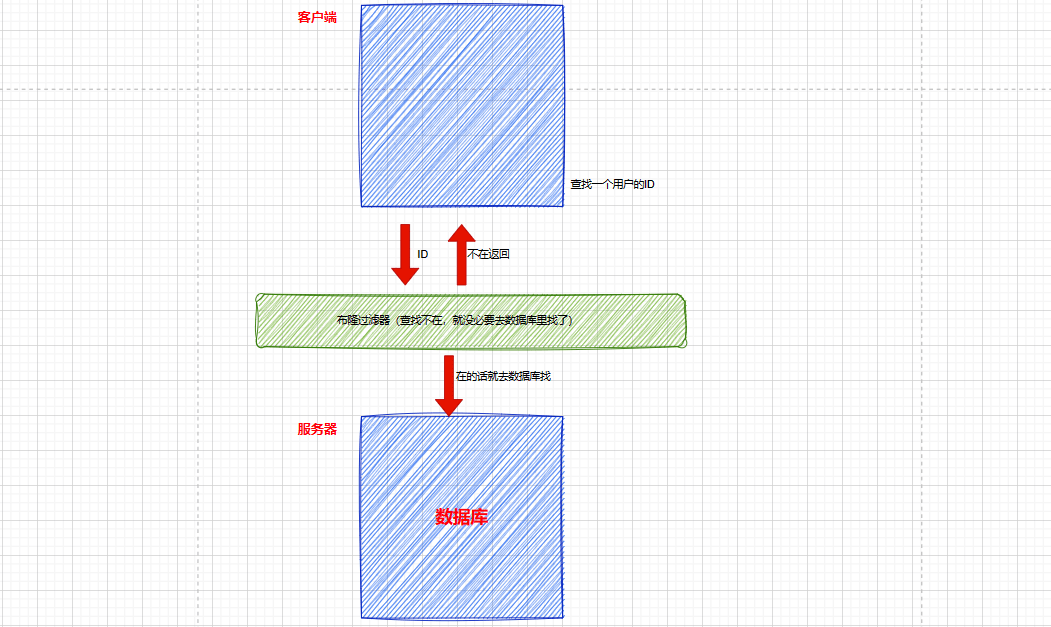
提高查找效率:客户端中查找一个用户的ID与服务器中的是否相同,在增加一层布隆过滤器提高查找效率:
三、布隆过滤器实现
布隆过滤器的插入元素可能是字符串,也可能是其他类型,只要提供对应的哈希函数将该类型的数据转换成整型就可以了。
一般情况下布隆过滤器都是用来处理字符串的,所以布隆过滤器可以实现为一个模板类,将模板参数 T 的缺省类型设置为 string:
template <size_t N,size_t X = 5,class K=string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
private:
bitset<N * X> _bs;
};
这里布隆过滤器提供三个哈希函数,由于布隆过滤器一般处理的是字符串类型的数据,所以我们默认提供几个将字符串转换成整型的哈希函数:选取综合评分最高的 BKDRHash、APHash 和 DJBHash这三种哈希算法:
struct BKDRHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& key)
{
size_t hash = 0;
int i = 0;
for (auto ch : key)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5)));
}
++i;
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& key)
{
size_t hash = 5318;
for (auto ch : key)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
1.插入
布隆过滤器复用bitset的 set 接口用于插入元素,插入元素时,我们通过上面的三个哈希函数分别计算出该元素对应的三个比特位,然后在位图中设置为1即可:
void set(const K& key)
{
size_t hash1 = HashFunc1()(key) % (N * X);
size_t hash2 = HashFunc2()(key) % (N * X);
size_t hash3 = HashFunc3()(key) % (N * X);
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
_bs.set(hash4);
}
2.查找
通过三个哈希函数分别算出对应元素的三个哈希地址,得到对应的比特位,然后去判断这三个比特位是否都被设置成了1
如果出现一个比特位未被设置成1说明该元素一定不存在,也就是如果一个比特位为0就是false;而如果三个比特位全部都被设置,则return true表示该元素已经存在(注:可能会出现误判)
bool test(const K& key)
{
size_t hash1 = HashFunc1()(key) % (N * X);
if (!_bs.test(hash1))
{
return false;
}
size_t hash2 = HashFunc2()(key) % (N * X);
if (!_bs.test(hash2))
{
return false;
}
size_t hash3 = HashFunc3()(key) % (N * X);
if (!_bs.test(hash3))
{
return false;
}
return true;
}
3.删除
布隆过滤器一般没有删除,因为布隆过滤器判断一个元素是会存在误判,此时无法保证要删除的元素在布隆过滤器中,如果此时将位图中对应的比特位清0,就会影响到其他元素了:
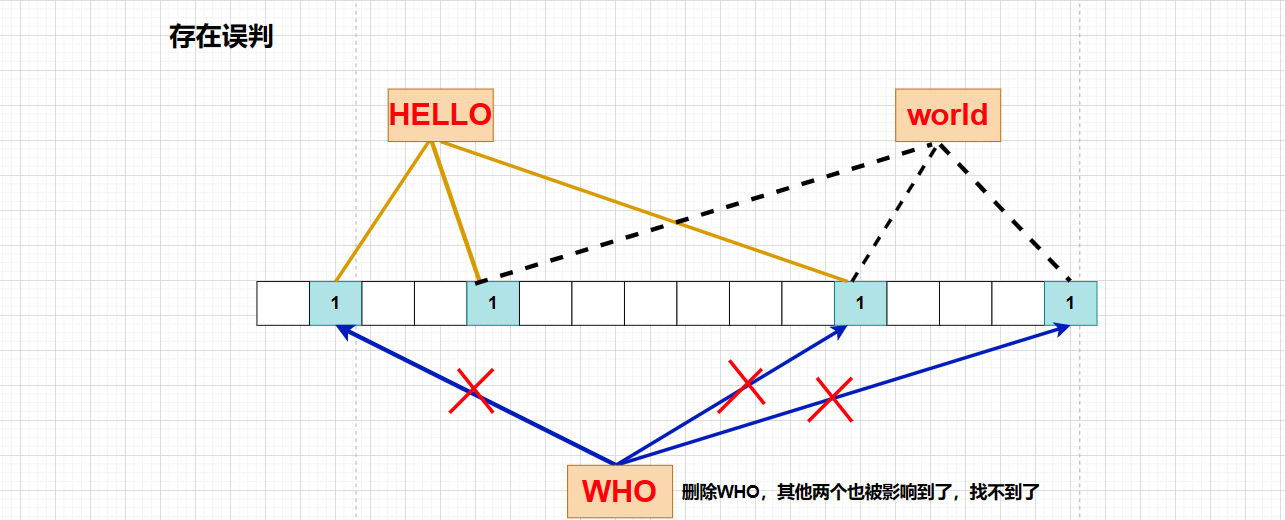
这时候我们只需要在每个比特位加一个计数器,当存在插入操作时,在计数器里面进行 ++,删除后对该位置进行 -- 即可
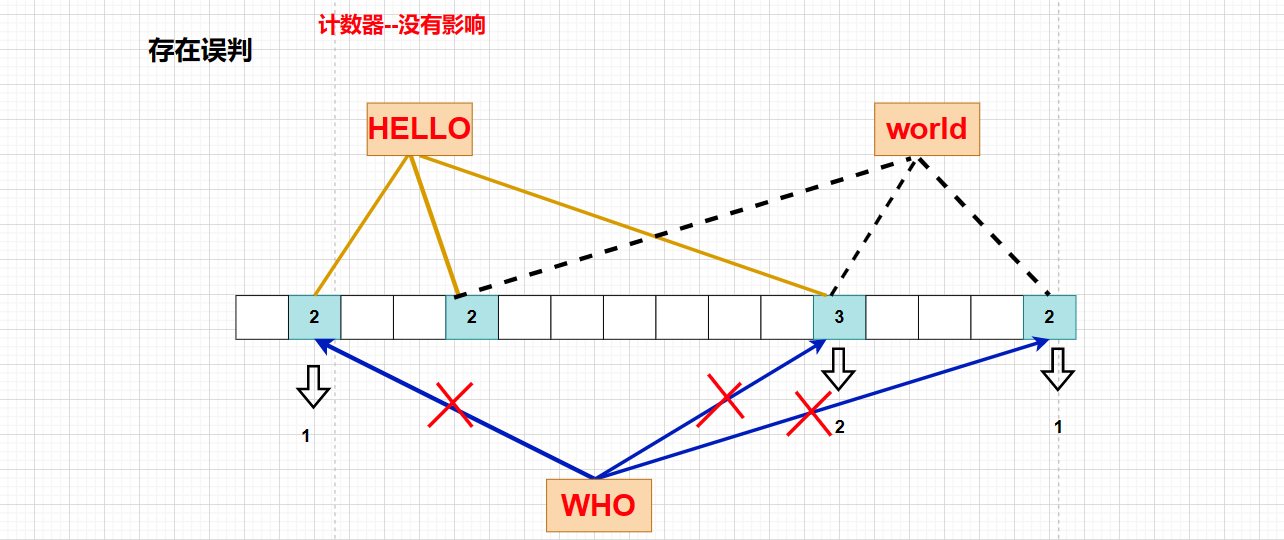
但是布隆过滤器的本来目的就是为了提高效率和节省空间,在每个比特位增加额外的计数器,空间消耗那就更多了
四、布隆过滤器优缺
优
\1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
\2. 哈希函数相互之间没有关系,方便硬件并行运算
\3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
\4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
\5. 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
\6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺
\1. 有误判率,不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
\2. 不能获取元素本身
\3. 一般情况下不能从布隆过滤器中删除元素
五、结语
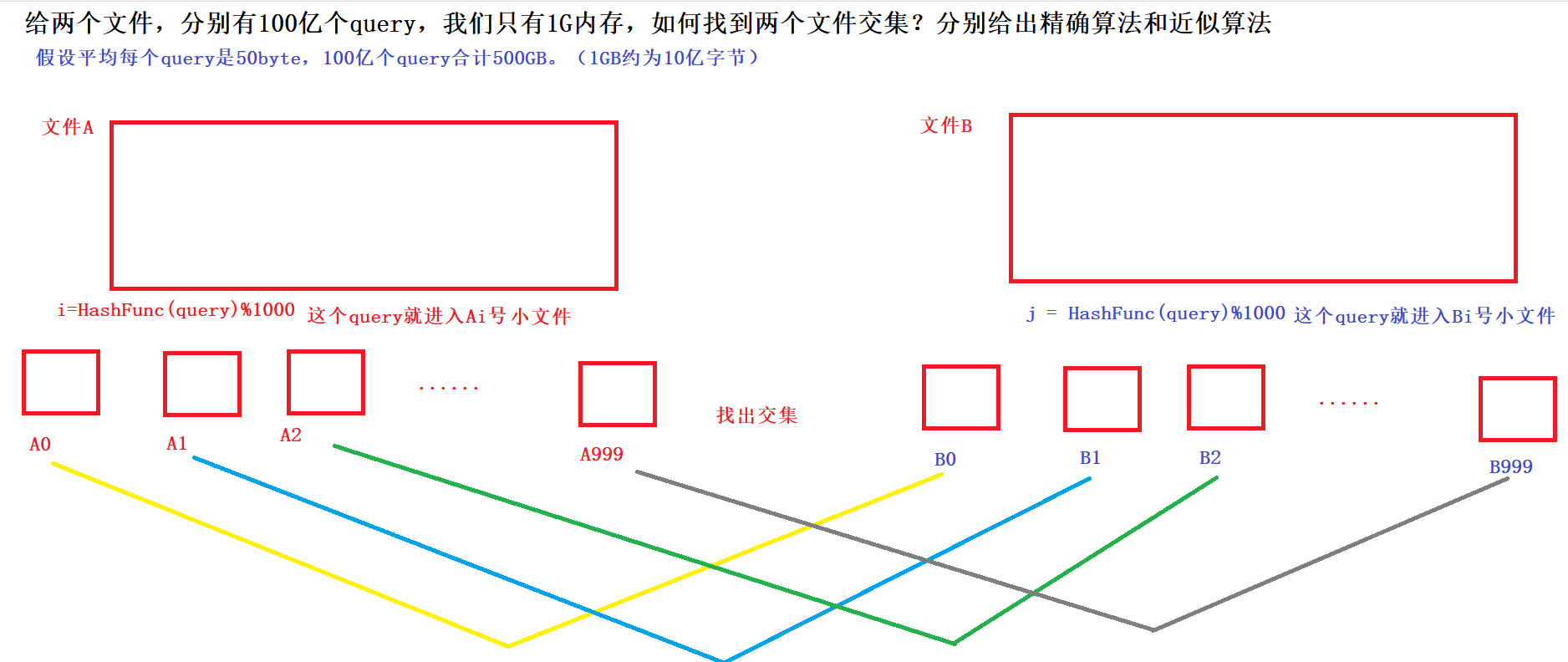
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
近似算法:利用布隆过滤器,交集的就一定会进去,但是可能会存在误判:不同的也会进去,这是近似
精准算法:query一般是查询指令,比如可能是网络请求,或者是一个数据库sql语句
100亿个query,假设平均每个query是50byte,则100亿个query那就是合计500GB
相同的query,是一定进入相同编号的小文件,再对这些文件放进内存的两个set中,编号相同的Ai和Bi小文件找交集即可
到此这篇关于C++ BloomFilter布隆过滤器应用及概念详解的文章就介绍到这了,更多相关C++ BloomFilter内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++哈希应用的位图和布隆过滤器
目录 C++哈希应用的位图和布隆过滤器 一.位图 1.位图的概念 2.位图的面试题 3.位图的实现 4.位图的应用 二.布隆过滤器 1.布隆过滤器的提出 2.布隆过滤器的概念 3.布隆过滤器的插入 4.布隆过滤器的查找 5.布隆过滤器的删除 6.布隆过滤器的优点和缺点 三.海量数据面试题 1.哈希切割 2.位图应用 3.布隆过滤器 C++哈希应用的位图和布隆过滤器 一.位图 1.位图的概念 所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景.通常是用来判断某个数据存不存在的.
-
C++ 数据结构之布隆过滤器
布隆过滤器 一.历史背景知识 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远超过一般的算法,缺点是有一定的误识别率和删除错误.而这个缺点是不可避免的.但是绝对不会出现识别错误的情况出现(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在集合中的,所以不会漏报) 在 FBI,一个
-
C++详细讲解模拟实现位图和布隆过滤器的方法
目录 位图 引论 概念 解决引论 位图的模拟实现 铺垫 结构 构造函数 存储 set,reset,test flip,size,count any,none,all 重载流运算符 测试 位图简单应用 位图代码汇总 布隆过滤器 引论 要点 代码实现 效率 解决方法 位图 引论 四十亿个无符号整数,现在给你一个无符号整数,判断这个数是否在这四十亿个数中. 路人甲:简单,快排+二分. 可是存储这四十亿个整数需要多少空间? 简单算一下,1G=1024M=1024 * 1024KB=1024 * 1024
-
C++ BloomFilter布隆过滤器应用及概念详解
目录 一.布隆过滤器概念 二.布隆过滤器应用 三.布隆过滤器实现 1.插入 2.查找 3.删除 四.布隆过滤器优缺 五.结语 一.布隆过滤器概念 布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的.比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中.此种方式不仅可以提升查询效率,也可以节省大量的内存空间 . 位图的优点是节省空间,快,缺点是要求范围相对集中,
-
victoriaMetrics库布隆过滤器初始化及使用详解
目录 victoriaMetrics库布隆过滤器 概述 限速器的初始化 总结 victoriaMetrics库布隆过滤器 代码路径:/lib/bloomfilter 概述 victoriaMetrics的vmstorage组件会接收上游传递过来的指标,在现实场景中,指标或瞬时指标的数量级可能会非常恐怖,如果不限制缓存的大小,有可能会由于cache miss而导致出现过高的slow insert. 为此,vmstorage提供了两个参数:maxHourlySeries和maxDailySeries
-
Redis 布隆过滤器命令的使用详解
目录 一.Docker 安装 Redis 布隆过滤器 学习历史重要原因之一,就是要学会感恩,因为我们都是站在巨人的肩膀上. 1.1.安装 注意: 1.2.测试 二.RedisBloom 命令讲解 2.1.命令大纲 2.2.BF.ADD 和 BF.MADD 2.3.BF.EXISTS 和 BF.MEXISTS 2.4.BF.INFO 2.5.BF.RESERVE 2.6.BF.INSERT 因为平常使用 Docker 比较多,所以照常还是使用Docker来准备环境啦. 一.Docker 安装 Re
-
Redis BloomFilter布隆过滤器原理与实现
目录 Bloom Filter 概念 Bloom Filter 原理 缓存穿透 Bloom Filter的缺点 常见问题 go语言实现 Bloom Filter 概念 布隆过滤器(英语:Bloom Filter)是1970年由一个叫布隆的小伙子提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难. Bloom Filter 原理 布隆过滤器的原理是,当一个元素
-
Java Web开发中过滤器和监听器使用详解
目录 1 Filter 1.1 Filter简介 1.2 Filter的快速入门 1.2.1 创建Filter类 1.2.2 访问index.jsp 1.3 Filter的拦截路径的配置 1.4 过滤器链 1.4.1 过滤器链简介 1.4.2 过滤器链的例子 2 Listener 2.1 概念 2.2 监听器的使用 1 Filter 1.1 Filter简介 Filter表示过滤器,是JavaWeb三大组件(Servlet.Filter.Listener)之一. 过滤器可以把资源的请求拦截下来,
-
基于线程、并发的基本概念(详解)
什么是线程? 提到"线程"总免不了要和"进程"做比较,而我认为在Java并发编程中混淆的不是"线程"和"进程"的区别,而是"任务(Task)".进程是表示资源分配的基本单位.而线程则是进程中执行运算的最小单位,即执行处理机调度的基本单位.关于"线程"和"进程"的区别耳熟能详,说来说去就一句话:通常来讲一个程序有一个进程,而一个进程可以有多个线程. 但是"任务
-
Java 虚拟机(JVM)之基本概念详解
1.类加载子系统:负责从文件系统或者网络中加载Class信息,加载的信息存放在一块称之为方法区的内存空间. 2.方法区:就是存放类信息.常量信息.常量池信息.包括字符串字面量和数字常量等.方法区是辅助堆栈的块永久区,解决堆栈信息的产生,是先决条件. 3.Java堆:再java虚拟机启动的时候建立Java堆,它是java程序最主要的内存工作区域,几乎所有的对象实例都存放到Java堆中,堆空间是所有线程共享的.堆解决的是数据存储问题,即数据怎么放.放在哪儿. 4.直接内存:Java的NIO库允许Ja
-
Java分层概念详解
service是业务层 action层即作为控制器 DAO (Data Access Object) 数据访问 1.JAVA中Action层, Service层 ,modle层 和 Dao层的功能区分?(下面所描述的service层就是biz) 首先这是现在最基本的分层方式,结合了SSH架构.modle层就是对应的数据库表的实体类. Dao层是使用了Hibernate连接数据库.操作数据库(增删改查). Service(biz)层:引用对应的Dao数据库操作,在这里可以编写自己需要的代码(比如简
-
基于java中集合的概念(详解)
1.集合是储存对象的,长度可变,可以封装不同的对象 2.迭代器: 其实就是取出元素的方式(只能判断,取出,移除,无法增加) 就是把取出方式定义在集合内部,这样取出方式就可以直接访问集合内部的元素,那么取出方式就被定义成了内部类. 二每一个容器的数据结构不同,所以取出的动作细节也不一样.但是都有共性内容判断和取出,那么可以将共性提取,这些内部类都符合一个规则Iterator Iterator it = list.iterator(); while(it.hasNext()){ System.out
-
Filter过滤器和Listener监听器详解
Filter过滤器和Listener监听器详解 Filter过滤器 Filter的简介 对资源的访问进行过滤,相当于小区的保安,进去要检查,出去还要检查. Filter的使用 编写一个类,继承并实现javax.servlet.Filter. package com.jyh.filter; import java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.