React Fiber源码深入分析
目录
- 前言
- React架构前世今生
- React@15及之前
- React@16及之后
- Fiber
- Fiber简单理解
- Fiber结构
- Fiber工作原理
- mount
- update
前言
本次React源码参考版本为17.0.3。
React架构前世今生
查阅文档了解到, React@16.x是个分水岭。
React@15及之前
在16之前,React架构大致可以分为两层:
- Reconciler: 主要职责是对比查找更新前后的变化的组件;
- Renderer: 主要职责是基于变化渲染页面;
但是React团队意识到这样的架构有致命问题: 因为在React15中,组件的更新是基于递归查找实现的,这样一旦开始递归,是没有办法中断的,如果组件层级很深,就会出现性能问题,导致页面卡顿。
React@16及之后
为了解决这样的问题,React团队在React@16进行了重构,引入了新的架构模型:
- Reconciler: 主要职责是对比查找更新前后的变化的组件;
- Renderer: 主要职责是基于变化渲染页面;
- Scheduler: 主要职责是区分任务优先级,优先执行高优先级的任务;
新的架构在原来的基础上引入了Scheduler(调度器),这个东西是React团队参考浏览器的API:requestIdleCallback实现的。它的主要作用就是调度更新任务:
- 一方面可以中断当前任务执行更高优先级的任务;
- 另一方面能判断浏览器空闲时间,在恰当的时间将主动权给到浏览器,保证页面性能;并在浏览器下次空闲时继续之前中断的任务; 这样就将之前的不可中断的同步更新变成了异步可中断更新,不直接使用浏览器API可能考虑到兼容问题,可能也有别的方面的考量。
下面是新的React架构更新模型:
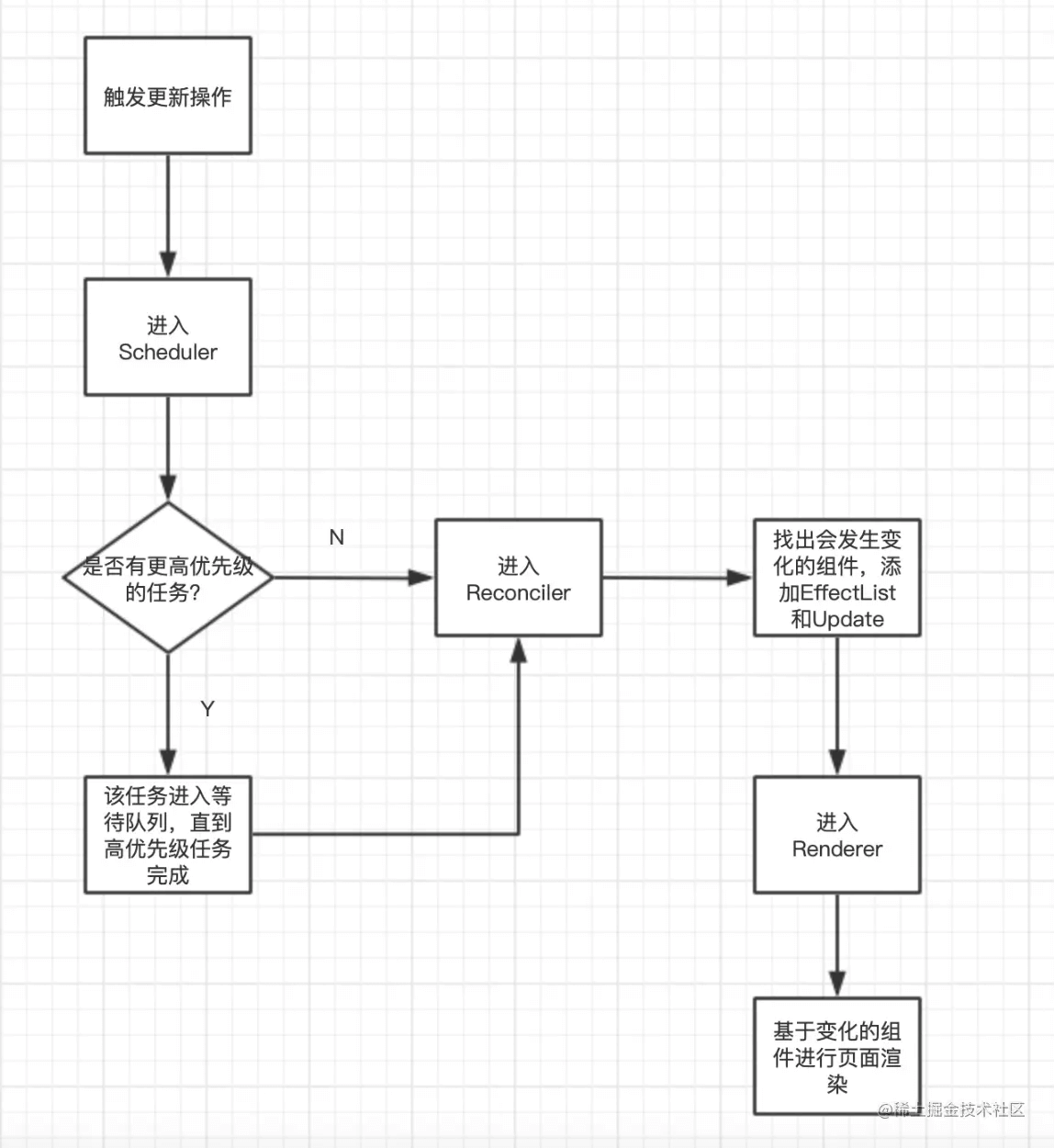
这个新的架构在进入Renderer之前的流程是可以被中断的,主要有下列两种情况:
- 进入了更高优先级的任务;
- 浏览器在当前帧没有剩余空闲时间了;
Fiber
Fiber简单的理解就是React15版本的虚拟DOM。
Fiber简单理解
如果将新的React架构比作一个公司,Fiber在新的架构里承担的就是这个公司的员工,员工也有等级,老板,部长,基层,每个人有自己的职责,知道自己在哪个节点该做什么工作,并将未完成的工作记住等第二天上班继续完成,从而保证公司的顺利运行。而每个Fiber对应一个React element:
假如有这样一段代码:
function App() {
return (
<div>
<span>牛牛</span>
<span>不怕困难</span>
</div>
)
}
上面的代码的抽象Fiber树:
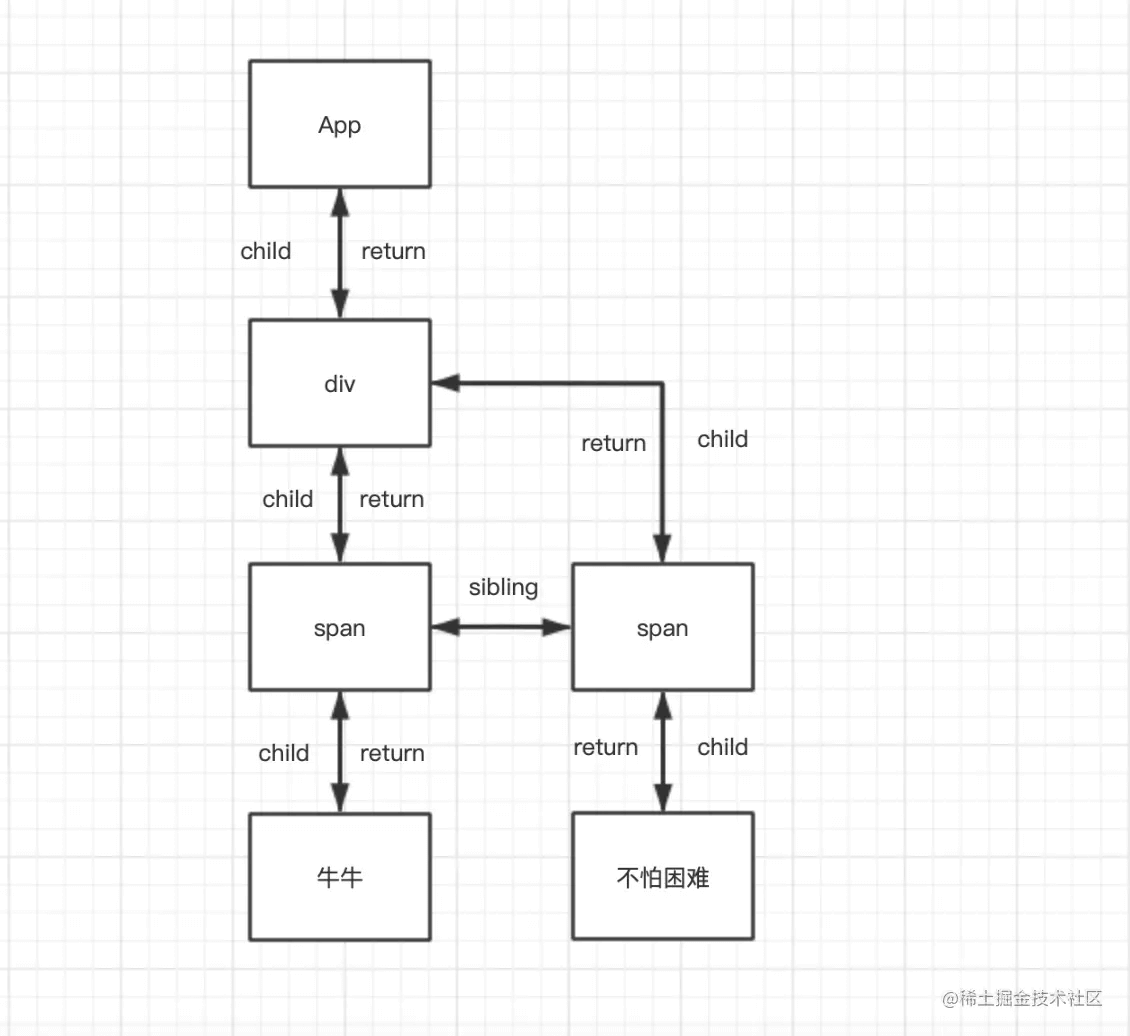
其中的每个方块都是一个Fiber,它们通过child, return, sibling连接对方构成一个Fiber树。相关参考视频讲解:传送门
Fiber结构
来看一个Fiber会有哪些属性:
function FiberNode(tag, pendingProps, key, mode) {
// Instance
this.tag = tag; // 组件类型
this.key = key; // 组件props上的key
this.elementType = null; // ReactElement.type 组件的dom类型, 比如`div, p`
this.type = null; // 异步组件resolved之后返回的内容
this.stateNode = null; // 在浏览器环境对应dom节点
this.return = null; // 指向父节点
this.child = null; // 孩子节点
this.sibling = null; // 兄弟节点, 兄弟节点的return指向同一个父节点
this.index = 0;
this.ref = null; // ref
this.pendingProps = pendingProps; // 新的props
this.memoizedProps = null; // 上一次渲染完成的props
this.updateQueue = null; // 组件产生的update信息会放在这个队列
this.memoizedState = null; // // 上一次渲染完成的state
this.dependencies = null;
this.mode = mode; // Effects
this.flags = NoFlags; // 相当于之前的effectTag, 记录side effect类型
this.nextEffect = null; // 单链表结构, 便于快速查找下一个side effect
this.firstEffect = null; // fiber中第一个side effect
this.lastEffect = null; // fiber中最后一个side effect
this.lanes = NoLanes; // 优先级相关
this.childLanes = NoLanes; // 优先级相关
this.alternate = null; // 对应的是current fiber
}
Fiber工作原理
在弄明白Fiber工作原理之前,我们要先明确一个认知:新的React架构使用了两个Fiber树。
- 一个Fiber树是当前页面dom的抽象,叫
current; - 另一个Fiber树是在内存中执行更新任务dom的抽象,叫
workInProgress;
这样做是为了方便比对变化组件,并降低创建的成本,尽可能复用现有代码逻辑,从而提高渲染效率。
mount
React代码在第一次执行时,因为页面还没有渲染出来,此时是没有current树的,只有一个正在构建DOM的workInProgress树。
假如我们有这样一段代码:
function App() {
return (
<div>
<span>牛牛</span>
<span>不怕困难</span>
</div>
)
}
ReactDOM.render(<App/>, document.querySelector('#root'));
基于上面的代码在mount会生成这样的Fiber树:
可以看到这个图只是在前面的图上增加了fiberRoot和rootFiber两个Fiber节点。
- fiberRoot:整个React应用的根节点;
- rootFiber: 某个组件树的根节点;(因为我们可能多次使用
React.render()函数,这样就会有多个rootFiber)
图中此时fiberRoot对应的rootFiber下面还是空的,因为此时是第一次渲染,页面上没有任何东西,当workInProgress树构建完成,在mutation之后,layout之前,fiberRootd的current指针会指向workInProgress树,把它作为新的current树,此时结构会变成这样:

这时页面渲染完成了,等待下次触发更新时会从current树进行拷贝生成workInProgress树,然后比对更新。
update
如果我们在上面的代码中触发更新,将牛牛文本改成了勇敢牛牛,React代码就会开始进行任务调度,因为只有这一个任务,会马上执行,会从current树的rootFiber进行拷贝生成workInProgress树的根节点,在经过向下遍历比对,发现相同的就直接从current树上拷贝复用,直到比对到叶子节点的牛牛文本变了,这时才会生成新的Fiber(这里只是为了方便解释,其实我这里使用的代码牛牛不会生成新的Fiber,因为是纯文本,只会替换父级节点的props)
到此这篇关于React Fiber源码深入分析的文章就介绍到这了,更多相关React Fiber内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

React Fiber 链表操作及原理示例详解
目录 正文 什么是Fiber Fiber节点React源码 Fiber树是链表 节点独立 节省操作时间与单向操作 利于双缓存与异步可中断更新操作 异步可中断更新 双缓存 正文 看了React源码之后相信大家都会对Fiber有自己不同的见解,而我对Fiber最大的见解就是这玩意儿就是个链表.如果把整个Fiber树当成一个整体确实有点难理解源码,但是如果把它拆开了,将每个节点都看成一个独立单元却能得到一个很清晰的思路,接下来我就简单几点讲讲,我所认为的为什么React要用链表这种数据结构来构建Fib
-
react fiber执行原理示例解析
目录 为什么要使用fiber,要解决什么问题? fiber是什么? 数据结构 执行单元 浏览器工作: Fiber执行原理 workInProgress tree: currentFiber tree: Effects list: render阶段: 遍历节点过程: 收集effect list: commit阶段: 为什么commit必须是同步的操作的? 为什么要使用fiber,要解决什么问题? 在 react16 引入 Fiber 架构之前,react 会采用递归方法对比两颗虚拟DOM树,找出需
-
详解React Fiber的工作原理
啥是React Fiber? React Fiber,简单来说就是一个从React v16开始引入的新协调引擎,用来实现Virtual DOM的增量渲染. 说人话:就是一种能让React视图更新过程变得更加流畅顺滑的处理手法. 我们都知道:进程大,线程小.而Fiber(纤维)是一种比线程还要细粒度的处理机制.从这个单词也可以猜测:React Fiber会很"细".到底怎么个细法,我们接着往下看. 为什么会有React Fiber? 之前说了,React Fiber是为了让React的视
-
详解React Fiber架构原理
目录 一.概述 二.Fiber架构 2.1 执行单元 2.2 数据结构 2.3 Fiber链表结构 2.4 Fiber节点 2.5 API 2.5.1 requestAnimationFrame 2.5.2 requestIdleCallback 三.Fiber执行流程 3.1 render阶段 3.1.1 遍历流程 3.1.2 收集effect list 3.2 commit阶段 3.2.1 根据effect list 更新视图 3.2.2 视图更新 四.总结 一.概述 在 React 16
-
React Fiber结构的创建步骤
React Fiber的创建 当前React版本基于V17.0.2版本,本篇主要介绍fiber结构的创建. 一.开始之前 个人理解,如有不对,请指出. 首先需要配置好React的debugger开发环境,入口在这里:github 执行npm run i,安装依赖,npm start运行环境. 二.从React.render开始 通过在项目入口处调用React.render,打上Debug,查看React调用栈. const root = document.getElementById('root
-
React Fiber源码深入分析
目录 前言 React架构前世今生 React@15及之前 React@16及之后 Fiber Fiber简单理解 Fiber结构 Fiber工作原理 mount update 前言 本次React源码参考版本为17.0.3. React架构前世今生 查阅文档了解到, React@16.x是个分水岭. React@15及之前 在16之前,React架构大致可以分为两层: Reconciler: 主要职责是对比查找更新前后的变化的组件: Renderer: 主要职责是基于变化渲染页面: 但是Rea
-
React Context源码实现原理详解
目录 什么是 Context Context 使用示例 createContext Context 的设计非常特别 useContext useContext 相关源码 debugger 查看调用栈 什么是 Context 目前来看 Context 是一个非常强大但是很多时候不会直接使用的 api.大多数项目不会直接使用 createContext 然后向下面传递数据,而是采用第三方库(react-redux). 想想项目中是不是经常会用到 @connect(...)(Comp) 以及 <Pro
-
React commit源码分析详解
目录 总览 commitBeforeMutationEffects commitMutationEffects 插入 dom 节点 获取父节点及插入位置 判断当前节点是否为单节点 在对应位置插入节点 更新 dom 节点 更新 HostComponent 更新 HostText 删除 dom 节点 unmountHostComponents commitNestedUnmounts commitUnmount commitLayoutEffects 执行生命周期 处理回调 总结 总览 commit
-
JDK数组阻塞队列源码深入分析总结
目录 前言 阻塞队列的功能 数组阻塞队列设计 数组的循环使用 字段设计 构造函数 put函数 take函数 offer函数 add函数 poll函数 总结 前言 在前面一篇文章从零开始自己动手写阻塞队列当中我们仔细介绍了阻塞队列提供给我们的功能,以及他的实现原理,并且基于谈到的内容我们自己实现了一个低配版的数组阻塞队列.在这篇文章当中我们将仔细介绍JDK具体是如何实现数组阻塞队列的. 阻塞队列的功能 而在本篇文章所谈到的阻塞队列当中,是在并发的情况下使用的,上面所谈到的是队列是并发不安全的,但是
-
Java线程池ThreadPoolExecutor源码深入分析
1.线程池Executors的简单使用 1)创建一个线程的线程池. Executors.newSingleThreadExecutor(); //创建的源码 public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new Linke
-
Java HashMap源码深入分析讲解
1.HashMap是数组+链表(红黑树)的数据结构. 数组用来存放HashMap的Key,链表.红黑树用来存放HashMap的value. 2.HashMap大小的确定: 1) HashMap的初始大小是16,在下面的源码分析中会看到. 2)如果创建时给定大小,HashMap会通过计算得到1.2.4.8.16.32.64....这样的二进制位作为HashMap数组的大小. //如何做到的呢?通过右移和或运算,最终n = xxx11111.n+1 = xx100000,2的n次方,即为数组大小 s
-
React Fiber与调和深入分析
目录 一 引沿 二 什么是调和 三 什么是Filber 四 实现调和的过程 1. 创建FiberRoot 2. render阶段 五 总结 一 引沿 Fiber 架构是React16中引入的新概念,目的就是解决大型 React 应用卡顿,React在遍历更新每一个节点的时候都不是用的真实DOM,都是采用虚拟DOM,所以可以理解成fiber就是React的虚拟DOM,更新Fiber的过程叫做调和,每一个fiber都可以作为一个执行单元来处理,所以每一个 fiber 可以根据自身的过期时间expir
-
Spring AOP源码深入分析
目录 1. 前言 2. 术语 3. 示例 4. @EnableAspectJAutoProxy 5. AbstractAutoProxyCreator 6. 构建Advisor 7. 创建代理对象 8. DynamicAdvisedInterceptor 9. CglibMethodInvocation 10. Advice子类 1. 前言 Spring除了IOC和DI,还有另一个杀手锏功能——Spring AOP.AOP是一种面向切面的编程思想,它的关注点是横向的,不同于OOP的纵向.面向对象
-
React源码state计算流程和优先级实例解析
目录 setState执行之后会发生什么 根据组件实例获取其 Fiber 节点 创建update对象 将Update对象关联到Fiber节点的updateQueue属性 发起调度 processUpdateQueue做了什么 变量解释 构造本轮更新的 updateQueue 更新 workInProgress 节点 总结 update对象丢失问题 为什么会丢失 如何解决 state计算的连续性 问题现象 如何解决 setState执行之后会发生什么 setState 执行之后,会执行一个叫 en
-
React 源码中的依赖注入方法
一.前言 依赖注入(Dependency Injection)这个概念的兴起已经有很长时间了,把这个概念融入到框架中达到出神入化境地的,非Spring莫属.然而在前端领域,似乎很少会提到这个概念,难道前端的代码就不需要解耦吗?前端的代码就没有依赖了?本文将以 React 的源码为例子,看看它是如何使用依赖注入这一设计模式的. 二.依赖注入的基本概念 在看代码之前,有必要先简单介绍一下依赖注入的基本概念.依赖注入和控制反转(Inversion of Control),这两个词经常一起出现.一句话表