漫谈C++哈夫曼树的原理及实现
目录
- 1. 前言
- 2. 设计思路
- 3. 构建思路
- 4. 编码实现
- 4.1 使用优先队列
- 4.2 使用一维数组
- 5. 总结
1. 前言
什么是哈夫曼树?
把权值不同的n个结点构造成一棵二叉树,如果此树满足以下几个条件:
- 此 n 个结点为二叉树的叶结点 。
- 权值较大的结点离根结点较近,权值较小的结点离根结点较远。
- 该树的带权路径长度是所有可能构建的二叉树中最小的。
则称符合上述条件的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
构建哈夫曼树的目的是什么?
用来解决在通信系统中如何使用最少的二进制位编码字符信息。
本文将和大家聊聊哈夫曼树的设计思想以及构建过程。
2. 设计思路
哈夫曼树产生的背景:
在通信系统中传递一串字符串文本时,需要对这一串字符串文本信息进行二进制编码。编码时如何保证所用到的bit位是最少的,或保证整个编码后的传输长度最短。
现假设字符串由ABCD 4个字符组成,最直接的想法是使用 2 个bit位进行等长编码,如下表格所示:
| 字符 | 编码 |
|---|---|
| A | 00 |
| B | 01 |
| C | 10 |
| D | 11 |
传输ABCD字符串一次时,所需bit为 2位,当通信次数达到 n次时,则需要的总传输长度为 n*2。当字符串的传输次数为 1000次时,所需要传输的总长度为 2000个bit。
使用等长编码时,如果传输的报文中有 26 个不同字符时,因需要对每一个字符进行编码,至少需要 5位bit。
但在实际应用中,各个字符的出现频率或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z。使用等长编码特点是无论字符出现的频率差异有多大,每一个字符都得使用相同的bit位。
哈夫曼的设计思想:
- 对字符串信息进行编码设计时,让使用频率高的字符使用
短码,使用频率低的用长码,以优化整个信息编码的长度。 - 基于这种简单、朴素的想法设计出来的编码也称为
不等长编码。
哈夫曼不等长编码的具体思路如下:
如现在要发送仅由A、B、C、D 4 个字符组成的报文信息 ,A字符在信息中占比为 50%,B的占比是 20%,C的占比是 15%, D的 占比是10%。
不等长编码的朴实思想是字符的占比越大,所用的bit位就少,占比越小,所用bit位越多。如下为每一个字符使用的bit位数:
A使用1位bit编码。B使用2位bit编码。C使用3位bit编码。D使用3位bit编码。
具体编码如下表格所示:
| 字符 | 占比 | 编码 |
|---|---|---|
| A | 0.5 | 0 |
| B | 0.2 | 10 |
| C | 0.15 | 110 |
| D | 0.1 | 111 |
如此编码后,是否真的比前面的等长编码所使用的总bit位要少?
计算结果=0.5*1+0.2*2+0.15*3+0.1*3=1.65。
先计算每一个字符在报文信息中的占比乘以字符所使用的bit位。
然后对上述每一个字符计算后的结果进行相加。
显然,编码ABCD只需要 1.65 个bit ,比等长编码用到的2 个 bit位要少 。当传输信息量为 1000时,总共所需要的bit位=1.65*1000=1650 bit。
哈夫曼编码和哈夫曼树有什么关系?
因为字符的编码是通过构建一棵自下向上的二叉树推导出来的,如下图所示:

哈夫曼树的特点:
- 信息结点都是叶子结点。
- 叶子结点具有权值。如上二叉树,
A结点权值为0.5,B结点权值为0.2,C结点权值为0.15,D结点权值为0.1。 - 哈夫曼编码为不等长前缀编码(即要求一个字符的编码不能是另一个字符编码的前缀)。
- 从根结点开始,为左右分支分别编号
0和1,然后顺序连接从根结点到叶结点所有分支上的编号得到字符的编码。
相信大家对哈夫曼树有了一个大概了解,至于如何通过构建哈夫曼树,咱们继续再聊。
3. 构建思路
在构建哈夫曼树之前,先了解几个相关概念:
- 路径和路径长度:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为
1,则从根结点到第L层结点的路径长度为L-1。 - 结点的权及带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
- 树的带权路径长度:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为
WPL。
如有权值为{3,4,9,15}的 4 个结点,则可构造出不同的二叉树,其带权路径长度也会不同。如下 3 种二叉树中,B的树带权路径长度是最小的。

哈夫曼树的构建过程就是要保证树的带权路径长度最小。
那么,如何构建二叉树,才能保证构建出来的二叉树的带权路径长度最小?
如有一字符串信息由 ABCDEFGH 8个字符组成,每一个字符的权值分别为{3,6,12,9,4,8,21,22},构建最优哈夫曼树的流程:
1.以每一个结点为根结点构建一个单根二叉树,二叉树的左右子结点为空,根结点的权值为每个结点的权值。并存储到一个树集合中。

2.从树集合中选择根结点的权值最小的 2 个树。重新构建一棵新二叉树,让刚选择出来的2 棵树的根结点成为这棵新树的左右子结点,新树的根结点的权值为 2 个左右子结点权值的和。构建完成后从树集合中删除原来 2个结点,并把新二叉树放入树集合中。
如下图所示。权值为 3和4的结点为新二叉树的左右子结点,新树根结点的权值为7。

3.重复第二步,直到树集合中只有一个根结点为止。



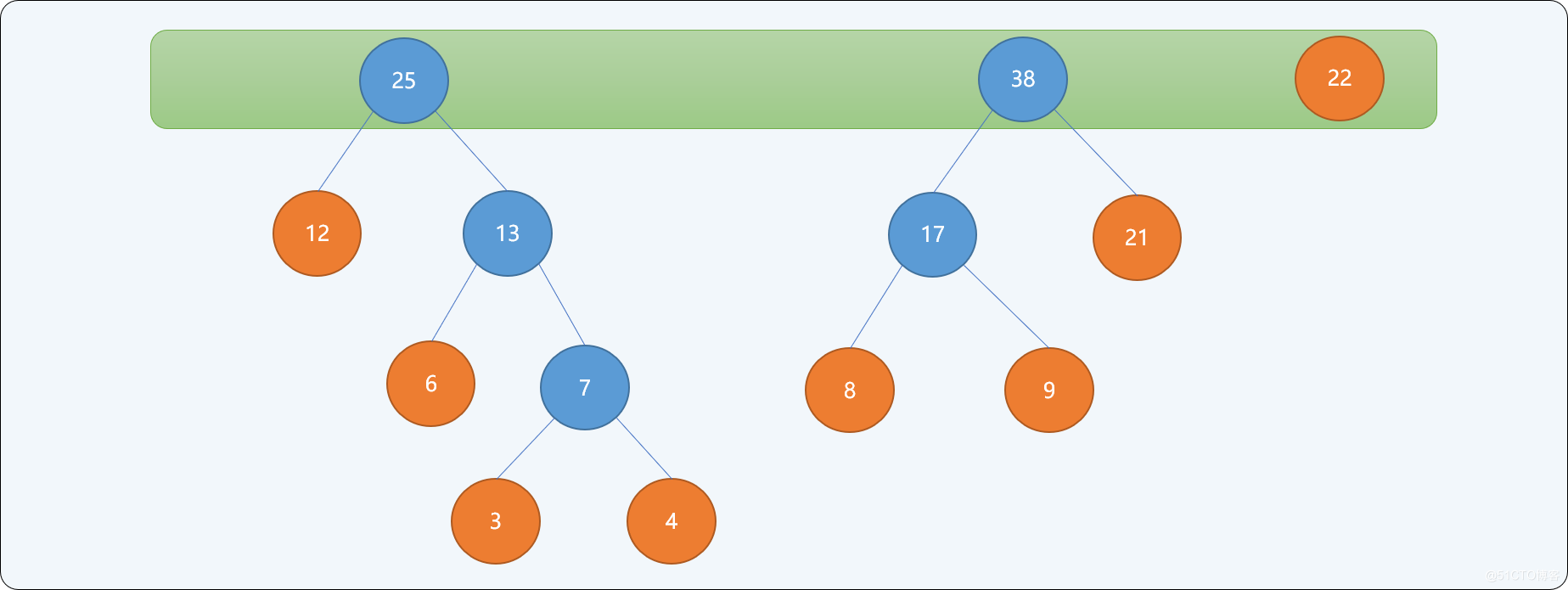

当集合中只存在一个根结点时,停止构建,并且为最后生成树的每一个非叶子结点的左结点分支标注0,右结点分支标注1。如下图所示:

通过上述从下向上的思想构建出来的二叉树,可以保证权值较小的结点离根结点较远,权值较大的结点离根结点较近。最终二叉树的带权路径长度: WPL=(3+4)*5+6*4+(8+9+12)*3+(21+22)*2=232 。并且此树的带权路径长度是所有可能构建出来的二叉树中最小的。
上述的构建思想即为哈夫曼树设计思想,不同权值的字符编码就是结点路径上0和1的顺序组合。如下表所述,权值越大,其编码越小,权值越小,其编码越大。其编码长度即从根结点到此叶结点的路径长度。
| 字符 | 权值 | 编码 |
|---|---|---|
| A | 3 | 11110 |
| B | 6 | 1110 |
| C | 12 | 110 |
| D | 9 | 001 |
| E | 4 | 11111 |
| F | 8 | 000 |
| G | 21 | 01 |
| H | 22 | 10 |
4. 编码实现
4.1 使用优先队列
可以把权值不同的结点分别存储在优先队列(Priority Queue)中,并且给与权重较低的结点较高的优先级(Priority)。
具体实现哈夫曼树算法如下:
1.把n个结点存储到优先队列中,则n个节点都有一个优先权Pi。这里是权值越小,优先权越高。
2.如果队列内的节点数>1,则:
- 从队列中移除两个最小的结点。
- 产生一个新节点,此节点为队列中移除节点的父节点,且此节点的权重值为两节点之权值之和,把新结点加入队列中。
- 重复上述过程,最后留在优先队列里的结点为哈夫曼树的根节点(
root)。
完整代码:
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
//树结点
struct TreeNode {
//结点权值
float weight;
//左结点
TreeNode *lelfChild;
//右结点
TreeNode *rightChild;
//初始化
TreeNode(float w) {
weight=w;
lelfChild=NULL;
rightChild=NULL;
}
};
//为优先队列提供比较函数
struct comp {
bool operator() (TreeNode * a, TreeNode * b) {
//由大到小排列
return a->weight > b->weight;
}
};
//哈夫曼树类
class HfmTree {
private:
//优先队列容器
priority_queue<TreeNode *,vector<TreeNode *>,comp> hfmQueue;
public:
//构造函数,构建单根结点树
HfmTree(int weights[8]) {
for(int i=0; i<8; i++) {
//创建不同权值的单根树
TreeNode *tn=new TreeNode(weights[i]);
hfmQueue.push(tn);
}
}
//显示队列中的最一个结点
TreeNode* showHfmRoot() {
TreeNode *tn;
while(!hfmQueue.empty()) {
tn= hfmQueue.top();
hfmQueue.pop();
}
return tn;
}
//构建哈夫曼树
void create() {
//重复直到队列中只有一个结点
while(hfmQueue.size()!=1) {
//从优先队列中找到权值最小的 2 个单根树
TreeNode *minFirst=hfmQueue.top();
hfmQueue.pop();
TreeNode *minSecond=hfmQueue.top();
hfmQueue.pop();
//创建新的二叉树
TreeNode *newRoot=new TreeNode(minFirst->weight+minSecond->weight);
newRoot->lelfChild=minFirst;
newRoot->rightChild=minSecond;
//新二叉树放入队列中
hfmQueue.push(newRoot);
}
}
//按前序遍历哈夫曼树的所有结点
void showHfmTree(TreeNode *root) {
if(root!=NULL) {
cout<<root->weight<<endl;
showHfmTree(root->lelfChild);
showHfmTree(root->rightChild);
}
}
//析构函数
~HfmTree() {
//省略
}
};
//测试
int main(int argc, char** argv) {
//不同权值的结点
int weights[8]= {3,6,12,9,4,8,21,22};
//调用构造函数
HfmTree hfmTree(weights);
//创建哈夫曼树
hfmTree.create();
//前序方式显示哈夫曼树
TreeNode *root= hfmTree.showHfmRoot();
hfmTree.showHfmTree(root);
return 0;
}
显示结果:

上述输出结果,和前文的演示结果是一样的。
此算法的时间复杂度为O(nlogn)。因为有n个结点,所以树总共有2n-1个节点,使用优先队列每个循环须O(log n)。
4.2 使用一维数组
除了上文的使用优先队列之外,还可以使用一维数组的存储方式实现。
在哈夫曼树中,叶子结点有 n个,非叶子结点有 n-1个,使用数组保存哈夫曼树上所的结点需要 2n-1个存储空间 。其算法思路和前文使用队列的思路差不多。直接上代码:
#include <iostream>
using namespace std;
//叶结点数量
const unsigned int n=8;
//一维数组长度
const unsigned int m= 2*n -1;
//树结点
struct TreeNode {
//权值
float weight;
//父结点
int parent;
//左结点
int leftChild;
//右结点
int rightChild;
};
class HuffmanTree {
public:
//创建一维数组
TreeNode hfmNodes[m+1];
public:
//构造函数
HuffmanTree(int weights[8]);
~HuffmanTree( ) {
}
void findMinNode(int k, int &s1, int &s2);
void showInfo() {
for(int i=0; i<m; i++) {
cout<<hfmNodes[i].weight<<endl;
}
}
};
HuffmanTree::HuffmanTree(int weights[8]) {
//前2 个权值最小的结点
int firstMin;
int secondMin;
//初始化数组中的结点
for(int i = 1; i <= m; i++) {
hfmNodes[i].weight = 0;
hfmNodes[i].parent = -1;
hfmNodes[i].leftChild = -1;
hfmNodes[i].rightChild = -1;
}
//前 n 个是叶结点
for(int i = 1; i <= n; i++)
hfmNodes[i].weight=weights[i-1];
for(int i = n + 1; i <=m; i++) {
this->findMinNode(i-1, firstMin, secondMin);
hfmNodes[firstMin].parent = i;
hfmNodes[secondMin].parent = i;
hfmNodes[i].leftChild = firstMin;
hfmNodes[i].rightChild = secondMin;
hfmNodes[i].weight = hfmNodes[firstMin].weight + hfmNodes[secondMin].weight;
}
}
void HuffmanTree::findMinNode(int k, int & firstMin, int & secondMin) {
hfmNodes[0].weight = 32767;
firstMin=secondMin=0;
for(int i=1; i<=k; i++) {
if(hfmNodes[i].weight!=0 && hfmNodes[i].parent==-1) {
if(hfmNodes[i].weight < hfmNodes[firstMin].weight) {
//如果有比第一小还要小的,则原来的第一小变成第二小
secondMin = firstMin;
//新的第一小
firstMin = i;
} else if(hfmNodes[i].weight < hfmNodes[secondMin].weight)
//如果仅比第二小的小
secondMin = i;
}
}
}
int main() {
int weights[8]= {3,6,12,9,4,8,21,22};
HuffmanTree huffmanTree(weights);
huffmanTree.showInfo();
return 1;
}
测试结果:

5. 总结
哈夫曼树是二叉树的应用之一,掌握哈夫曼树的建立和编码方法对解决实际问题有很大帮助。
以上就是漫谈C++哈夫曼树的原理及实现的详细内容,更多关于C++哈夫曼树的资料请关注我们其它相关文章!
相关推荐
-
C++实现哈夫曼树的方法
序言 对于哈夫曼编码,个人的浅薄理解就是在压缩存储空间用很大用处. 用一个很简单例子,存储一篇英文文章时候,可能A出现的概率较大,Z出现的记录较小,如果正常存储,可能A与Z存储使用的空间一样.但是用哈夫曼编码方式,A经常出现,所用编码长度就短. 构造哈夫曼树,生成哈夫曼编码 一.定义节点类型 struct Node { char C; long key; Node *Left, *Right,*parent; Node() { Left = Right = NULL; } }; 二.定义树类型(
-

C++深入讲解哈夫曼树
目录 哈夫曼树的基本概念 1)路径 2)路径长度 3)权 4)结点的带权路径长度 5)树的带权路径长度 6)哈夫曼树 哈夫曼树的构造算法 哈夫曼树的构造过程 哈夫曼树算法的实现 1)结点的存储结构 2)构建哈夫曼树 哈夫曼树的基本概念 Q:什么是哈夫曼树 A:哈夫曼树又称最优树,是一类带权路径长度最短的树.在正式了解哈夫曼树之前,我们需要了解一些概念. 1)路径 Q:什么是路径 A:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径. 2)路径长度 Q:什么是路径长度 A:路径上的分支
-
C++数据结构与算法之哈夫曼树的实现方法
本文实例讲述了C++数据结构与算法之哈夫曼树的实现方法.分享给大家供大家参考,具体如下: 哈夫曼树又称最优二叉树,是一类带权路径长度最短的树. 对于最优二叉树,权值越大的结点越接近树的根结点,权值越小的结点越远离树的根结点. 前面一篇图文详解JAVA实现哈夫曼树对哈夫曼树的原理与java实现方法做了较为详尽的描述,这里再来看看C++实现方法. 具体代码如下: #include <iostream> using namespace std; #if !defined(_HUFFMANTREE_H
-
C++实现哈夫曼树算法
如何建立哈夫曼树的,网上搜索一堆,这里就不写了,直接给代码. 1.哈夫曼树结点类:HuffmanNode.h #ifndef HuffmanNode_h #define HuffmanNode_h template <class T> struct HuffmanNode { T weight; // 存储权值 HuffmanNode<T> *leftChild, *rightChild, *parent; // 左.右孩子和父结点 }; #endif /* HuffmanNode
-
C++详解哈夫曼树的概念与实现步骤
目录 一. 基本概念 二.构造哈夫曼树 三.哈夫曼树的基本性质 四.哈夫曼编码 五.哈夫曼解码 六.文件的压缩和解压缩 一. 基本概念 结点的权: 有某种现实含义的数值 结点的带权路径长度: 从结点的根到该结点的路径长度与该结点权值的乘积 树的带权路径长度: 树上所有叶结点的带权路径长度之和 哈夫曼树: 在含有 n n n个带权叶结点的二叉树中, w p l wpl wpl 最小 的二叉树称为哈夫曼树,也称最优二叉树(给定叶子结点,哈夫曼树不唯一). 二.构造哈夫曼树 比较简单,此处不赘述步骤
-
C++实现哈夫曼树编码解码
本文实例为大家分享了C++实现哈夫曼树的编码解码,供大家参考,具体内容如下 代码: #pragma once #include<iostream> #include<stack> using namespace std; #define m 20 stack<int> s; /*哈夫曼树结点类HuffmanNode声明*/ template<class T> class HuffmanNode { private: HuffmanNode<T>
-
漫谈C++哈夫曼树的原理及实现
目录 1. 前言 2. 设计思路 3. 构建思路 4. 编码实现 4.1 使用优先队列 4.2 使用一维数组 5. 总结 1. 前言 什么是哈夫曼树? 把权值不同的n个结点构造成一棵二叉树,如果此树满足以下几个条件: 此 n 个结点为二叉树的叶结点 . 权值较大的结点离根结点较近,权值较小的结点离根结点较远. 该树的带权路径长度是所有可能构建的二叉树中最小的. 则称符合上述条件的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree). 构建哈夫曼树的目的是什么? 用来解决在通信系统中如何
-
Python完成哈夫曼树编码过程及原理详解
哈夫曼树原理 秉着能不写就不写的理念,关于哈夫曼树的原理及其构建,还是贴一篇博客吧. https://www.jb51.net/article/97396.htm 其大概流程 哈夫曼编码代码 # 树节点类构建 class TreeNode(object): def __init__(self, data): self.val = data[0] self.priority = data[1] self.leftChild = None self.rightChild = None self.co
-
图文详解JAVA实现哈夫曼树
前言 我想学过数据结构的小伙伴一定都认识哈夫曼,这位大神发明了大名鼎鼎的"最优二叉树",为了纪念他呢,我们称之为"哈夫曼树".哈夫曼树可以用于哈夫曼编码,编码的话学问可就大了,比如用于压缩,用于密码学等.今天一起来看看哈夫曼树到底是什么东东. 概念 当然,套路之一,首先我们要了解一些基本概念. 1.路径长度:从树中的一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目称为路径长度. 2.树的路径长度:从树根到每一个结点的路径长度之和,我们所说的完全
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
C++实现哈夫曼树简单创建与遍历的方法
本文以实例形式讲述了C++实现哈夫曼树简单创建与遍历的方法,比较经典的C++算法. 本例实现的功能为:给定n个带权的节点,如何构造一棵n个带有给定权值的叶节点的二叉树,使其带全路径长度WPL最小. 据此构造出最优树算法如下: 哈夫曼算法: 1. 将n个权值分别为w1,w2,w3,....wn-1,wn的节点按权值递增排序,将每个权值作为一棵二叉树.构成n棵二叉树森林F={T1,T2,T3,T4,...Tn},其中每个二叉树都只有一个权值,其左右字数为空 2. 在森林F中选取根节点权值最小二叉树,
-
使用C语言详解霍夫曼树数据结构
1.基本概念 a.路径和路径长度 若在一棵树中存在着一个结点序列 k1,k2,--,kj, 使得 ki是ki+1 的双亲(1<=i<j),则称此结点序列是从 k1 到 kj 的路径. 从 k1 到 kj 所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1. b.结点的权和带权路径长度 在许多应用中,常常将树中的结点赋予一个有着某种意义的实数,我们称此实数为该结点的权,(如下面一个树中的蓝色数字表示结点的权) 结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘
-
C++数据结构之文件压缩(哈夫曼树)实例详解
C++数据结构之文件压缩(哈夫曼树)实例详解 概要: 项目简介:利用哈夫曼编码的方式对文件进行压缩,并且对压缩文件可以解压 开发环境:windows vs2013 项目概述: 1.压缩 a.读取文件,将每个字符,该字符出现的次数和权值构成哈夫曼树 b.哈夫曼树是利用小堆构成,字符出现次数少的节点指针存在堆顶,出现次数多的在堆底 c.每次取堆顶的两个数,再将两个数相加进堆,直到堆被取完,这时哈夫曼树也建成 d.从哈夫曼树中获取哈夫曼编码,然后再根据整个字符数组来获取出现了得字符的编
-
解读赫夫曼树编码的问题
定义: 结点的带权路径长度为从该结点到树根之间的路径长度与结点上权的乘积.树的带权路径长度为树中所有叶子结点的带权路径长度之和.假设有n个权值,试构造一棵有n个叶子结点的二叉树,每个叶子结点带权为wi,则其中带权路径长度最小的二叉树称做最优二叉树或赫夫曼树. 构造赫夫曼树的方法: (1)根据给定的n个权值{w1,w2,w3......}构成n棵二叉树的集合F={T1,T2,T3,T4......},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树均空. (2)在F中选取两棵根结点的权值
-
C++ 哈夫曼树对文件压缩、加密实现代码
在以前写LZW压缩算法的时候,遇到很多难受的问题,基本上都在哈夫曼编码中解决了,虽然写这代码很费神,但还是把代码完整的码出来了,毕竟哈夫曼这个思想确实很牛逼.哈夫曼树很巧妙的解决了当时我在LZW序列化的时候想解决的问题,就是压缩后文本的分割.比如用lzw编码abc,就是1,2,3.但这个在存为文件的时候必须用分割符把1,2,3分割开,非常浪费空间,否则会和12 23 123 产生二义性.而哈夫曼树,将所有char分布在叶节点上,在还原的时候,比如1101110,假设110是叶节点,那么走到110