Linux行处理工具之grep 正则表达式详解
目录
- 正则表达式在grep应用以及差别
- 匹配案例
- fgrep
- 总结
之前我们学习了
linux grep的基本操作,以及提及了linux grep的孪生兄弟egrep 和 fgrep,这次我们来看下。
在介绍正则表达式之前,我们先来尝试一下,假如有如下文本。

我们想获取空行,应该如何来写呢?
命令:
grep ^$ test1 -n
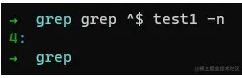
通过上述例子,我们使用正则表达式^$已经成功拿到了第四行数据,那么,这究竟如何解呢,我们细看博文。
正则表达式在grep应用以及差别
grep表达式有三种不同的版本,分别为basic(BRE) 、extended(ERE) 以及 perl(PCRE) ,我们grep默认支持的是BRE,而ERE是egrep支持的,或者说是grep -E支持的, 而PCRE则是grep -P支持的,那么这三者究竟有啥区别呢?
| BRE | ERE | PCRE | |||
|---|---|---|---|---|---|
| 任意字符 | . | . | . | ||
| 前一个字符0次或者出现1次 | ? | ? | ? | ||
| 前一个字符出现0次或无数次 | * | * | * | ||
| 前一个字符出现一个或者更多 | + | + | + | ||
| 字符集 | [...] | [...] | [...] | ||
| 字符集取反 | [^...] | [^...] | [^...] | ||
| 匹配前面字符出现的n次 | {n} | {n} | {n} | ||
| 匹配前面字符出现的n次以上 | {n,} | {n,} | {n,} | ||
| 匹配前面字符出现的n次到m次 | {n,m} | {n,m} | {n,m} | ||
| 开头 | |||||
| 结尾 | $ | $ | $ | ||
| 多表达式连接 | | | ||||
| 单词 | \w | \w | \w 或者 [[:word:]] | ||
| 字母大写/小写 | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | [[:upper:]]/[[:lower:]] | ||
| 非单词 | \W | ||||
| 空白字符 | \s 或者 [[:space:]] | \s 或者 [[:space:]] | |||
| 非空白字符 | [^[:space:]] | [^[:space:]] | \S | ||
| 数字 | \d 或者 [[:digit:]] | [[:digit:]] | [[:digit:]] | ||
| 非数字 | \D | [^[:digit:]] | [^[:digit:]] |
那么如何进行切换呢? 如上面所示,我们来看下。
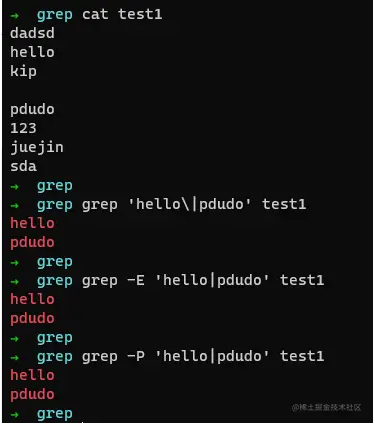
如上所述,若我们需要连接多个匹配项,在BRE(grep)中则是|,而在ERE(egrep)和PCRE(grep -P)中则是|,所以我们可以顺利获取出结果,更多匹配项如上所述
匹配案例
匹配电话号码
若电话号码为xxx-xxxx-xxxx类型的,如何进行匹配呢? 我们可以使用'[0-9]{3}-[0-9]{4}-[0-9]{4}'进行匹配。
例如:
命令:
echo "telphone: 180-1234-5678" | grep '[0-9]{3}-[0-9]{4}-[0-9]{4}' -o

同样的,该方法还可以用来匹配其ip地址,正则: [0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}.[0-9]{0,3}

匹配空行
若我们想匹配空行,则可以使用^$进行匹配,即: 开头就是结尾。
例如:
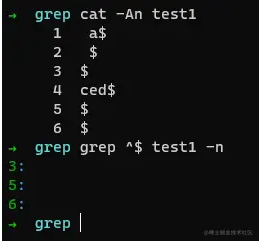
如上命令,我们顺利取出了 第3、5、6行数据
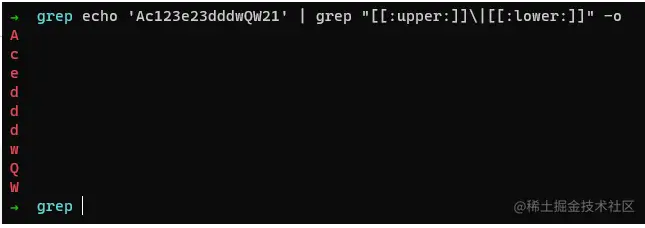
匹配所有字母
命令:
echo 'Ac123e23dddwQW21' | grep "[[:upper:]]|[[:lower:]]" -o
取出redis在使用的配置文件
我们知道redis服务器是以#来注释的,我们可以利用grep或者egrep来过滤掉注释和空格,例如:
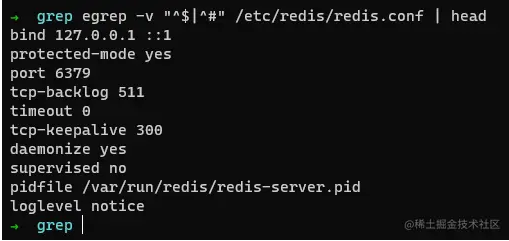
fgrep
fgrep最为简单,它不会启用正则表达式,而是按照字符来进行搜索,什么意思呢? 我们举个小案例就清楚了,
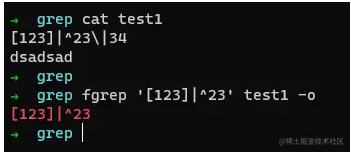
它不会进行任何正则匹配,所以可以直接使用搜索选就成,不用考虑转移啥的。
总结
我们一般将BRE称之为 基本正则表达式、ERE称之为 扩展正则表达式 而 PCRE称之为Perl兼容的正则表达式,如上正则表达式不是grep工具所实现的,而是单独的一套表达式,有很多语言在使用中,例如 sed默认正则表达式是 BRE, 而我们之前所学习的awk使用的正则表达式则是ERE,是不是感觉知识被串联起来了呢,好巧,我也是,怎么样,快来动手试验一下吧。
到此这篇关于Linux行处理工具之grep 正则表达式详解的文章就介绍到这了,更多相关linux grep 正则表达式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
linux系统用户管理与grep正则表达式示例教程
前言 本文主要给大家介绍了关于linux系统用户管理与grep正则表达式的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. linux系统用户管理与grep正则表达式 1.复制/etc/skel目录为/home/tuser1,要求/home/tuser1及其内部文件的属组和其它用户均没有任何访问权限. [root@suywien ~]# cp -rpv /etc/skel/ /home/tuser1/ '/etc/skel/' -> '/home/tuser1/' '/
-

linux grep正则表达式与grep用法详解
需要大家牢记:正则表达式与通配符不一样,它们表示的含义并不相同 正则表达式只是字符串的一种描述,只有和支持正则表达式的工具相结合才能进行字符串处理.本文以grep为例来讲解正则表达式. grep命令 功能:输入文件的每一行中查找字符串. 基本用法: grep [-acinv] [--color=auto] [-A n] [-B n] '搜寻字符串' 文件名 参数说明: -a:将二进制文档以文本方式处理 -c:显示匹配次数 -i:忽略大小写差异 -n:在行首显示行号 -A:After的意思,显示匹
-
linux 正则表达式grep实例分析
在很多技术领域(如:自然语言处理,数据存储等),正则表达式可以很方便的提取我们想要的信息,所以正则表达式是一个很重要的知识点! 一.概念 正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串.通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具. 正则表达式目前被集成到了各种文本编辑器/文本处理工具当中 二.应用场景 (1)验证:表单提交时,进行用户名密码的验证. (2)查找:从大量信息中快速提取指定内容,在一批url中,查找指定url
-
linux grep与正则表达式使用介绍
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹配行.Unix的grep家族包括grep.egrep和fgrep.Windows系统下类似命令FINDSTR. grep egrep fgrep(不支持正则表达式) grep需要标准输入 因此常常位于管道右侧 命令参数: --color=auto: 对匹配到的文本着色显示 -v: 显示不被patte
-
linux下关于正则表达式grep的一点总结
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串.通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具.类似于生活中常见的寻人启示,通过描述一个人的特征来进行"搜索匹配" 如今正则已经被我们广泛应用,目前被集成到了各种文本编辑器/文本处理工具当中 应用场景**验证: **表单提交时,进行用户名密码验证.**查找: **从大量信息中快速提取指定内容.在一批url中,查找指定url替换: 将指定格式的文本,进行正则匹配查找,找
-
浅谈Linux grep与正则表达式
grep简介 grep 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来.通常grep有三种版本grep.egrep(等同于grep -E)和fgrep.egrep为扩展的grep,fgrep则为快速grep(固定的字符串来对文本进行搜索,不支持正则表达式的引用但是查询极为快速).grep是Linux文本处理三剑客之一. grep使用方式 使用方式: grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN
-
Linux行处理工具之grep 正则表达式详解
目录 正则表达式在grep应用以及差别 匹配案例 fgrep 总结 之前我们学习了linux grep的基本操作,以及提及了linux grep的孪生兄弟egrep 和 fgrep,这次我们来看下. 在介绍正则表达式之前,我们先来尝试一下,假如有如下文本. 我们想获取空行,应该如何来写呢? 命令: grep ^$ test1 -n 通过上述例子,我们使用正则表达式^$已经成功拿到了第四行数据,那么,这究竟如何解呢,我们细看博文. 正则表达式在grep应用以及差别 grep表达式有三种不同的版本,
-
一天一个shell命令 linux文本内容操作系列-grep命令详解
从这篇开始,是文本内容操作,区别于文本操作. Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户. shell,perl,python,一直都是文本操作的专家语言,而我们今后学习的的将是shell的噱头--文本操作.下面提到最常见的一个: grep 这算是文本内容的一个重量级选手,能根据某些规格在上千行的文本文件中查找
-
正则表达式grep用法详解
语法:grep 选项 'word' filename -c:打印符合要求的行数 -i:不区分大小写 -n:在输出符合要求的行的同时显示行号 -v:打印不符合要求的行 -A:后跟一个数字n,表示打印符合要求的行以及下面n行 -B:后跟一个数字n,表示打印符合要求的行以及上面n行 -C:后跟一个数字n,表示打印符合要求的行以及上下各n行 -r:会把目录下所有的文件全部遍历 --color:把匹配到的关键词用红色标示 例子: 过滤出带有某个关键词的行并输出行号 grep -n 'root' 1.txt
-
Linux中 sed 和 awk的用法详解
sed用法: sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换.删除.新增.选取等特定工作,下面先了解一下sed的用法 sed命令行格式为: sed [-nefri] 'command' 输入文本 常用选项: -n∶使用安静(silent)模式.在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上.但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来. -e∶直接在指令列模式上进行 sed 的
-
Linux环境下查看日志文件命令详解
目录 前言 一.cat命令: 二.more命令: 三.less命令: 四.head命令: 五.tail命令: 六.tac命令: 七.echo命令: 八.grep命令: 九.sed命令: 混合命令: 附加: 前言 当日志存储文件很大时,我们就不能用 vi 直接去查看日志了,就需要Linux的一些内置命令去查看日志文件. 系统Log日志位置: /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一 /var/log/secure 与安全相关的日志
-
Linux下tcpdump命令解析及使用详解
简介 用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具.tcpdump可以将网络中传送的数据包的"头"完全截获下来提供分析.它支持针对网络层.协议.主机.网络或端口的过滤,并提供and.or.not等逻辑语句来帮助你去掉无用的信息. 实用命令实例 默认启动 tcpdump 普通情况下,直接启动tcpdump将监视第一个网络接口上所有流过的数据包. 监视指定网络接口的数据包 tcpdum
-
Linux 中常用的Rpm命令实例详解
rpm命令是RPM软件包的管理工具.rpm原本是Red Hat Linux发行版专门用来管理Linux各项套件的程序,由于它遵循GPL规则且功能强大方便,因而广受欢迎.逐渐受到其他发行版的采用.RPM套件管理方式的出现,让Linux易于安装,升级,间接提升了Linux的适用度. 语法 rpm(选项)(参数) 选项 -a:查询所有套件: -b<完成阶段><套件档>+或-t <完成阶段><套件档>+:设置包装套件的完成阶段,并指定套件档的文件名称: -c:只列出
-
linux传输文件命令 rz 和 sz详解
一. 概述 rz,sz是Linux/Unix同Windows进行ZModem文件传输的命令行工具. 优点就是不用再开一个sftp工具登录上去上传下载文件. Zmodem协议是针对modem的一种错误校验协议.利用Zmodem协议,可以在modem上发送512字节的数据块.如果某个数据块发生错误,接受端会发送"否认"应答,因此,数据块就会被重传.它是Xmodem 文件传输协议的一种增强形式,不仅能传输更大的数据,而且错误率更小.包含一种名为检查点重启的特性,如果通信链接在数据传输过程中中
-
一款高颜值且免费的 SQL 开发工具之Beekeeper Studio详解
目录 Beekeeper Studio 简介 Beekeeper Studio 安装 Beekeeper Studio 使用教程 连接数据库 文件关联 SQL 编辑器 表格浏览器 快捷键 SQLTools 工具 今天给大家介绍一款简单易用而且美观的免费 SQL 客户端:Beekeeper Studio. Beekeeper Studio 简介 Beekeeper Studio 是一款免费开源的 SQL 开发和数据库管理工具,具有美观高效.简单易用的特点.Beekeeper Studio 基于 V