Pytorch自定义CNN网络实现猫狗分类详解过程
目录
- 前言
- 一. 数据预处理
- 二. 定义网络
- 三. 训练模型
前言
数据集下载地址:
链接: https://pan.baidu.com/s/17aglKyKFvMvcug0xrOqJdQ?pwd=6i7m
Dogs vs. Cats(猫狗大战)来源Kaggle上的一个竞赛题,任务为给定一个数据集,设计一种算法中的猫狗图片进行判别。
数据集包括25000张带标签的训练集图片,猫和狗各125000张,标签都是以cat or dog命名的。图像为RGB格式jpg图片,size不一样。截图如下:

一. 数据预处理
pytorch的数据预处理部分要写成一个类,这个类继承Dataset类,并必须要实现三个函数。
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms as T
import matplotlib.pyplot as plt
import os
from PIL import Image
class DogCat(Dataset):
def __init__(self, root, transforms=None, train=True):
imgs = [os.path.join(root,img) for img in os.listdir(root)]
imgs_num = len(imgs)
if train:
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
self.imgs = imgs[int(0.3 * imgs_num):]
if transforms is None:
normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.transforms = T.Compose([
T.Resize(224),
T.CenterCrop(224),
T.ToTensor(),
normalize
])
else:
self.transforms = transforms
def __getitem__(self, index):
img_path = self.imgs[index]
# dog label : 1 cat label : 0
label = 1 if "dog" in img_path.split('/')[-1] else 0
data = Image.open(img_path)
data = self.transforms(data)
return data,label
def __len__(self):
return len(self.imgs)
__init__为构造函数,我这里用力定义数据路径,数据集划分,transforms。
__getitem__为迭代函数,用来return单个数据的data和label。
__len__返回数据集的长度。
二. 定义网络
在这个例子中,我们用一个简单的4层卷积,2层全连接,最后跟一个sigmoid输出二分类的概率的CNN网络。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.conv4 = nn.Conv2d(128, 128, 3)
self.max_pool = nn.MaxPool2d(2)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
# 12*12 for size(224,224) 7*7 for size(150,150)
self.fc1 = nn.Linear(128*12*12, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv3(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.conv4(x)
x = self.relu(x)
x = self.max_pool(x)
# 展开
x = x.view(in_size, -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x
pytorch定义网络时,必须实现两个函数,构造函数主要定义一些网络块,forward函数实现前向推理过程。且在后续代码中,如果定义对象model: ConvNet和数据image,可以直接通过model(image)来调用froward函数(python真的很神奇,C++出身的我理解这些骚操作好难)
三. 训练模型
数据准备好了,模型网络定义好了,下一步当然是训练权重了。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
from dataset import DogCat
from network import ConvNet
from draw import draw_acc,draw_loss
train_data_root = "/home/elvis/workfile/dataset/dataset_kaggledogvscat/train"
batch_size = 256
# 1. prepare dataset
train_data = DogCat(train_data_root, train=True)
val_data = DogCat(train_data_root, train=False)
train_dataloader = DataLoader(train_data,batch_size=batch_size,shuffle=True)
val_dataloader = DataLoader(val_data,batch_size=batch_size,shuffle=True)
# 2. load model
model = ConvNet()
if torch.cuda.is_available():
model.cuda()
# 3. prepare super parameters
criterion = nn.BCELoss()
learning_rate = 1e-3
# optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 4. train
train_loss_epoch = []
train_acc_epoch = []
val_loss_epoch = []
val_acc_epoch = []
for epoch in range(1, 10):
model.train()
train_loss = 0;
train_acc = 0;
for batch_idx, (data, target) in enumerate(train_dataloader):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda().float().unsqueeze(-1)
else:
data, target = data, target.float().unsqueeze(-1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = criterion(output, target)
train_loss += loss.item();
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).cuda();
train_acc += pred.eq(target.long()).sum().item();
loss.backward()
optimizer.step()
if(batch_idx+1)%10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx+1) * len(data), len(train_dataloader.dataset),
100. * (batch_idx+1) / len(train_dataloader), loss.item()))
train_loss_epoch.append(train_loss / len(train_dataloader));
train_acc_epoch.append(train_acc / len(train_dataloader.dataset));
print('\nTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(train_loss / len(train_dataloader), train_acc, len(train_dataloader.dataset),
100. * train_acc / len(train_dataloader.dataset)));
# val
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_dataloader):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda().float().unsqueeze(-1)
else:
data, target = data, target.float().unsqueeze(-1)
output = model(data)
# print(output)
test_loss += criterion(output, target).item(); #每个批次平均,一个epoch里所有批次求和
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).cuda()
correct += pred.eq(target.long()).sum().item()
print('Valid set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss/len(val_dataloader), correct, len(val_dataloader.dataset),
100. * correct / len(val_dataloader.dataset)));
val_loss_epoch.append(test_loss / len(val_dataloader));
val_acc_epoch.append(correct / len(val_dataloader.dataset));
# Save model
val_acc_rate = correct / len(val_dataloader.dataset);
save = True
best = "best.pt"
last = "last.pt"
if save:
# Save last, best and delete
torch.save(model.state_dict(), last)
if val_acc_rate == max(val_acc_epoch):
torch.save(model.state_dict(), best)
print("save epoch {} model".format(epoch))
# 5. drawing
draw_loss(train_loss_epoch, val_loss_epoch)
draw_acc(train_acc_epoch,val_acc_epoch)
第一步,准备数据。先用我们之前定义的DogCat类来加载数据,但这个类继承自dataset,是加载一条数据的。如果要批量加载数据,还要用pytorch内部的另一个类DataLoader,然后在构造函数里传入batchsize就可以批量加载数据了。注意这里的类对象实际是一个生成器,后续通过循环就可以一直批量的去取数据了。
第二步,定义模型对象,有用显卡就把模型放在显卡上,没有的话就用cpu跑。
第三步,定义一些超参数。因为是二分类,网络最后一层为sigmoid输出类别的概率值,所以选用二分类交叉熵损失函数。再设置一下学习率和优化器。
第四步,训练n个epoch。在每一个epoch里计算训练集准去率,验证集准确率,并保存模型。
最后结果像这样
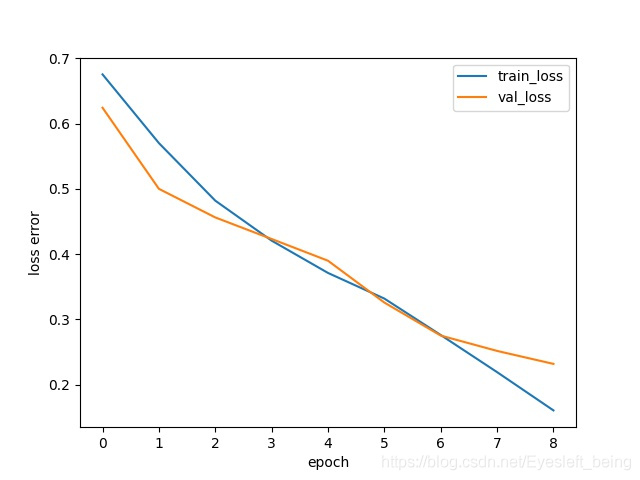
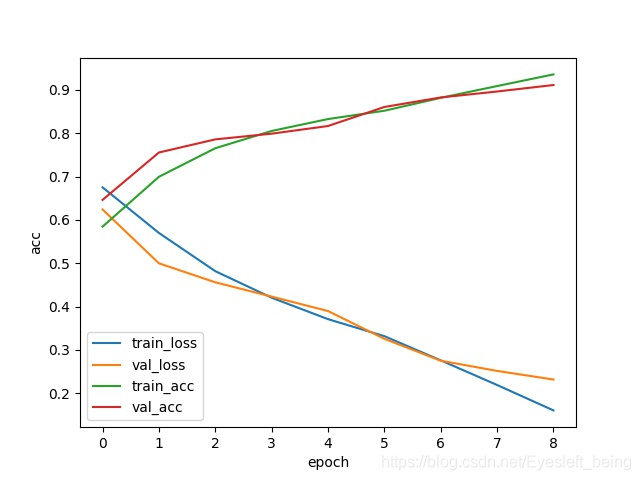
有条件的可以多训练几个epoch试试。
到此这篇关于Pytorch自定义CNN网络实现猫狗分类详解过程的文章就介绍到这了,更多相关Pytorch猫狗分类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
Pytorch自定义CNN网络实现猫狗分类详解过程
目录 前言 一. 数据预处理 二. 定义网络 三. 训练模型 前言 数据集下载地址: 链接: https://pan.baidu.com/s/17aglKyKFvMvcug0xrOqJdQ?pwd=6i7m Dogs vs. Cats(猫狗大战)来源Kaggle上的一个竞赛题,任务为给定一个数据集,设计一种算法中的猫狗图片进行判别. 数据集包括25000张带标签的训练集图片,猫和狗各125000张,标签都是以cat or dog命名的.图像为RGB格式jpg图片,size不一样.截图如下: 一.
-
如何利用Tensorflow2进行猫狗分类识别
目录 前言 数据集获取 文件解压 将文件分为训练集与验证集 绘图查看 模型建立 神经网络模型 模型编译 数据预处理 模型训练 运行模型 可视化中间表示 评估模型精度与损失值 总结 前言 本文参照了大佬Andrew Ng的所讲解的Tensorflow 2视频所写,本文将其中只适用于Linux的功能以及只适用于Google Colab的功能改为了普适的代码同时加入了自己的理解,尚处学习与探索阶段,能力有限,希望大家多多指正. 文章所需代码均在Jupyter Notebook当中实现. 数据集获取 使
-
pytorch 网络参数 weight bias 初始化详解
权重初始化对于训练神经网络至关重要,好的初始化权重可以有效的避免梯度消失等问题的发生. 在pytorch的使用过程中有几种权重初始化的方法供大家参考. 注意:第一种方法不推荐.尽量使用后两种方法. # not recommend def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.
-
微信小程序之网络请求简单封装实例详解
微信小程序之网络请求简单封装实例详解 在微信小程序中实现网络请求相对于Android来说感觉简单很多,我们只需要使用其提供的API就可以解决网络请求问题. 普通HTTPS请求(wx.request) 上传文件(wx.uploadFile) 下载文件(wx.downloadFile) WebSocket通信(wx.connectSocket) 为了数据安全,微信小程序网络请求只支持https,当然各个参数的含义就不在细说,不熟悉的话可以:可以去阅读官方文档的网络请求api,当我们使用request
-
postman自定义函数实现 时间函数的思路详解
Postman说明 Postman是一种网页调试与发送网页http请求的chrome插件.我们可以用来很方便的模拟get或者post或者其他方式的请求来调试接口. Postman背景介绍 用户在开发或者调试网络程序或者是网页B/S模式的程序的时候是需要一些方法来跟踪网页请求的,用户可以使用一些网络的监视工具比如著名的Firebug等网页调试工具.今天给大家介绍的这款网页调试工具不仅可以调试简单的css.html.脚本等简单的网页基本信息,它还可以发送几乎所有类型的HTTP请求!Postman在发
-
Python利用三层神经网络实现手写数字分类详解
目录 前言 一.神经网络组成 二.代码实现 1.引入库 2.导入数据集 3.全连接层 4.ReLU激活函数层 5.Softmax损失层 6.网络训练与推断模块 三.代码debug 四.结果展示 补充 前言 本文做的是基于三层神经网络实现手写数字分类,神经网络设计是设计复杂深度学习算法应用的基础,本文将介绍如何设计一个三层神经网络模型来实现手写数字分类.首先介绍如何利用高级编程语言Python搭建神经网络训练和推断框架来实现手写数字分类的训练和使用. 本文实验文档下载 一.神经网络组成 一个完整的
-
Android自定义View中attrs.xml的实例详解
Android自定义View中attrs.xml的实例详解 我们在自定义View的时候通常需要先完成attrs.xml文件 在values中定义一个attrs.xml 然后添加相关属性 这一篇先详细介绍一下attrs.xml的属性. <?xml version="1.0" encoding="utf-8"?> <resources> //自定义属性名,定义公共属性 <attr name="titleText" for
-
jQuery Ajax自定义分页组件(jquery.loehpagerv1.0)实例详解
简单的两个步骤即可实现分页功能 <script src="<%=basePath%>/resources/js/jquery-1.7.1.min.js"></script> <script src="<%=basePath%>/resources/js/jquery.loehpagerv1.0.js"></script> <script type="text/JavaScript
-
Android 网络请求框架Volley实例详解
Android 网络请求框架Volley实例详解 首先上效果图 Logcat日志信息on Reponse Volley特别适合数据量不大但是通信频繁的场景,像文件上传下载不适合! 首先第一步 用到的RequetQueue RequestQueue.Java RequestQueue请求队列首先得先说一下,ReuqestQueue是如何对请求进行管理的...RequestQueue是对所有的请求进行保存...然后通过自身的start()方法开启一个CacheDispatcher线程用于缓存调度,开