Python实现将DNA序列存储为tfr文件并读取流程介绍
最近导师让我跑模型,生物信息方向的,我一个学计算机的,好多东西都看不明白。现在的方向大致是,用深度学习的模型预测病毒感染人类的风险。
既然是病毒,就需要拿到它的DNA,也就是碱基序列,然后把这些ACGT序列丢进模型里面,然后就是预测能不能感染人类,说实话,估计结果不会好,现在啥都是transformer,而且我看的这篇论文,我认为仅仅从DNA序列大概预测不出什么东西。
但是就那样吧,现在数据去哪里下载,需要下载什么样的数据,下载完成后怎么处理我还是一脸懵逼,但是假设上面都处理好了,然后即使把数据丢给模型,跑就完了。
也不是没进度,目前了解到的是,我应该使用一种叫fasta格式的文件,然后把里面的一大串ACGT序列拿出来,转为模型可以处理的数据。然后,以后再说。
现在假设我已经有了ACGT的序列,然后把它转为模型可以处理的矩阵。
这里,我随机生成长度为131072的基因序列,为什么是这个数字呢,因为这是之前看的 论文里的值,,暂时按照这个来做。
实现:
首先是导入库
import numpy as np import random import tensorflow as tf import inspect from typing import Any, Callable, Dict, Optional, Text, Union, Iterable import os
然后,定义一个生成长度为131072bp的函数:
#随机生成131072的dna序列
length = 131072
def randomSeq(length):
return ''.join([random.choice('ACGT') for i in range(length)])
这个函数的返回结果是长度为length的字符串,类似ACGTTGC这样。
然后这种序列模型是没办法处理的,所以需要把它变成矩阵,也就用one-hot编码。
比如ACGT这个序列,编码成:
[ [1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1] ]
这样的一个矩阵,这个就不细说了,网上很多资料。
然后,我从别人的代码中抄了一个函数,很好用。
#DNA序列转为one-hot编码,可以直接拿来用
def one_hot_encode(sequence: str,
alphabet: str = 'ACGT',
neutral_alphabet: str = 'N',
neutral_value: Any = 0,
dtype=np.float32) -> np.ndarray:
"""One-hot encode sequence."""
def to_uint8(string):
return np.frombuffer(string.encode('ascii'), dtype=np.uint8)
hash_table = np.zeros((np.iinfo(np.uint8).max, len(alphabet)), dtype=dtype)
hash_table[to_uint8(alphabet)] = np.eye(len(alphabet), dtype=dtype)
hash_table[to_uint8(neutral_alphabet)] = neutral_value
hash_table = hash_table.astype(dtype)
return hash_table[to_uint8(sequence)]
这是一个嵌套函数了,仔细研究下还是可以理解的,我就不说了,会用就行了。
简单讲一下参数的意思:
sequence:字符串类型,就是输入的碱基序列。
alphabet: str = ‘ACGT’ :词表,一共只需要这四个词
neutral_alphabet: str = ‘N’,
neutral_value: Any = 0,
上面这两一起用,就是说遇到N这个碱基就会编码成[0,0,0,0]的向量。
dtype=np.float32,这个就是内部元素值的类型。
简单生成一下:

然后输入序列长度是131072bp,所以输入的矩阵就是131072x4的矩阵,现在来把序列变为矩阵。
编码成one-hot矩阵
dnaVec = one_hot_encode(dna)
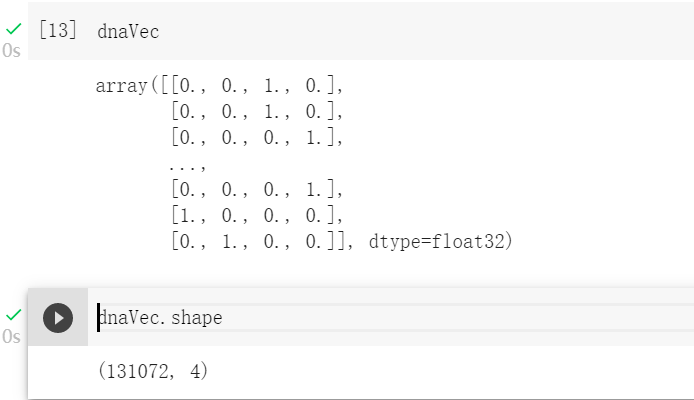
现在DNA序列已经变成了矩阵,接下来需要把这一条序列,也就是一个样本数据,变成TensorFlow中的TFRecord文件格式。TFRecord 是 TensorFlow 中的数据集存储格式。当我们将数据集整理成 TFRecord 格式后,TensorFlow 就可以高效地读取和处理这些数据集,从而帮助我们更高效地进行大规模的模型训练。
关于tfr文件的处理,我就不在细说了,总之现在我们需要构建example。
在此之前,我们需要先这么做:
#给出结果的tfr文件的路径 path = '/content/drive/MyDrive/test_Enformer/result.tfr' #dna的numpy数组转成字节流,这样才能存储 dnaVec = dnaVec.tobytes()
接下来就是把这个字节流数据写入到tfr文件中,这里同时写入这条数据的label中,我的问题是给一个Dna序列,预测是或者不是的二分类问题,所以我同时把这条dna序列对应的真实标签也写进去,但是我是随机从0,1中选择一个。
from tensorflow.core.example.feature_pb2 import BytesList
with tf.io.TFRecordWriter(path) as writer:
feature = {
#序列使用的是tf.train.BytesList类型
'sequence':tf.train.Feature(bytes_list=tf.train.BytesList(value=[dnaVec])),
#label是随机生成的0,或者1
'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[np.random.choice([0,1])]))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
这部分的代码执行结束后,就已经把dna序列以及对应的标签写入了tfr文件中,不过这个tfr文件中只有一个example,你可以写更多个。
刚刚写入的tfr文件

到这里,相当于已经把数据准备好了,接下来就是读取数据。
#从刚才的路径中加载数据集 dataset = tf.data.TFRecordDataset(path)
#定义Feature结构,告诉解码器每个Feature的类型是什么
feature_description = {"sequence": tf.io.FixedLenFeature((), tf.string),
"label": tf.io.FixedLenFeature((), tf.int64)}
#将 TFRecord 文件中的每一个序列化的 tf.train.Example 解码
def parse_example(example_string):
#解析之后得到的example
example = tf.io.parse_single_example(example_string,feature_description)
#example['sequence']还是字节流的形式,重新转为数字向量
sequence = tf.io.decode_raw(example['sequence'], tf.float32)
sequence = tf.reshape(sequence,(length,4)) #形状需要重塑,不然就是一个长向量
label = tf.cast(example['label'],tf.int64) #标签对应的类型转换
#每一天example解析后返回对应的一个字典
return {
'sequence':sequence,
'label': label
}
#把parse_example函数映射到dataset中的每个example, #这里的dataset中只有一个example dataset = dataset.map(parse_example)
此时的dataset是一个可以遍历的对象,内部元素可以认为是解析完成后的example。
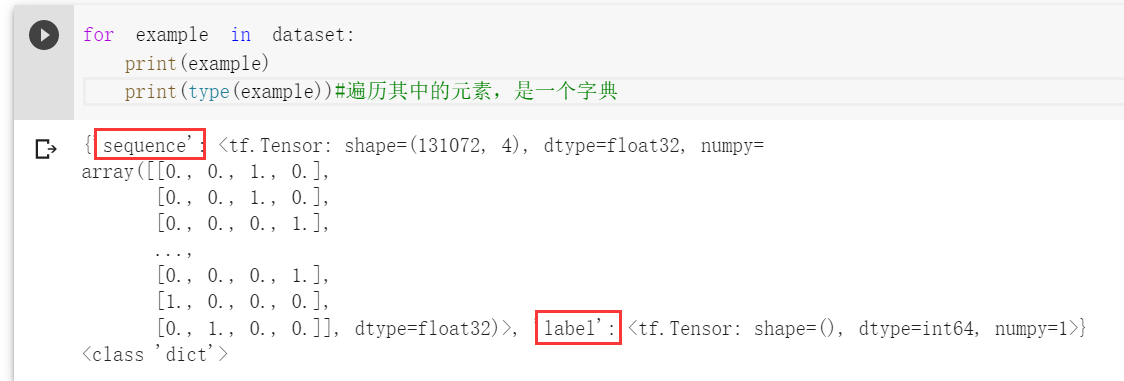
这个字典有两个键sequence和lable,对应着序列矩阵和标签值

这就是可以用来训练的数据。
到此这篇关于Python实现将DNA序列存储为tfr文件并读取流程介绍的文章就介绍到这了,更多相关Python存储tfr文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python神经网络tfrecords文件的写入读取及内容解析
目录 学习前言 tfrecords格式是什么 tfrecords的写入 tfrecords的读取 测试代码 1.tfrecords文件的写入 2.tfrecords文件的读取 学习前言 前一段时间对SSD预测与训练的整体框架有了一定的了解,但是对其中很多细节还是把握的不清楚.今天我决定好好了解以下tfrecords文件的构造. tfrecords格式是什么 tfrecords是一种二进制编码的文件格式,tensorflow专用.能将任意数据转换为tfrecords.更好的利用内存,更方便复制和移
-

Python实现将DNA序列存储为tfr文件并读取流程介绍
最近导师让我跑模型,生物信息方向的,我一个学计算机的,好多东西都看不明白.现在的方向大致是,用深度学习的模型预测病毒感染人类的风险. 既然是病毒,就需要拿到它的DNA,也就是碱基序列,然后把这些ACGT序列丢进模型里面,然后就是预测能不能感染人类,说实话,估计结果不会好,现在啥都是transformer,而且我看的这篇论文,我认为仅仅从DNA序列大概预测不出什么东西. 但是就那样吧,现在数据去哪里下载,需要下载什么样的数据,下载完成后怎么处理我还是一脸懵逼,但是假设上面都处理好了,然后即使把数据
-
Python数据结构之图的存储结构详解
一.图的定义 图是一种比树更复杂的一种数据结构,在图结构中,结点之间的关系是任意的,任意两个元素之间都可能相关,因此,它的应用极广.图中的数据元素通常被称为顶点 ( V e r t e x ) (Vertex) (Vertex), V V V是顶点的有穷非空集合, V R VR VR是两个顶点之间的关系的集合(可以为空),可以表示为图 G = { V , { V R } } G=\{V,\{VR\}\} G={V,{VR}}. 二.相关术语 2.1 无向图 给定图 G = { V , { E }
-
Python for循环通过序列索引迭代过程解析
这篇文章主要介绍了Python for循环通过序列索引迭代过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python for 循环通过序列索引迭代: 注:集合 和 字典 不可以通过索引进行获取元素,因为集合和字典都是无序的. 使用 len (参数) 方法可以获取到遍历对象的长度. 程序: strs = "Hello World." # 使用 len 方法可以获取到遍历对象的长度. print(len(strs)) # 12
-
Python实现删除windows下的长路径文件
目录 1.文章背景 2.使用 python 删除文件 3.文件系统关于长路径文件的相关定义 4.改造 python 程序,删除长路径文件 5.总结思考 1.文章背景 近期,笔者所在公司的某业务系统的存储临近极限,服务器马上就要跑不动了,由于该业务系统A包含多个子系统A1.A2.A3 ... An,这些子系统的中间存储文件由于设计原因,都存储在同一个父级目录之内,唯一不同的是,不同子系统产生的文件和文件夹的名字都以该子系统名开始.如A1子系统产生的文件命名方式均为A1xxxxxx, A2子系统产生
-
使用python scrapy爬取天气并导出csv文件
目录 爬取xxx天气 安装 创建scray爬虫项目 文件说明 开始爬虫 补充:scrapy导出csv时字段的一些问题 1.字段顺序问题: 2.输出csv有空行的问题 总结 爬取xxx天气 爬取网址:https://tianqi.2345.com/today-60038.htm 安装 pip install scrapy 我使用的版本是scrapy 2.5 创建scray爬虫项目 在命令行如下输入命令 scrapy startproject name name为项目名称如,scrapy start
-
Python实现暴力破解有密码的zip文件的方法
背景 今天朋友给我发了一个某游戏的兑换码,压缩文件发过来的.结果被加密了.wc?还说叫爸爸就给我密码?男人是这么容易像恶势力低头的?直接给你爆了好吧,小兔崽子. 一.思路 爆密码的思路其实都大同小异:无非就是字典爆破,就看你是有现成密码字典,还是自己生成密码字典,然后进行循环输入密码,直到输入正确位置.现在很多都有防爆破限制,根本无法进行暴力破解,但是似乎zip这种大家都是用比较简单的密码而且没有什么限制. 因此 实现思路就是 生成字典->输入密码->成功解压 二.实现过程 1.生成字典 生成
-
Python提取PDF指定内容并生成新文件
在之前的Python办公自动化案专题中,我们已经介绍了如何有选择的提取某些页面进行合并. 但是很多时候,我们并不会预知希望提取的页号,而是希望将包含指定内容的页面提取合并为新PDF,本文就以两个真实需求为例进行讲解. 01需求描述 数据是一份有286页的上市公司公开年报PDF,大致如下 现在需要利用 Python 完成以下两个需求 " 需求一:提取所有包含 战略 二字的页面并合并新PDF 需求二:提取所有包含图片的页面,并分别保存为 PDF 文件 " 02前置知识和逻辑梳理 2.1 P
-
Python爬取csnd文章并转为PDF文件
目录 1.导入模块 2.创建文件夹 3.发送请求 4.数据解析 5.如果把列表里面每一个元素 都提取出来 6.替换特殊字符 7.转换成PDF文件 本篇文章流程(爬虫基本思路): 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 确定需求(要爬取的内容是什么?)爬取CSDN文章内容 保存pdf 通过开发者工具进行抓包分析 分析数据从哪里来的? 代码实现过程: 发送请求 对于文章列表页面发送请求 获取数据 获取网页源代码 解析数据 文章的url 以及 文章标题 发送请求 对于文章详情
-
python logging多进程多线程输出到同一个日志文件的实战案例
参考官方案例:https://docs.python.org/zh-cn/3.8/howto/logging-cookbook.html import logging import logging.config import logging.handlers from multiprocessing import Process, Queue import random import threading import time def logger_thread(q): while True:
-
Python使用xlrd和xlwt批量读写excel文件的示例代码
一.使用xlrd对excel进行数据读取 excel表格示例: 安装xlrd库 pip install xlrd 导入xlrd库 import xlrd 读取excel文件,即刚刚创建的excel表格 # 给出excel文件绝对路径 loc = ("path of file") # 打开工作表 wb = xlrd.open_workbook(loc) # 这里读取的是第一个sheet sheet = wb.sheet_by_index(0) 打印excel表格第一行第一列 >&g