go按行读取文件的三种实现方式汇总
目录
- 1. 使用ioutil读取文本
- 2. 使用bufio.Reader的ReadLine读取
- 3.使用bufio.Scanner读取
- 总结
1. 使用ioutil读取文本
// 全部读取后按换行拆分
func ReadFile1(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
readBytes, err := ioutil.ReadAll(fileHanle)
if err != nil {
return err
}
results := strings.Split(string(readBytes), "\n")
fmt.Printf("read result:%v", results)
return nil
}
实现方式:使用iouitl一次性读取全部文件内容,然后使用"\n"进行分割成行。
这种实现最简单,但是只适合都内容比较小的文件,当读取大文件的时候,一次读到内存需要占用比较大的内存。
2. 使用bufio.Reader的ReadLine读取
func ReadFile2(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
reader := bufio.NewReader(fileHanle)
var results []string
// 按行处理txt
for {
line, _, err := reader.ReadLine()
if err == io.EOF {
break
}
results = append(results, string(line))
}
fmt.Printf("read result:%v\n", results)
return nil
}
实现方式:使用NewReader创建bufio.Reader,循环调用Reader的ReadLine按行读取,直接读到文件结束标记EOF。
bufio.Reader封装了io, 并实现了缓冲I/O,同时它也实现了io.Reader的方法的Read方法。bufio缓冲区有默认大小是4K。
从ReadLine返回的文本不包括行尾(“\r\n”或“\n”)。
如果一行大于缓存,isPrefix 会被设置为 true,同时返回该行的开始部分(等于缓存大小的部分)。该行剩余的部分就会在下次调用的时候返回。当下次调用返回该行剩余部分时,isPrefix 将会是 false 。
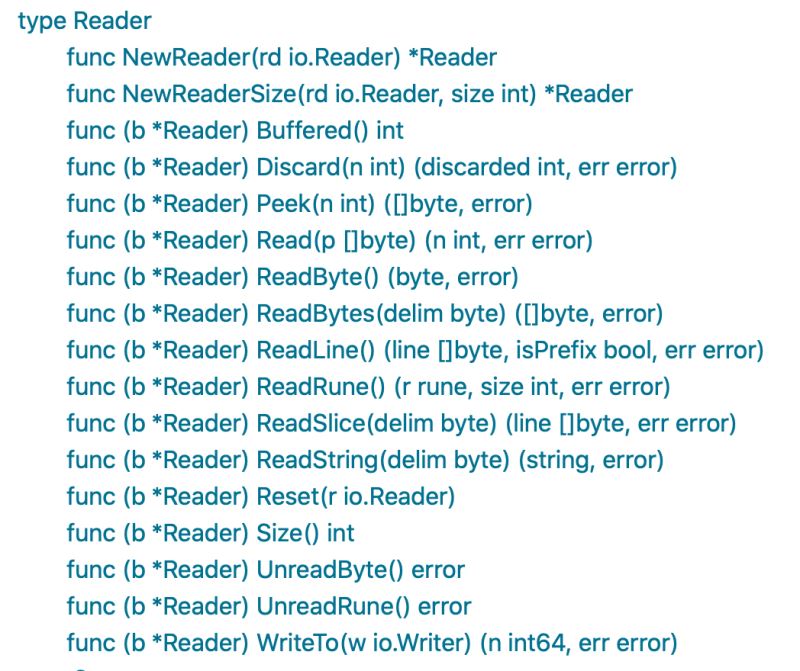
bufio.Reader的ReadLine最终调用的是ReadSlice方法,而ReadSlice返回的[]byte是指向Reader 中的buffer的一个slice,而不是copy一份返回,所以读取的slice可能会被一下读取操作重新,所以官方建议是使用ReadBytes和ReadString方法。
要注意是ReadBytes和ReadString返回的结果中包含传入的界定符,如果最终结果不需要界定符的话需要自己处理。
bufio.Reader除了有ReadLine按行读取外,他还封装了按指定标记分割的方法。如下图
3.使用bufio.Scanner读取
func ReadFile3(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
scanner := bufio.NewScanner(fileHanle)
var results []string
// 按行处理txt
for scanner.Scan(){
lineTxt := strings.TrimSpace(scanner.Text())
if len(lineTxt) == 0 {
continue
}
results = append(results, lineTxt)
}
fmt.Printf("read result:%v\n", results)
return nil
}
实现方式:使用NewScanner创建bufio.Scanner,使用循环调用scanner的Scan判断是否扫描到数据,然后通过scannner.Text()方法获取到扫描的字符串。
bufio.Scanner它底层封装了io.Reader, 它的实现就跟Scanner名称一样,是一个按字节流扫描的扫描器,当扫描到满足Split函数条件的字节数据后,就直接返回对应的扫描到的内容。
默认情况下,它64k行限制,如果想更大,可以自己通过Buffer函数进行设置。
Scanner默认提供了以下方法:

Scanner 类型具有 Split 函数,该函数接受 SplitFunc 函数来确定 Scanner 如何拆分给定的字节片。默认的 SplitFunc 是 ScanLines,它将返回文本的每一行,并删除行尾标记。Split的函数定义如下:
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error)
我们可以自定义实现SpiteFunc来实现不同的拆分方式,比如我们可以使用bufio.ScanWords实现方式来按单词拆分,如下:
func WordCounter(){
const input = "Now is the winter of our discontent,\nMade glorious summer by this sun of York.\n"
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(bufio.ScanWords)
count := 0
for scanner.Scan() {
count++
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading input:", err)
}
fmt.Printf("%d\n", count)
}
我可以跟踪到bufio包scan.go的文件可以看到ScanWords的实现代码如下:
func ScanWords(data []byte, atEOF bool) (advance int, token []byte, err error) {
// Skip leading spaces.
start := 0
for width := 0; start < len(data); start += width {
var r rune
r, width = utf8.DecodeRune(data[start:])
if !isSpace(r) {
break
}
}
// Scan until space, marking end of word.
for width, i := 0, start; i < len(data); i += width {
var r rune
r, width = utf8.DecodeRune(data[i:])
if isSpace(r) {
return i + width, data[start:i], nil
}
}
// If we're at EOF, we have a final, non-empty, non-terminated word. Return it.
if atEOF && len(data) > start {
return len(data), data[start:], nil
}
// Request more data.
return start, nil, nil
}
该函数签名和SplitFunc定义实现一致。
总结
到此这篇关于go按行读取文件的三种实现方式的文章就介绍到这了,更多相关go按行读取文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈Golang是如何读取文件内容的(7种)
本文旨在快速介绍Go标准库中读取文件的许多选项. 在Go中(就此而言,大多数底层语言和某些动态语言(如Node))返回字节流. 不将所有内容自动转换为字符串的好处是,其中之一是避免昂贵的字符串分配,这会增加GC压力. 为了使本文更加简单,我将使用string(arrayOfBytes)将bytes数组转换为字符串. 但是,在发布生产代码时,不应将其作为一般建议. 1.读取整个文件到内存中 首先,标准库提供了多种功能和实用程序来读取文件数据.我们将从os软件包中提供的基本情况开始.这意味着两个先决
-
GO语言常用的文件读取方式
本文实例讲述了GO语言常用的文件读取方式.分享给大家供大家参考.具体分析如下: Golang 的文件读取方法很多,刚上手时不知道怎么选择,所以贴在此处便后速查. 一次性读取 小文件推荐一次性读取,这样程序更简单,而且速度最快. 复制代码 代码如下: func ReadAll(filePth string) ([]byte, error) { f, err := os.Open(filePth) if err != nil { return nil, err } return iouti
-

GoLang读取文件的10种方法实例
目录 一. 整个文件读入内存 1.直接指定文化名读取 1.1使用os.ReadFile函数读取文件 2.先创建句柄再读取 2.1使用os.OpenFile函数只读形式获取句柄 2.2代码讲解 二.每次只读取一行 1.使用bufio.Reader结构体的ReadBytes方法读取字节数 2.使用bufio.Reader结构体的ReadString方法读取字符串 3.代码讲解 3.1bufio.Reader结构体 三.每次只读取固定字节数 1.使用os库 2.使用 syscall库 总结 一. 整个
-
go语言读取csv文件并输出的方法
本文实例讲述了go语言读取csv文件并输出的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: package main import ( "encoding/csv" "fmt" "io" "os" ) func main() { file, err := os.Open("names.txt") if err != nil {
-
golang逐行读取文件的操作
我就废话不多说了,大家还是直接看代码吧~ func ReadLine(fileName string) ([]string,error){ f, err := os.Open(fileName) if err != nil { return nil,err } buf := bufio.NewReader(f) var result []string for { line, err := buf.ReadString('\n') line = strings.TrimSpace(line) if
-
Go语言文件读取的一些总结
Go语言在进行文件操作的时候,可以有多种方法.最常见的比如直接对文件本身进行Read和Write: 除此之外,还可以使用bufio库的流式处理以及分片式处理:如果文件较小,使用ioutil也不失为一种方法. 面对这么多的文件处理的方式,那么初学者可能就会有困惑:我到底该用那种?它们之间有什么区别?笔者试着从文件读取来对go语言的几种文件处理方式进行分析. os.File.bufio.ioutil比较 效率测试 文件的读取效率是所有开发者都会关心的话题,尤其是当文件特别大的时候.为了尽可能的展示这
-
golang读取文件的常用方法总结
使用go语言读取文件的各种方式整理. 一次性加载到内存中 // * 整个文件读到内存,适用于文件较小的情况 //每次读取固定字节 //问题容易出现乱码,因为中文和中文符号不占一个字符 func readAllIntoMemory(filename string) (content []byte, err error) { fp, err := os.Open(filename) // 获取文件指针 if err != nil { return nil, err } defer fp.Close(
-
Golang 实现超大文件读取的两种方法
Golang超大文件读取的两个方案 流处理方式 分片处理 去年的面试中我被问到超大文件你怎么处理,这个问题确实当时没多想,回来之后仔细研究和讨论了下这个问题,对大文件读取做了一个分析 比如我们有一个log文件,运行了几年,有100G之大.按照我们之前的操作可能代码会这样写: func ReadFile(filePath string) []byte{ content, err := ioutil.ReadFile(filePath) if err != nil { log.Println("Re
-
go按行读取文件的三种实现方式汇总
目录 1. 使用ioutil读取文本 2. 使用bufio.Reader的ReadLine读取 3.使用bufio.Scanner读取 总结 1. 使用ioutil读取文本 // 全部读取后按换行拆分 func ReadFile1(path string) error { fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666) if err != nil { return err } defer fileHanle.Close() readBy
-
SpringMVC上传文件的三种实现方式
SpringMVC上传文件的三种实现方式,直接上代码吧,大伙一看便知 前台: <%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.
-
shell按行读取文件的3种方法
方法有很多,下面写出三种方法:写法一: 复制代码 代码如下: #!/bin/bashwhile read linedoecho $linedone < filename(待读取的文件) 写法二: 复制代码 代码如下: #!/bin/bashcat filename(待读取的文件) | while read linedoecho $linedone 写法三: 复制代码 代码如下: for line in `cat filename(待读取的文件)`doecho $linedone 说明:for逐行
-
C#读取XML的三种实现方式
前言 XML文件是一种常用的文件格式,例如WinForm里面的app.config以及Web程序中的web.config文件,还有许多重要的场所都有它的身影.(类似还有Json)微软也提供了一系列类库来倒帮助我们在应用程序中存储XML文件 在程序中访问进而操作XML文件一般有两种模型: DOM(文档对象模型):使用DOM的好处在于它允许编辑和更新XML文档,可以随机访问文档中的数据,可以使用XPath查询,但是,DOM的缺点在于它需要一次性的加载整个文档到内存中,对于大型的文档,这会造成资源问题
-
Go读取文件与写入文件的三种方法操作指南
目录 文件写入操作 Write和WriteString写入操作 使用buffio内置包来读文件 第三种写入文件方法:ioutil.WriteFile 总结 打开和关闭文件操作: os.Open()函数能够打开一个文件,返回一个*File和一个err.对得到的文件实例调用close()方法能够关闭文件. package main import ( "fmt" "os" ) //文件操作 func main(){ //打开文件 file, err := os.Open(
-
PHP按行读取文件时删除换行符的3种方法
PHP按行读取文件 去掉换行符"\n": 第一种: 复制代码 代码如下: $content=str_replace("\n","",$content);echo $content; 或者: 复制代码 代码如下: $content=str_replace(array("\n","\r"),"",$content); 第二种: 复制代码 代码如下: $content=preg_replace
-
Python读取文件的四种方式的实例详解
目录 学生数量特别少的情况 停车场空间不够时怎么办? 怎么加快执行效率? 怎么加快处理速度? 结语 故事背景:最近在处理Wikipedia的数据时发现由于数据量过大,之前的文件读取和数据处理方法几乎不可用,或耗时非常久.今天学校安排统一核酸检查,刚好和文件读取的过程非常相似.正好借此机会和大家一起从头梳理一下几种文件读取方法. 故事设定:现在学校要求对所有同学进行核酸采集,每位同学先在宿舍内等候防护人员(以下简称“大白”)叫号,叫到自己时去停车场排队等候大白对自己进行采集,采集完之后的样本由大白
-
C++读取文件的四种方式总结
C++可以根据不同的目的来选取文件的读取方式,目前为止学习了C++中的四种文件读取方式. C++文件读取的一般步骤: 1.包含头文件 #include<fstream> 2.创建流对象:ifstream ifs(这里的ifs是自己起的流对象名字) 3.打开文件:file.open("文件路径","打开方式"),打开文件后并判断文件是否打开成功,ifs.is_open()是用于判断文件是否打开的语句 4.进行文件读取操作 5.关闭文件 ifs.close(
-
Java文件操作之按行读取文件和遍历目录的方法
按行读取文件 package test; import java.io.*; import java.util.*; public class ReadTest { public static List<String> first_list; public static List<String> second_list; public ReadTest() { first_list = new LinkedList<>(); second_list = new Link