Python中np.random.randint()参数详解及用法实例
目录
- 可实现功能:
- np.random.randint() 根据参数中所指定的范围生成随机 整数。
- 参数
- 一、基础用法
- 二、高级用法
- 总结
可实现功能:
1.随机生成一个整数。
2.随机生成任意范围内的一个整数。
3.随机生成指定长度的整数组
4.随机生成指定长度的任意范围的整数组
5.随机生成指定长度的多维整数组
6.随机生成指定长度的任意范围的多维整数组
np.random.randint() 根据参数中所指定的范围生成随机 整数。
numpy.random.randint(low, high=None, size=None, dtype=int)
参数
1. low: int 生成的数值的最小值(包含),默认为0,可省略。
2. high: int 生成的数值的最打值(不包含)。
3. size: int or tuple of ints 随机数的尺寸, 默认是返回单个,输入 10 返回 10个,输入 (3,4) 返回的是一个 3*4 的二维数组。(可选)。
4. dtype:想要输出的结果类型。默认值为int。(可选,一般用不上)。
一、基础用法
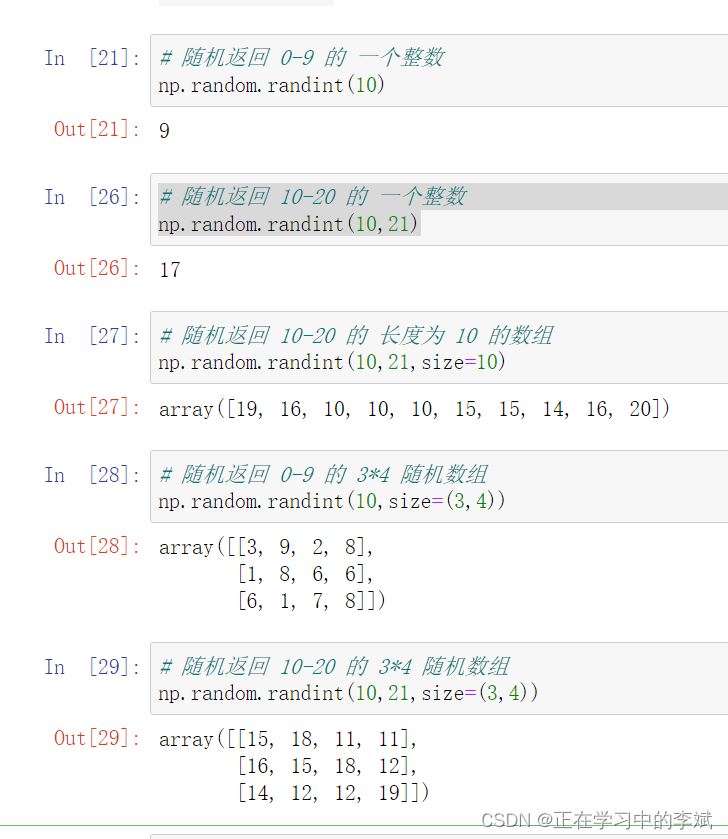
可执行代码
import pandas as pd import numpy as np # 随机返回 0-9 的 一个整数,可的省略0 np.random.randint(10) # 随机返回 10-20 的 一个整数 np.random.randint(10,21) # 随机返回范围在 0-9 的,长度为 10 的数组 np.random.randint(10,size=10) # 随机返回范围在 10-20 的,长度为 10 的数组 np.random.randint(10,21,size=10) # 随机返回范围在 0-9 的 3*4 随机数组 np.random.randint(10,size=(3,4)) # 随机返回范围在 10-20 的 3*4 随机数组 np.random.randint(10,21,size=(3,4))
二、高级用法
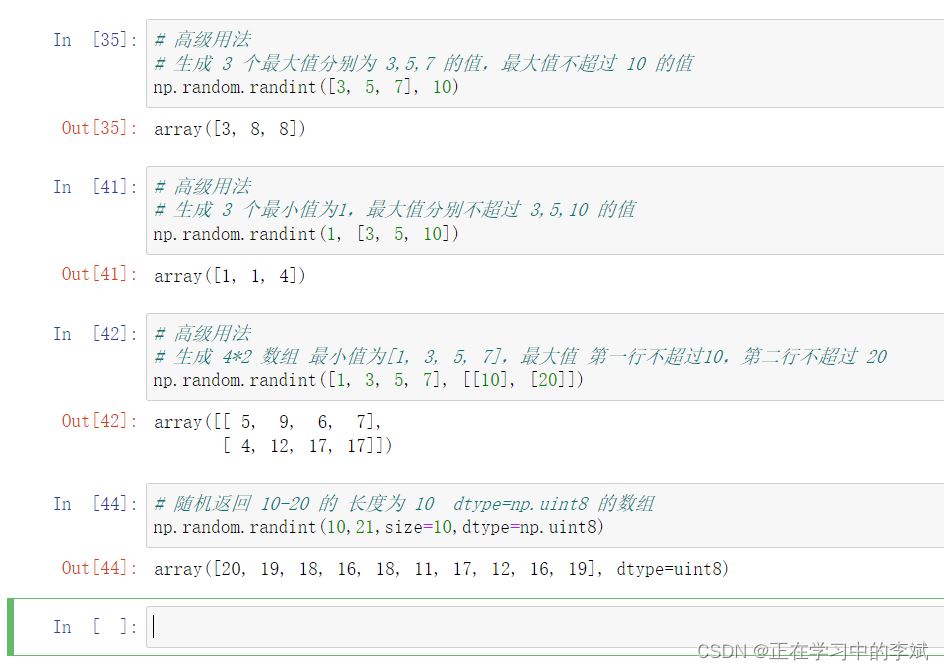
可执行代码
import pandas as pd import numpy as np # 高级用法 # 可单独指定每个元素的最大值 # 生成 3 个最大值分别为 3,5,7 的值,最大值不超过 10 的值 # 如果不指定 size 默认根据第一个和第二个参数的长度来决定生成结果的长度,此处返回的 array 长度是3 np.random.randint([3, 5, 7], 10) # 高级用法 # 生成 3 个最小值为1,最大值分别不超过 3,5,10 的值 np.random.randint(1, [3, 5, 10]) # 高级用法 # 生成 3 个最小值为1,最大值分别不超过 3,5,10 的值 np.random.randint([1, 2, 3,], [4, 5, 10]) # 高级用法 # 生成 4*2 数组 最小值为[1, 3, 5, 7],最大值 第一行不超过10,第二行不超过 20 # 注意第二个参数里面的每个元素都要用[],因为它控制的是一整行 np.random.randint([1, 3, 5, 7], [[10], [20]]) # 高级用法 # 指定返回数据的 dtype # 随机返回 10-20 的 长度为 10 dtype=np.uint8 的数组 np.random.randint(10, 21, size=10, dtype=np.uint8)
总结
到此这篇关于Python中np.random.randint()参数详解及用法的文章就介绍到这了,更多相关Python np.random.randint()用法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

从np.random.normal()到正态分布的拟合操作
先看伟大的高斯分布(Gaussian Distribution)的概率密度函数(probability density function): 对应于numpy中: numpy.random.normal(loc=0.0, scale=1.0, size=None) 参数的意义为: loc:float 此概率分布的均值(对应着整个分布的中心centre) scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高) size:int or tuple
-
np.random.seed() 的使用详解
在学习人工智能时,大量的使用了np.random.seed(),利用随机数种子,使得每次生成的随机数相同. 我们带着2个问题来进行下列实验 np.random.seed()是否一直有效 np.random.seed(Argument)的参数作用? 例子1 import numpy as np if __name__ == '__main__': i = 0 while (i < 6): if (i < 3): np.random.seed(0) print(np.random.randn(1,
-
Python中的np.random.seed()随机数种子问题及解决方法
目录 1. 何为随机数种子 2. np.random.seed()参数问题 3. 使用方法 4. 随机数种子问题总结 前言: 最近在学习过程中总是遇到np.random.seed()这个问题,刚开始总是觉得不过是一个简单的随机数种子,就没太在意,后来遇到的次数多了,才发现他竟然是如此之用处之大!接下来我就把我所学到的关于np.random.seed()的知识分享给大家! 1. 何为随机数种子 随机数种子,相当于我给接下来需要生成的随机数一个初值,按照我给的这个初值,按固定顺序生成随机数.读到这,
-
Numpy中np.random.rand()和np.random.randn() 用法和区别详解
numpy.random.rand(d0, d1, -, dn)的随机样本位于[0, 1)中:本函数可以返回一个或一组服从**"0~1"均匀分布**的随机样本值. numpy.random.randn(d0, d1, -, dn)是从标准正态分布中返回一个或多个样本值. 1. np.random.rand() 语法: np.random.rand(d0,d1,d2--dn) 注:使用方法与np.random.randn()函数相同 作用: 通过本函数可以返回一个或一组服从"0
-
python numpy之np.random的随机数函数使用介绍
np.random的随机数函数(1) 函数 说明 rand(d0,d1,..,dn) 根据d0‐dn创建随机数数组,浮点数, [0,1),均匀分布 randn(d0,d1,..,dn) 根据d0‐dn创建随机数数组,标准正态分布 randint(low[,high,shape]) 根据shape创建随机整数或整数数组,范围是[low, high) seed(s) 随机数种子, s是给定的种子值 np.random.rand import numpy as np a = np.random.ran
-
Python中np.random.randint()参数详解及用法实例
目录 可实现功能: np.random.randint() 根据参数中所指定的范围生成随机 整数. 参数 一.基础用法 二.高级用法 总结 可实现功能: 1.随机生成一个整数. 2.随机生成任意范围内的一个整数. 3.随机生成指定长度的整数组 4.随机生成指定长度的任意范围的整数组 5.随机生成指定长度的多维整数组 6.随机生成指定长度的任意范围的多维整数组 np.random.randint() 根据参数中所指定的范围生成随机 整数. numpy.random.randint(low, hig
-
Java 中String StringBuilder 与 StringBuffer详解及用法实例
在Android/Java开发中,用来处理字符串常用的类有3种: String.StringBuilder.StringBuffer. 它们的异同点: 1) 都是 final 类, 都不允许被继承; 2) String 长度是不可变的, StringBuffer.StringBuilder 长度是可变的; 3) StringBuffer 是线程安全的, StringBuilder 不是线程安全的. String VS StringBuffer String 类型和StringBuffer的主要性
-
python中np.random.permutation函数实例详解
目录 一:函数介绍 二:实例 2.1 直接处理数组或列表数 2.2 间接处理:不改变原数据(对数组下标的处理) 2.3 实例:鸢尾花数据中对鸢尾花的随机打乱(可以直接用) 总结 一:函数介绍 np.random.permutation() 总体来说他是一个随机排列函数,就是将输入的数据进行随机排列,官方文档指出,此函数只能针对一维数据随机排列,对于多维数据只能对第一维度的数据进行随机排列. 简而言之:np.random.permutation函数的作用就是按照给定列表生成一个打乱后的随机列表 在
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python 中Pickle库的使用详解
在"通过简单示例来理解什么是机器学习"这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 那么为什么需要序列化和反序列化这一操作呢? 1.便于存储.序列化过程将文本信息转变为二进制数据流.这样就信息就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据.在Python程序运行中得到了一些字符串.列表.字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据.python模块大全中的Pickle模块就派
-
对python中的高效迭代器函数详解
python中内置的库中有个itertools,可以满足我们在编程中绝大多数需要迭代的场合,当然也可以自己造轮子,但是有现成的好用的轮子不妨也学习一下,看哪个用的顺手~ 首先还是要先import一下: #import itertools from itertools import * #最好使用时用上面那个,不过下面的是为了演示比较 常用的,所以就直接全部导入了 一.无限迭代器: 由于这些都是无限迭代器,因此使用的时候都要设置终止条件,不然会一直运行下去,也就不是我们想要的结果了. 1.coun
-
python中的subprocess.Popen()使用详解
从python2.4版本开始,可以用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值. subprocess意在替代其他几个老的模块或者函数,比如:os.system os.spawn* os.popen* popen2.* commands.* 一.subprocess.Popen subprocess模块定义了一个类: Popen class subprocess.Popen( args, bufsize=0, executable
-
Python中Selenium库使用教程详解
selenium介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 中文参考文档 官网 环境安装 下载安装selenium pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ 谷歌浏览器驱动程序下载地址:
-
python中的map函数语法详解
目录 1map()函数的简介以及语法: 2map()函数实例: 1 map()函数的简介以及语法: map是python内置函数,会根据提供的函数对指定的序列做映射. map()函数的格式是: map(function,iterable,...) 第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合. 把函数依次作用在list中的每一个元素上,得到一个新的list并返回.注意,map不改变原list,而是返回一个新list. 2 map()函数实例: del squa
-
pytorch中dataloader 的sampler 参数详解
目录 1. dataloader() 初始化函数 2. shuffle 与sample 之间的关系 3. sample 的定义方法 3.1 sampler 参数的使用 4. batch 生成过程 1. dataloader() 初始化函数 def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_mem