Cont()与Where().Count()有时性能差别如此之大!
想起我之前在此列表中加入了一个字段,用于方便提示管理员公司的产品列表是否有修改之类的状态字段,于是可以断定是加了此字段的原因。
首先,先看看我之前是如何写这个提示状态字段的,实体中加入ContentStatus,然后直接在Linq语句中Select 实体对象中加入ContentStatus=Product_Maintain.Count(C => C.CompanyID == company.ID && C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4))>0?"产品有更新":""。这时我想应该是加入三元运算,linq在转Sql时,产生过多的,Case,when ,then语句,三元运算增加了判断会影响查询性能,于是我去掉后,再运行查看页面,仍然很慢,感觉不出快了多少。
这时,我想起了LinqPad,看看到底转换生成了怎样的Sql语句。运用Count(条件)生成Sql代码如下:
代码如下:
SELECT COUNT(*) AS [value]
FROM (
SELECT
(CASE
WHEN ([t1].[CompanyID] = ([t0].[ID])) AND ([t1].[IsDeleted] = @p0) AND (([t1].[AuditStatus] = @p1) OR ([t1].[AuditStatus] = @p2)) THEN 1
WHEN NOT (([t1].[CompanyID] = ([t0].[ID])) AND ([t1].[IsDeleted] = @p0) AND (([t1].[AuditStatus] = @p1) OR ([t1].[AuditStatus] = @p2))) THEN 0
ELSE NULL
END) AS [value]
FROM [Company_Product_Maintain] AS [t1]
) AS [t2]
WHERE [t2].[value] = 1
这时我发现一个很简单的Count的Sql 语句,linq转换后变得如此复杂,我直接在sql server中运行此代码,发现查询还是很慢,于是我直接把ContentStatus=Product_Maintain.Where(C => C.CompanyID == company.ID && C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4)).Count()生成Sql语句为:
SELECT COUNT(*) AS [value]
FROM [GasSNS_Company_Equipment_Maintain] AS [t1]
WHERE ([t1].[CompanyID] = ([t0].[ID])) AND ([t1].[IsDeleted] = @p0) AND (([t1].[AuditStatus] = @p1) OR ([t1].[AuditStatus] = @p2))
发现运行速度那是快了一个数量级啊!
后台列表查询结果速度大大提升有图为证(声明:以下图都为项目中截图,不是简单的单表查询,还连了用户表,详细表等数量也都挺大的):
图1为Count结果,用了35秒,哇塞!
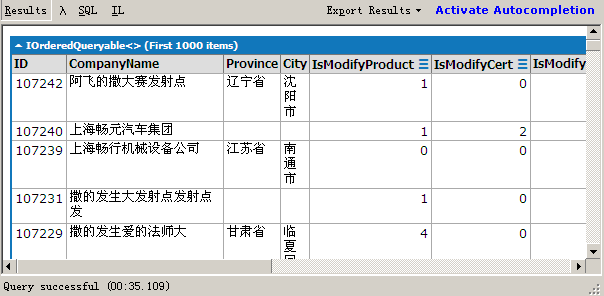
图2为Where(条件).Count()结果,同样的数据只用了4秒钟,差了10倍!
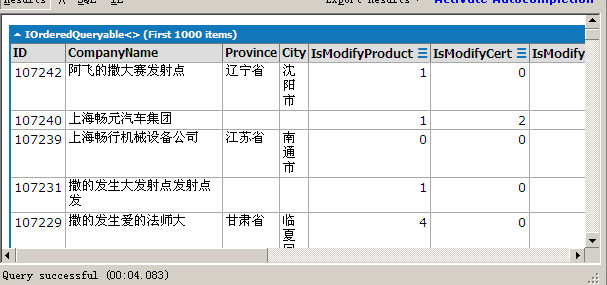
然后为了取值方面我还是加入三元运算,ContentStatus=Product_Maintain.Where(C => C.CompanyID == company.ID && C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4)).Count()>0?"产品有更新":""。结果如下:
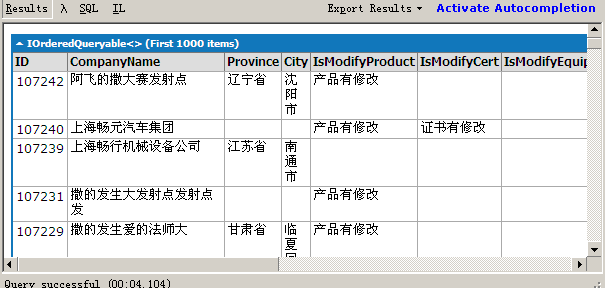
真的是Count()与 Where()区别,不可能这么大差距吧?于是我单写
Product_Maintain.Where(C => C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4)).Count() 与
Product_Maintain.Count(C => C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4))
SELECT COUNT(*) AS [value]
FROM [GasSNS_Company_Equipment_Maintain] AS [t0]
WHERE ([t0].[IsDeleted] = @p0) AND (([t0].[AuditStatus] = @p1) OR ([t0].[AuditStatus] = @p2))
原来是我如果在Select中取某表的数量并且条件中使用了之前from后的某个变量时,这时用Count(条件)和Where(条件).Count()产生代码才会不同,查询速度才会出现数量级的差别。
代码
代码如下:
//效率低版本:
from company in Company
select new
{
contacter = v.ContacterID,
count = Product_Maintain.Count(C => C.CompanyID == company.ID &&C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4))
}
//效率高版本:
from company in Company
select new
{
contacter = v.ContacterID,
count = Product_Maintain.Where(C =>C.CompanyID == company.ID && C.IsDeleted == 0 && (C.AuditStatus == 0 || C.AuditStatus == 4)).Count()
}
否则,Count()与Where().Count()生成的SQL语句是相同的,效率也一样。
总结到此,望各位看官以后要注意!本人入园两年来,第一发在首页,请各位看官不吝赐教!
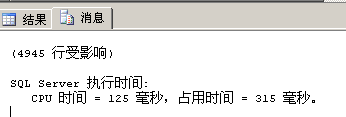
谢谢各位看官的指点,声明下以上查询图都LinqPad查询结果截图。至于为啥4秒左右为LinqPad查询时间,Linq生成Sql语句在Sql Server中执行不到1秒,以下截图作解释:
相关推荐
-

Cont()与Where().Count()有时性能差别如此之大!
想起我之前在此列表中加入了一个字段,用于方便提示管理员公司的产品列表是否有修改之类的状态字段,于是可以断定是加了此字段的原因. 首先,先看看我之前是如何写这个提示状态字段的,实体中加入ContentStatus,然后直接在Linq语句中Select 实体对象中加入ContentStatus=Product_Maintain.Count(C => C.CompanyID == company.ID && C.IsDeleted == 0 && (C.AuditStatu
-
聊聊MySQL的COUNT(*)的性能
前言 基本职场上的程序员用来统计数据库表的行数都会使用count(*),count(1)或者count(主键),那么它们之间的区别和性能你又是否了解呢? 其实程序员在开发的过程中,在一张大表上统计总行数是非常耗时的一个操作,那么我们应该用哪个方法统计会更快呢? 接下来我们就来聊一聊MySQL中统计总行数的方法和性能. count(*),count(1),count(主键)哪个更快? 1.建表并且插入1000万条数据进行实验测试: # 创建测试表 CREATE TABLE `t6` ( `id`
-
5招带你轻松优化MySQL count(*)查询性能
目录 前言 1 count(*)为什么性能差 2 如何优化count(*)性能 2.1 增加redis缓存 2.2 加二级缓存 2.3 多线程执行 2.4 减少join的表 2.5 改成ClickHouse 3 count的各种用法性能对比 前言 最近我在公司优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助. 我们使用的数据库是Mysql8,使用的存储引擎是Innodb.这次优化除了优化索引之外,更多的是在优化count(*). 通常情况下,分页接口一般
-
WEB前端性能优化的7大手段详解
减少请求数量 合并 如果不进行文件合并,有如下3个隐患 1.文件与文件之间有插入的上行请求,增加了N-1个网络延迟 2.受丢包问题影响更严重 3.经过代理服务器时可能会被断开 但是,文件合并本身也有自己的问题 1.首屏渲染问题 2.缓存失效问题 所以,对于文件合并,有如下改进建议 1.公共库合并 2.不同页面单独合并 图片处理 1.雪碧图 CSS雪碧图是以前非常流行的技术,把网站上的一些图片整合到一张单独的图片中,可以减少网站的HTTP请求数量,但是当整合图片比较大时,一次加载比较慢.随着字体图
-
数据库性能优化二:数据库表优化提升性能
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分 优化①:设计规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式 先给大家看一下百度百科给出的定义: 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每
-
SQL SERVER性能优化综述(很好的总结,不要错过哦)第1/3页
一.分析阶段 一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性.可用性.可靠性.安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求.响应时间的需求.硬件的配置等.最好能有各种需求的量化的指标. 另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统). 二.设计阶段 设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎
-
详解Android中通过Intent类实现组件间调用的方法
Intent是Android中用来调用其它组件的类,通过Intent,我们可以非常方便的调用Activity,Broadcast Receiver和Service. Intent intent = new Intent(Intent.ACTION_VIEW); intent.setData(Uri.parse("http://www.baidu.com")); startActivity(intent); 上面这段代码可以用来调用第三方的Activity(启动第三方浏览器来打开百度首页
-
mysql的数据压缩性能对比详情
目录 1. 测试环境 1.1 软硬件 1.2 表结构 2. 测试目的 2.1 压缩空间对比 2.2 查询性能对比 3. 测试工具 3.1 mysqlslap 3.2 测试query 4.测试结论 数据魔方需要的数据,一旦写入就很少或者根本不会更新.这种数据非常适合压缩以降低磁盘占用.MySQL本身提供了两种压缩方式――archive引擎以及针对MyISAM引擎的myisampack方式.今天对这两种方式分别进行了测试,对比了二者在磁盘占用以及查询性能方面各自的优劣.至于为什么做这个,你们应该懂的
-
MySQL性能之count* count1 count列对比示例
目录 正文 count() 性能与啥相关? MVCC 简介 MySQL 对 count() 的优化 查询性能 PK 大起底 count(主键id) count(1) count(字段) count(*) count(1) 和 count(*) 对比 总结 正文 最近的工作中,我听到组内两名研发同学在交流数据统计性能的时候,聊到了以下内容: 数据统计你怎么能用 count(*) 统计数据呢,count(*) 太慢了,要是把数据库搞垮了那不就完了么,赶紧改用 count(1),这样比较快......
-
MySQL COUNT(*)性能原理详解
目录 前言 1.COUNT(1).COUNT(*)与COUNT(字段)哪个更快? 实验分析 实验结果 实验结论 2.COUNT(*)与TABLES_ROWS 3.COUNT(*)是怎么样执行的? 4.总结 前言 在实际开发过程中,统计一个表的数据量是经常遇到的需求,用来统计数据库表的行数都会使用COUNT(*),COUNT(1)或者COUNT(字段),但是表中的记录越来越多,使用COUNT(*)也会变得越来越慢,今天我们就来分析一下COUNT(*)的性能到底如何. 1.COUNT(1).COUN