Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1、需求及配置
需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格。
使用Maven项目,log4j记录日志,日志仅导出到控制台。
Maven依赖如下(pom.xml)
<dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.3</version> </dependency> <dependency> <!-- jsoup HTML parser library @ https://jsoup.org/ --> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency> <!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies>
log4j配置(log4j.properties),将INFO及以上等级信息输出到控制台,不单独设置输出文档。
log4j.rootLogger=INFO, Console #Console log4j.appender.Console=org.apache.log4j.ConsoleAppender log4j.appender.Console.layout=org.apache.log4j.PatternLayout log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析与代码
2.1需求分析
第一步,建立客户端与服务端的连接,并通过URL获得网页上的HTML内容。
第二步,解析HTML内容,获取需要的元素。
第三步,将HTML内容输出到本地的文本文档中,可直接通过其他数据分析软件进行分析。
根据以上分析,建立4个类,GetHTML(用于获取网站HTML), ParseHTML(用于解析HTML), WriteTo(用于输出文档), Maincontrol(主控).下面分别对四个类进行说明。为使代码尽量简洁,所有的异常均从方法上直接抛出,不catch。
2.2代码
2.2.1GetHTML类
该类包含两个方法:getH(String url), urlControl(String baseurl, int page),分别用于获取网页HTML及控制URL。由于此次爬取的网页内容只是京东上某一类商品的搜索结果,所以不需要对页面上所有的URL进行遍历,只需要观察翻页时URL的变化,推出规律即可。只向外暴露urlControl方法,类中设置一个private的log属性:private static Logger log = Logger.getLogger(getHTML.class); 用于记录日志。
getH(String url),对单个URL的HTML内容进行获取。
urlControl(String baseurl, int page),设置循环,访问多个页面的数据。通过审查元素可以看到京东上搜索页page的变化实际是奇数顺序的变化。
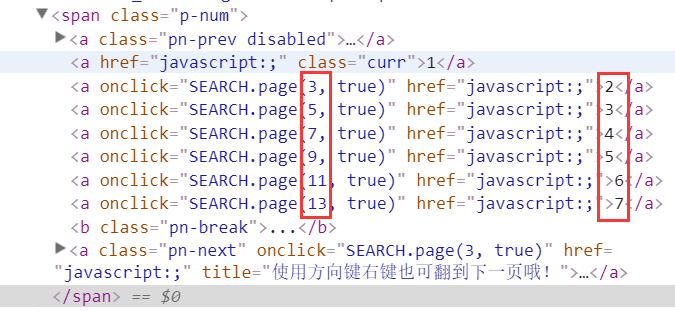
再看一下点击后网址的变化,可以发现实际变化的是page属性的值。通过拼接的方式就可以很的容易的获得下一个网页的地址。
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML类
该步骤需要通过审查元素对需要爬取内容的标签进行确定,再通过Jsoup中的CSS选择器进行获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo类
此类中的方法将解析完成的内容写入到一个本地文件中。只是简单的IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl类
主控程序,写入基地址与想要获取的页面数。调用getHTML类中的urlControl方法对页面进行抓取。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc="
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
爬取20页。
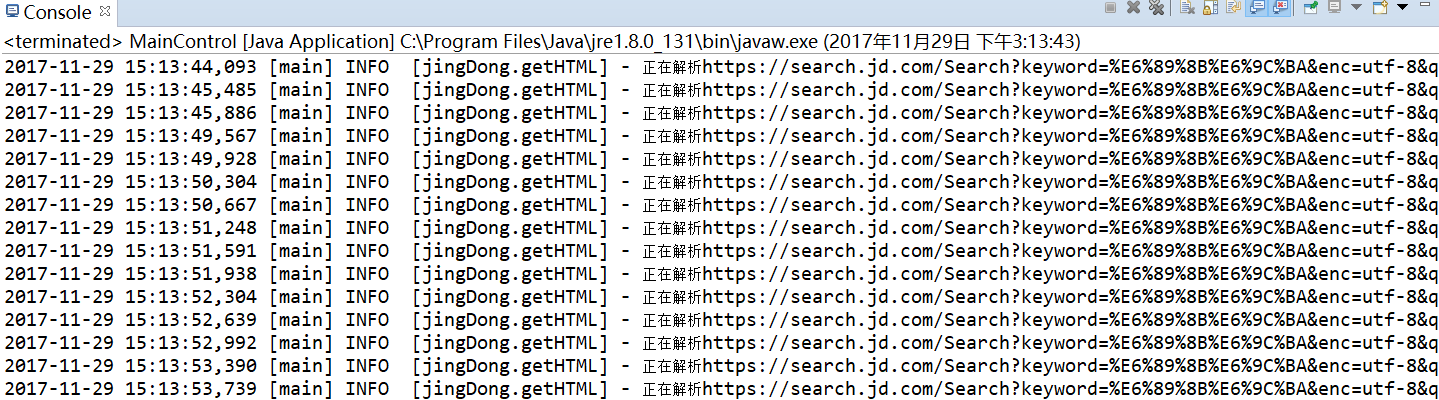
3.1控制台输出
3.2文档输出
可以直接使用Excel打开,分隔符为制表符。列分别为商品编号,名称,价格与评论数。

4、小结
此次爬取使用了HttpClient与Jsoup,可以看到对于简单的需求,这些工具还是非常高效的。实际上也可以把所有类写到一个类当中,写多个类的方式思路比较清晰。
以上这篇Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- 零基础写Java知乎爬虫之抓取知乎答案
- Java爬虫实战抓取一个网站上的全部链接
- java实现简单的爬虫之今日头条
- Java爬虫Jsoup+httpclient获取动态生成的数据
- java实现网页爬虫的示例讲解
相关推荐
-

Java爬虫Jsoup+httpclient获取动态生成的数据
Java爬虫Jsoup+httpclient获取动态生成的数据 前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详解,但是很多时候网站为了防止数据被恶意爬取做了很多遮掩,比如说加密啊动态加载啊,这无形中给我们写的爬虫程序造成了很大的困扰,那么我们如何来突破这个梗获取我们急需的数据呢, 下面我们来详细讲解一下如何获取 String startPage="https://item.jd.com/1147
-
java实现简单的爬虫之今日头条
前言 需要提前说下的是,由于今日头条的文章的特殊性,所以无法直接获取文章的地址,需要获取文章的id然后在拼接成url再访问.下面话不多说了,直接上代码. 示例代码如下 public class Demo2 { public static void main(String[] args) { // 需要爬的网页的文章列表 String url = "http://www.toutiao.com/news_finance/"; //文章详情页的前缀(由于今日头条的文章都是在group这个目
-
Java爬虫实战抓取一个网站上的全部链接
前言:写这篇文章之前,主要是我看了几篇类似的爬虫写法,有的是用的队列来写,感觉不是很直观,还有的只有一个请求然后进行页面解析,根本就没有自动爬起来这也叫爬虫?因此我结合自己的思路写了一下简单的爬虫. 一 算法简介 程序在思路上采用了广度优先算法,对未遍历过的链接逐次发起GET请求,然后对返回来的页面用正则表达式进行解析,取出其中未被发现的新链接,加入集合中,待下一次循环时遍历. 具体实现上使用了Map<String, Boolean>,键值对分别是链接和是否被遍历标志.程序中使用了两个Map集
-
零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下: http://www.zhihu.com/explore/recommendations 但是显然这个页面是无法获取答案的. 一个完整问题的页面应该是这样的链接: http://www.zhihu.com/question/22355264 仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述: import java.util.ArrayList;public class Zhihu { public St
-
java实现网页爬虫的示例讲解
这一篇目的就是在于网页爬虫的实现,对数据的获取,以便分析. 目录: 1.爬虫原理 2.本地文件数据提取及分析 3.单网页数据的读取 4.运用正则表达式完成超连接的连接匹配和提取 5.广度优先遍历,多网页的数据爬取 6.多线程的网页爬取 7.总结 爬虫实现原理 网络爬虫基本技术处理 网络爬虫是数据采集的一种方法,实际项目开发中,通过爬虫做数据采集一般只有以下几种情况: 1) 搜索引擎 2) 竞品调研 3) 舆情监控 4) 市场分析 网络爬虫的整体执行流程: 1) 确定一个(多个)种子网页 2) 进
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
Python爬虫实现爬取京东手机页面的图片(实例代码)
实例如下所示: __author__ = 'Fred Zhao' import requests from bs4 import BeautifulSoup import os from urllib.request import urlretrieve class Picture(): def __init__(self): self.headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleW
-
python 爬虫一键爬取 淘宝天猫宝贝页面主图颜色图和详情图的教程
实例如下所示: import requests import re,sys,os import json import threading import pprint class spider: def __init__(self,sid,name): self.id = sid self.headers = { "Accept":"text/html,application/xhtml+xml,application/xml;", "Accept-Enc
-
Python 3实战爬虫之爬取京东图书的图片详解
前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫. 实现分析 首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面.我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713
-
Java 爬虫如何爬取需要登录的网站
这是 Java 网络爬虫系列博文的第二篇,在上一篇 Java 网络爬虫新手入门详解 中,我们简单的学习了一下如何利用 Java 进行网络爬虫.在这一篇中我们将简单的聊一聊在网络爬虫时,遇到需要登录的网站,我们该怎么办? 在做爬虫时,遇到需要登陆的问题也比较常见,比如写脚本抢票之类的,但凡需要个人信息的都需要登陆,对于这类问题主要有两种解决方式:一种方式是手动设置 cookie ,就是先在网站上面登录,复制登陆后的 cookies ,在爬虫程序中手动设置 HTTP 请求中的 Cookie 属性,这
-
python爬虫实战之爬取京东商城实例教程
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧. 主要工具 scrapy BeautifulSoup requests 分析步骤 1.打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 2.我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
c#爬虫爬取京东的商品信息
前言 在一个小项目中,需要用到京东的所有商品ID,因此就用c#写了个简单的爬虫. 在解析HTML中没有使用正则表达式,而是借助开源项目HtmlAgilityPack解析HTML. 下面话不多说了,来一起看看详细的介绍吧 一.下载网页HTML 首先我们写一个公共方法用来下载网页的HTML. 在写下载HTML方法之前,我们需要去查看京东网页请求头的相关信息,在发送请求时需要用到. public static string DownloadHtml(string url, Encoding encod
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session