TF-IDF与余弦相似性的应用(一) 自动提取关键词
TF-IDF与余弦相似性的应用(一):自动提取关键词
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?

这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。

一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
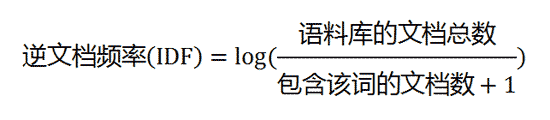
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
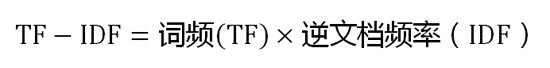
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
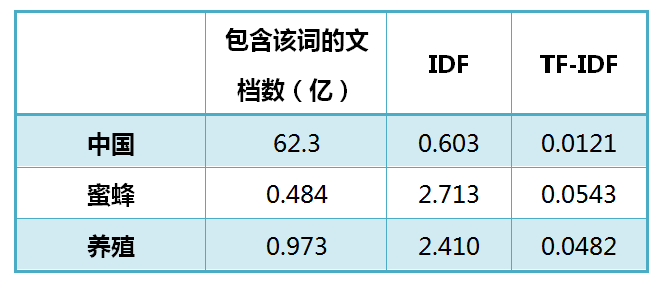
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
下一次,我将用TF-IDF结合余弦相似性,衡量文档之间的相似程度。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

TF-IDF与余弦相似性的应用(二) 找出相似文章
上一次,我用TF-IDF算法自动提取关键词. 今天,我们再来研究另一个相关的问题.有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章.比如,"Google新闻"在主新闻下方,还提供多条相似的新闻. 为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity).下面,我举一个例子来说明,什么是"余弦相似性". 为了简单起见,我们先从句子着手. 句子A:我喜欢看电视,不喜欢看电影. 句子B:我不喜欢看电视,也不喜欢看
-
TF-IDF与余弦相似性的应用(一) 自动提取关键词
TF-IDF与余弦相似性的应用(一):自动提取关键词 这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题. 有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到? 这个问题涉及到数据挖掘.文本处理.信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果.它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法.
-
python代码如何实现余弦相似性计算
这篇文章主要介绍了python代码如何实现余弦相似性计算,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 A:西米喜欢健身 B:超超不爱健身,喜欢打游戏 step1:分词 A:西米/喜欢/健身 B:超超/不/喜欢/健身,喜欢/打/游戏 step2:列出两个句子的并集 西米/喜欢/健身/超超/不/打/游戏 step3:计算词频向量 A:[1,1,1,0,0,0,0] B:[0,1,1,1,1,1,1] step4:计算余弦值 余弦值越大,证明夹角越
-
余弦相似性计算及python代码实现过程解析
A:西米喜欢健身 B:超超不爱健身,喜欢打游戏 step1:分词 A:西米/喜欢/健身 B:超超/不/喜欢/健身,喜欢/打/游戏 step2:列出两个句子的并集 西米/喜欢/健身/超超/不/打/游戏 step3:计算词频向量 A:[1,1,1,0,0,0,0] B:[0,1,1,1,1,1,1] step4:计算余弦值 余弦值越大,证明夹角越小,两个向量越相似. step5:python代码实现 import jieba import jieba.analyse def words2vec(wo
-
.NET下文本相似度算法余弦定理和SimHash浅析及应用实例分析
本文实例讲述了.NET下文本相似度算法余弦定理和SimHash浅析及应用.分享给大家供大家参考.具体分析如下: 余弦相似性 原理:首先我们先把两段文本分词,列出来所有单词,其次我们计算每个词语的词频,最后把词语转换为向量,这样我们就只需要计算两个向量的相似程度. 我们简单表述如下 文本1:我/爱/北京/天安门/ 经过分词求词频得出向量(伪向量) [1,1,1,1] 文本2:我们/都爱/北京/天安门/ 经过分词求词频得出向量(伪向量) [1,0,1,2] 我们可以把它们想象成空
-
python实现余弦相似度文本比较的示例
向量空间模型VSM: VSM的介绍: 一个文档可以由文档中的一系列关键词组成,而VSM则是用这些关键词的向量组成一篇文档,其中的每个分量代表词项在文档中的相对重要性. VSM的例子: 比如说,一个文档有分词和去停用词之后,有N个关键词(或许去重后就有M个关键词),文档关键词相应的表示为(d1,d2,d3,...,dn),而每个关键词都有一个对应的权重(w1,w1,...,wn).对于一篇文档来说,或许所含的关键词项比较少,文档向量化后的向量维度可能不是很大.而对于多个文档(2篇文档或两篇文档以上
-
Java基于余弦方法实现的计算相似度算法示例
本文实例讲述了Java基于余弦方法实现的计算相似度算法.分享给大家供大家参考,具体如下: (1)余弦相似性 通过测量两个向量之间的角的余弦值来度量它们之间的相似性.0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1.从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向.所以,它通常用于文件比较. 相关介绍可参考百度百科:余弦相似性 (2)算法实现的中未使用权重(IDF ---逆文档频率),使用词项的出现次数作为向量空间的值. import java.util.H
-
详解Python 字符串相似性的几种度量方法
字符串的相似性比较应用场合很多,像拼写纠错.文本去重.上下文相似性等. 评价字符串相似度最常见的办法就是:把一个字符串通过插入.删除或替换这样的编辑操作,变成另外一个字符串,所需要的最少编辑次数,这种就是编辑距离(edit distance)度量方法,也称为Levenshtein距离.海明距离是编辑距离的一种特殊情况,只计算等长情况下替换操作的编辑次数,只能应用于两个等长字符串间的距离度量. 其他常用的度量方法还有 Jaccard distance.J-W距离(Jaro–Winkler dist
-
java算法之余弦相似度计算字符串相似率
概述 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据库中.(因为有网站会去引用其它网站新闻,或者把其它网站新闻拿过来稍微改下内容就发布到自己网站中). 解析方案:最终就是采用余弦相似度算法,来计算两个新闻正文的相似度.现在自己写一篇博客总结下. 一.理论知识 先推荐一篇博客,对于余弦相似度算法的理论讲的比较清晰,我们也是按照这个方式来计算相似度的.网址:相似度算法之余弦相
-
python实现TF-IDF算法解析
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术. 同样,理论我这里不再赘述,因为和阮一峰大神早在2013年就将TF-IDF用一种非常通俗的方式讲解出来 TF-IDF与余弦相似性的应用(一):自动提取关键词 材料 1.语料库(已分好词) 2.停用词表(哈工大停用词表) 3.python3.5 语料库的准备 这里使用的语料库是<人民日报>2015年1月16日至1月18日的发表的新闻.并且在进行TFIDF处